H2O学习笔记(八)——Sparkling Water
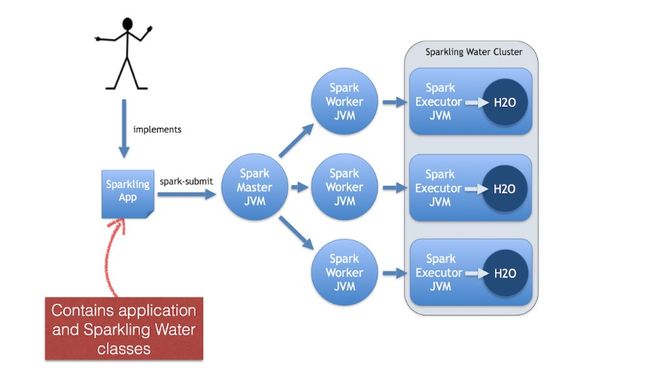
sparkling water将h2o和spark相结合,在spark平台上运行h2o服务。提供了scala,python,R的接口,下面是spark water的一个整体架构图。
安装
这里只简单介绍下PySparkling的安装
首先安装Hadoop和Spark,没有问题了再安装Sparkling Water。
PySparkling支持的一些版本
h2o_pysparkling_1.6 - for Spark 1.6.x
h2o_pysparkling_1.5 - for Spark 1.5.x
h2o_pysparkling_1.4 - for Spark 1.4.x这里我使用了Spark1.60的版本。
1、pip安装一些包
pip install h2o_pysparkling_1.6
pip install requests
pip install tabulate
pip install six
pip install future注:在worker节点上也要安装这些环境,否则会报错。
2、配置环境
export SPARK_HOME="/path/to/spark/installation"
export MASTER='local[*]'3、运行测试
在spark water文件夹下运行shell启动
bin/pysparkling --conf spark.executor.memory=2G 也可以通过ipython和notebook启动
PYSPARK_DRIVER_PYTHON="ipython" PYSPARK_DRIVER_PYTHON_OPTS="notebook" bin/pysparkling启动成功可以在http://master:4040查看pysparkling的状态
测试:
from pysparkling import *
import h2o
hc = H2OContext.getOrCreate(sc)
Demo
1、sparkcontext 初始化的demo
from pysparkling import *
from pyspark import SparkContext
from pyspark.sql import SQLContext
import h2o
# initiate SparkContext
sc = SparkContext("local", "App Name", pyFiles=[])
# initiate SQLContext
sqlContext = SQLContext(sc)
# initiate H2OContext
hc = H2OContext.getOrCreate(sc)
# stop H2O and Spark services
h2o.shutdown(prompt=False)
sc.stop()2、芝加哥犯罪数据
其中用了SparkSQL来查询数据,最后用GBM和DL模型来训练数据
数据集可以从这儿下载
demo
出现的问题
1、spark执行任务时出现java.lang.OutOfMemoryError: GC overhead limit exceeded和java.lang.OutOfMemoryError: java heap space
Sun 官方对此的定义是:“并行/并发回收器在GC回收时间过长时会抛出OutOfMemroyError。”过长的定义是,超过98%的时间用来做GC并且回收了不到2%的堆内存。用来避免内存过小造成应用不能正常工作。
解决方法:
在spark-env.sh中将下面两个参数调大,提高机器可用的堆空间。
export SPARK_EXECUTOR_MEMORY=2000M
export SPARK_DRIVER_MEMORY=2000M另一种可能的原因是executor core数量太多,导致了多个core之间争夺gc时间以及资源(应该主要是内存资源),最后导致大部分的时间都花在了gc上,可以减少core的数量直到到1
SPARK_EXECUTOR_CORES=12、在启动和运行时会出现各种问题,大部分都是虚拟机内存分配不够,虚拟机内存最好分配3G以上,不然会出现各种奇葩的错误。