【GANs学习笔记】(十三)BIGGAN
完整笔记:http://www.gwylab.com/note-gans.html
———————————————————————
原paper及译文:
http://www.gwylab.com/paper-biggan.html
4. BigGAN
4.1 BigGAN解决的问题
我们知道,GANs的终极目标是生成让人无法辨别真伪的高清图片,如果用Inception Score来评价的话,我们希望生成图片的IS得分能逼近真实图片的IS值,也就是233分。但即便是之前效果最好的SAGAN,IS得分也只有52分。于是现在,我们要探索的就是,在好的硬件条件(TPU)和庞大的参数体系下 ,GANs生成的图片究竟能逼真、精细到什么程度,基于这样的好奇心,BigGAN被提出了。
4.2 BigGAN的大规模实现
为了产生逼真、精细的图片,我们需要提升GANs的规模。首先我们想到的,就是增大BatchSize以及增大Chanel,以及我们可以不断尝试修改其他的参数和方法,在后文当中会逐一细述。我们先看一下实验结果(表中的各列内容会在后文一一解释):

Batch(BatchSize)
简单地增大BatchSize就可以实现性能上较好的提升,例如Batch size 从256增大2048的时候,IS 提高了 46%,BigGAN推测这可能是每批次覆盖更多内容的结果,为生成和判别两个网络提供更好的梯度。增大 Batch size 还会带来在更少的时间训练出更好性能的模型,但增大 Batch size 也会使得模型在训练上稳定性下降,4.3节会分析如何提高稳定性。
Ch.(Channel)
在实验上,单单提高 Batch size 还受到限制,BigGAN在每层的通道数也做了相应的增加,当通道增加 50%,大约两倍于两个模型中的参数数量。这会导致 IS 进一步提高 21%。文章认为这是由于模型的容量相对于数据集的复杂性而增加。有趣的是,BigGAN在实验上发现一味地增加网络深度并不会带来更好的结果,反而在生成性能上会有一定的下降。
Shared
首先给出BigGAN生成网络的结构图,顺便能说明什么是Shared(共享嵌入):

如左图所示将噪声向量 z 通过 split 等分成多块,然后和条件标签 c 连接后一起送入到生成网络的各个层中,对于生成网络的每一个残差块又可以进一步展开为右图的结构。可以看到噪声向量 z 的块和条件标签 c 在残差块下是通过 concat 操作后送入 BatchNorm 层,这种嵌入方式就是共享嵌入,线性投影到每个层的 bias 和 weight。共享嵌入与传统嵌入的差别是,传统嵌入为每个嵌入分别设置一个层,而共享嵌入是将z与c的连接一并传入所有BatchNorm。
再回到表1中的实验,BigGAN采用了共享嵌入后,降低了计算和内存成本,并将训练速度(达到给定性能所需的迭代次数)提高了 37%。
Hier.(Hierarchical Latent Space)
先解释一下潜在空间(Latent Space),它实际上指的就是噪声z的先验分布。BigGAN发现,虽然大多数以前的工作采用 N(0,I)或 U[-1,1]作为 z 的先验(输入到 G 的噪声),但实际上我们可以自由选择能够采样的任何潜在分布(详见paper附件E),譬如BigGAN发现效果更好的两个潜在分布是 Bernoulli{0,1}和 Censored Normal max(N(0,I),0),两者都提高了训练速度并轻微提高了最终性能,但是最终BigGAN没有考虑替换潜在分布的方案,因为BigGAN发现了比这更有用的截断技巧。
截断技巧不需要替换潜在空间,我们依然使用N(0,I)的先验分布。截断技巧的做法是:在对先验分布 z 采样的过程中,通过设置阈值的方式来截断 z 的采样,其中超出范围的值被重新采样以落入该范围内。这个阈值可以根据生成质量指标 IS 和 FID 决定。实验的结果是,随着阈值的下降生成的质量会越来越好,但是由于阈值的下降、采样的范围变窄,就会造成生成上取向单一化,造成生成的多样性不足的问题,数据上来说就是,IS (反应图像的生成质量)一路上涨,FID (注重生成的多样性)先变好然后一路变坏。
BigGAN不仅对潜在空间内部作了处理,在潜在空间的处置上用到了分层潜在空间(Hierarchical Latent Space)技术。分层潜在空间的意思是,传统的 GAN 都是将 z 作为输入直接嵌入生成网络,而 BigGAN 将噪声向量 z 送到 G 的多个层而不仅仅是初始层。BigGAN认为潜在空间 z 可以直接影响不同分辨率和层次结构级别的特征,所以对于 BigGAN 的条件生成模型,将 z 分成每个分辨率的一个块,并将每个块连接到条件向量 c 来实现,实验结果证明,这样做提供约 4% 的适度性能提升,并将训练速度提高 18%。
Ortho.(Orthogonal Regularization)
前面我们提到,使用截断技巧可以提升生成图片的质量,但是一些较大的模型不适合截断,因为在嵌入截断噪声时会产生饱和伪影,如下图所示:

为了抵消这种情况,BigGAN通过将 G 调节为平滑来强制实现截断的适应性,以便 z 的整个空间能映射到良好的输出样本。为此,BigGAN采用正交正则化方法(Orthogonal Regularization)。 正交正则化,也就是说让W权重矩阵尽可能是一个正交矩阵,这样最大的好处是,权重系数彼此之间的干扰会非常低,受到截断之后消失的权重就不会对结果产生太大影响。
为了实现正交化,一开始BigGAN想到了一个非常粗俗的方法,就是直接把正则项改为:
![]()
其中 W 是权重矩阵,β 是超参数,I是单位矩阵,这基本上就等价于一个正交矩阵的定义式(若矩阵与自身转置的乘积为单位矩阵,则该矩阵是正交矩阵)。但是这种方法明显太过局限了,BigGAN为了放松约束,同时实现模型所需的平滑度,发现最好的版本是从正则化中删除对角项,并且旨在最小化卷积核之间的成对余弦相似性,但不限制它们的范数:
![]()
实验结果证明,正交正则化的方法是非常有帮助的,在表 1 中,没有正交正则化时,只有 16%的模型适合截断,而有正交正则化训练时则有60%。
4.3 BigGAN的稳定性实现
在前篇中,我们初步实现了BigGAN的大规模,并带来了实质的结果提升。但是,大规模BigGAN有一个最大的问题就是非常不稳定,在Batch很大的时候是非常容易崩溃的。在本节我们首先会分析产生崩溃的原因,然后探讨解决这一问题的方法。
分析崩溃的原因
BigGAN在实验中发现,每个权重矩阵中的前三个奇异值![]() 的影响最大(这三个奇异值可以使用Alrnoldi迭代方法进行有效计算)。我们以
的影响最大(这三个奇异值可以使用Alrnoldi迭代方法进行有效计算)。我们以![]() 为例,我们先画出光谱归一化之前G和D层中第一个奇异值
为例,我们先画出光谱归一化之前G和D层中第一个奇异值![]() 的典型图如下(从红色到紫色的颜色表示增加深度):
的典型图如下(从红色到紫色的颜色表示增加深度):
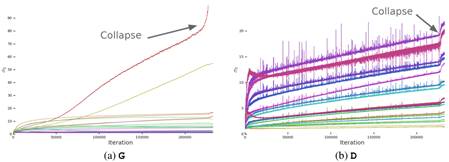
可以看出,左图中大多数G层具有良好的光谱范式,但有些层(通常是G中的第一层,过于完整且非卷积)表现不佳,光谱范式在整个训练过程中增长,在崩溃时爆炸。而对于右图,D的光谱噪声较大,但表现更好。
因此,现在需要解决的问题是,对于G,适当调整奇异值![]() 以抵消光谱爆炸的影响;对于D,寻找更多的约束来抵消噪声的影响,实现训练的稳定性。
以抵消光谱爆炸的影响;对于D,寻找更多的约束来抵消噪声的影响,实现训练的稳定性。
对于G的控制
为了将权重的第一个奇异值![]() 控制住,防止突然性的爆炸,BigGAN采用了两种方法:
控制住,防止突然性的爆炸,BigGAN采用了两种方法:
? 第一种方法是,直接使每个权重的顶部奇异值![]() 正则化,朝向固定值
正则化,朝向固定值![]() 或者以某个比率r朝向第二奇异值
或者以某个比率r朝向第二奇异值![]() (其中
(其中![]() 为停止梯度操作,适时防止正则化增加
为停止梯度操作,适时防止正则化增加![]() )。
)。
? 第二种方法是,使用部分奇异值分解来代替![]() 。给定权重W,其第一个奇异向量
。给定权重W,其第一个奇异向量![]() 和
和![]() ,以及
,以及![]() 将被值
将被值![]() 钳制,我们的权重变为:
钳制,我们的权重变为:
![]()
其中![]() 被设置为
被设置为![]() 或
或![]() 。
。
BigGAN观察到无论有无光谱归一化,这些技术都具有防止![]() 或
或![]() 逐渐增加和爆炸的效果,但即使在某些情况下它们可以温和地提高性能,却依然没有任何组合可以防止训练崩溃。 这一证据表明,虽然调节G可能会改善稳定性,但它不足以确保稳定性。 因此,现在我们需要将注意力转向D。
逐渐增加和爆炸的效果,但即使在某些情况下它们可以温和地提高性能,却依然没有任何组合可以防止训练崩溃。 这一证据表明,虽然调节G可能会改善稳定性,但它不足以确保稳定性。 因此,现在我们需要将注意力转向D。
对于D的控制
在图(b)中,我们看到D的光谱是嘈杂的,但是![]() 表现良好,并且奇异值在整个训练过程中平稳增长,在崩溃时只是突然跳跃而不是爆炸。
表现良好,并且奇异值在整个训练过程中平稳增长,在崩溃时只是突然跳跃而不是爆炸。
我们需要解决的问题有两个,第一个,嘈杂出现的原因是什么以及这种嘈杂与模型不稳定性之间是否有直接影响;第二个,奇异值在整个训练过程中平稳增长(D在训练期间的损失接近于零),但在崩溃时经历了急剧的向上跳跃,这是什么原因导致的。
我们先考虑第一个问题,频谱噪声与模型不稳定性之间有什么样的影响。
我们先分析一下出现嘈杂的原因,D光谱中的峰值可能表明它周期性地接收到非常大的梯度,但我们观察到Frobenius规范是平滑的(见paper附录F),表明这种效应主要集中在前几个奇异方向上。于是我们认为这种噪声是通过对抗训练过程进行优化的结果,其中G定期产生强烈干扰D的batch,进而导致出现光谱嘈杂。
如果这种频谱噪声与不稳定性有因果关系,我们该采用的反制措施自然是梯度惩罚,因为这明显地规范了D的雅可比行列式的变化。BigGAN探索了![]() 零中心梯度罚分:
零中心梯度罚分:
![]()
实验结果证明,在 γ 为 10 的情况下,训练变得稳定并且改善了 G 和 D 中光谱的平滑度和有界性,但是性能严重降低,导致 IS 减少45%。减少惩罚可以部分缓解这种恶化,但会导致频谱越来越不良。即使惩罚强度降低到1(没有发生突然崩溃的最低强度),IS也减少了 20%。
BigGAN还采用了很多其他正则化策略进行比较,得到的结论就是:频谱噪声确实会对模型的不稳定性产生影响,我们可以通过对D施加惩罚去解决。当对D的惩罚足够高时,可以实现训练的稳定性提升但是图像的生成质量会下降比较多。
下面来考虑第二个问题,奇异值在崩溃时的向上跳跃是什么原因导致的。
首先我们直观上猜测,出现这种现象很有可能是D 过度拟合训练集,从而记忆训练样本而不是学习真实图像和生成图像之间的一些有意义的边界,所以在训练D时损失接近0但在崩溃时就会出现突然的跳跃。为了评估这一猜测,BigGAN在 ImageNet 训练和验证集上评估判别器,并测量样本分类为真实或生成的百分比。虽然在训练集下精度始终高于 98%,但验证准确度在 50-55% 的范围内,这并不比随机猜测更好(无论正则化策略如何)。这证实了 D 确实记住了训练集。
但事实上我们不需要对此感到意外,因为这符合 D 的角色:不断提炼训练数据并为 G 提供有用的学习信号。因此针对第二个问题我们不需要做过多的调整,因为D过拟合对模型稳定性影响不大,我们只需要保证G能接受到正确的学习信号即可。
总结
我们发现稳定性不仅仅来自G或D,而是来自他们通过对抗性训练过程的相互作用。 虽然他们的不良症状调节可用于追踪和识别不稳定性,但确保合理的调节是训练所必需的,但不足以防止最终的训练崩溃。可以通过强烈约束D来强制实现稳定性,但这样做会导致性能上的巨大成本。使用现有技术,可以通过放松这种调节并允许在训练的后期阶段发生塌陷来实现更好的最终性能,此时模型经过充分训练以获得良好的结果。
最终的BigGAN,将IS得分提升到了惊人的166分,可以说,BigGAN是迄今为止(截至写稿日18年10月14日)细节效果处理得最好的生成模型,它将GANs的大规模与稳定性实现了较大的提升与平衡,产生让人惊叹的结果。最后用几张BigGAN的生成范例来结束这一章的学习:
