2019大数据挑战赛
文章目录
- 1.前言
- 2.基础知识准备
- 2.1 语义相似度度量
- 2.2 representation based model(表示模型)和 interaction based model(交互模型)
- 2.3 point-wise,pair-wise,list-wise 训练方式
- 2.4 排序常用评价指标
1.前言
2.基础知识准备
对于此次比赛,从本质上讲是计算query与title相似度,而相似度的度量方式一般可以分为如下几种
1.通过tf-idf / bm25 计算每一个word权重值,以权重值作为word的表示,使用欧氏距离或者余弦相似度计算query和title之间的相似度
2.使用word to vector 训练每一个word的向量表示,将query中每一个word的向量表示求平均(或者使用tf-idf做加权平均),然后通过余弦相似度计算query和title之间的相似度
3.使用深度学习的方法,一般在深度学习model中会将label encoding之后的query和title进行embedding操作,得到query和title中每一个word的embedding向量,每一个query和title对应一个embedding矩阵,通过使用不同的特征提取器(CNN,RNN,Transformer)提取特征,然后通过不同的相似度计算方式(MLP距离,余弦相似度,向量按位相乘,neural tensor network等)计算相似度。
在深度学习的方法中又可以细分为两种,即Representation based model 以及 Interaction based model。
其中 representation based model 直接将单文本embedding化,然后直接计算两个向量间的文本相似度。当然为了使得相似度计算更加精细 representation based model 会使用不同粒度的representation,使用单一粒度的句子表示可能还不够精细,分别提取词,短语,句子的表示,然后再计算不同粒度之间的向量相似度来作为文本的匹配度。
interaction based model,即匹配模式,其中心思想就是 对于匹配问题,需要更加精细的建模匹配的过程 ,尽早的让query和title进行交互,然后利用交互后的feature map进行进一步的特征挖掘 。
2.1 语义相似度度量
在这里,首先介绍一下常用的相似度度量方式,一般进行相似度度量可以分为两种情况,第一个为使用统计特征表示每一个word,得到句子表示,然后利用该句子表示进行相似度计算,经典方法为 tf-idf,bm25
tf-idf
原理:为了求word的权重,word在一个文档中出现的次数越多,则说明在该文档中其所占比重越高
因此 tf score:word在文档中出现的次数 / 文档总长度
同时 一个词在所有文档中出现的次数越多 越说明该词不具有特异性,比如一些停用词 ‘的’ 等,
因此 idf score: log(总文档数/包含该词的文档数)
tf - idf score : tf-score * idf-score
BM25
BM25 其实是在计算tf值的时候进行了额外的处理,具体公式比较复杂,自行百度
第二种为使用word to vector 等方法或者深度学习方法将word 稠密化处理,得到每一个word的表示向量,利用向量之间的交互关系计算向量之间的相似度。经典方法为:
欧氏距离
s = ( q − d ) 2 s=\sqrt{ (q-d)^2} s=(q−d)2
Cosine Similarity
s = q T . d q 2 d 2 s=\frac{q^T . d} {\sqrt{ q^2}\sqrt{ d^2}} s=q2d2qT.d
Dot product
s = q T . d s=q^T . d s=qT.d
MLP similarity
s = W 2 ∗ σ ( W 1 ∗ c o n c a t ( q , d ) + b 1 ) + b 2 s= W_2*σ(W_1 * concat(q,d)+b_1)+b_2 s=W2∗σ(W1∗concat(q,d)+b1)+b2
NTN

使用bilinear 结构 其中f表示tanh激活函数,使得词向量之间能够更好的交叉
s = u T f ( q T M i d + V c o n c a t ( q , d ) + b ) s= u ^Tf (q^TM^i d+V concat(q,d)+b) s=uTf(qTMid+Vconcat(q,d)+b)
除此之外经常使用到的方法就是各种度量标准计算结果和原始的tensor表示 concat起来 然后再经过MLP进行计算
例如
将query 和 doc 向量 按位相减之后再相乘
s = M L P ( c o n c a t ( ( q − d ) ⊙ ( q − d ) , q ⊙ d , q , d ) ) s= MLP(concat((q - d) ⊙ (q-d),q⊙d, q, d )) s=MLP(concat((q−d)⊙(q−d),q⊙d,q,d))
补充资料:语义相似度度量
2.2 representation based model(表示模型)和 interaction based model(交互模型)
Representation based model
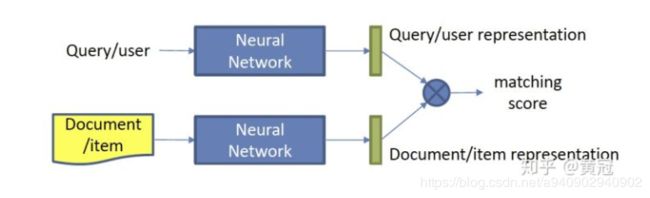
interaction based model

对于representation based model 着重介绍 DSSM ,CNN-DSSM,RNN-DSSM和ABCNN
DSSM
原始的DSSM 和之后的模型最大的不同就是它是使用 letter-trigram的方式编码单词的 以一个trigram的letter组作为编码的最小粒度(当然这是对于英文 对于中文或者label encoding之后的输入 就不能采用这种方式了) 例如 输入candy 会编码成 ca ,can,and,ndy,dy这五个部分,每一个部分都使用一个k维的embedding向量表示,然后将一个query,或者一个title中所有的embedding向量相加,得到一个k维的embedding向量,表示当前query ,同理对于title也做相同的处理,然后query和title分布经过几个全连接层进行特征的提取,最后求得query 向量和title向量的余弦相似度作为他们的相似度打分。


输入: word 经过one hot 编码之后的结果 dim=vocab_size
letter_trigram_encoding: 将word 进行 letter_trigram编码 dim: 1* letter_trigram_num
embedding: 输入 letter_trigram编码的list,对每一个letter_trigram 映射为一个k维embedding
query_embedding_sum:将所有k维embedding求和
之后分别经过若干个全连接层
最后以query和title的余弦相似度作为相关性度量
使用bag of word:
优点:减小了字典大小 提升了对拼写错误的鲁棒性
缺点: 由于使用了词袋模型 对于未知信息缺失
损失函数:
如果对于point-wise方式训练 即输入为双路输入,只有query和title 如果title为正则label为1,为负则label为0
使用log损失作为损失函数
loss=-ylog(score(query,title))-(1-y)log(1-score(query,title))
如果是使用pair-wise 的方式训练 三路输入 输入 query pos title 和neg title ,label均为1
使用rank loss
loss=max(0,-y(score(query,pos_title)-score(query,neg_title)+margin)
由于query和doc 匹配问题 是由word的出现情况 以及word的顺序共同决定的 而DSSM使用的词袋模型忽略了word的顺序信息,因此在DSSM的基础上提出了用来捕捉词序信息
CNN-DSSM
以point-wise DSSM为例
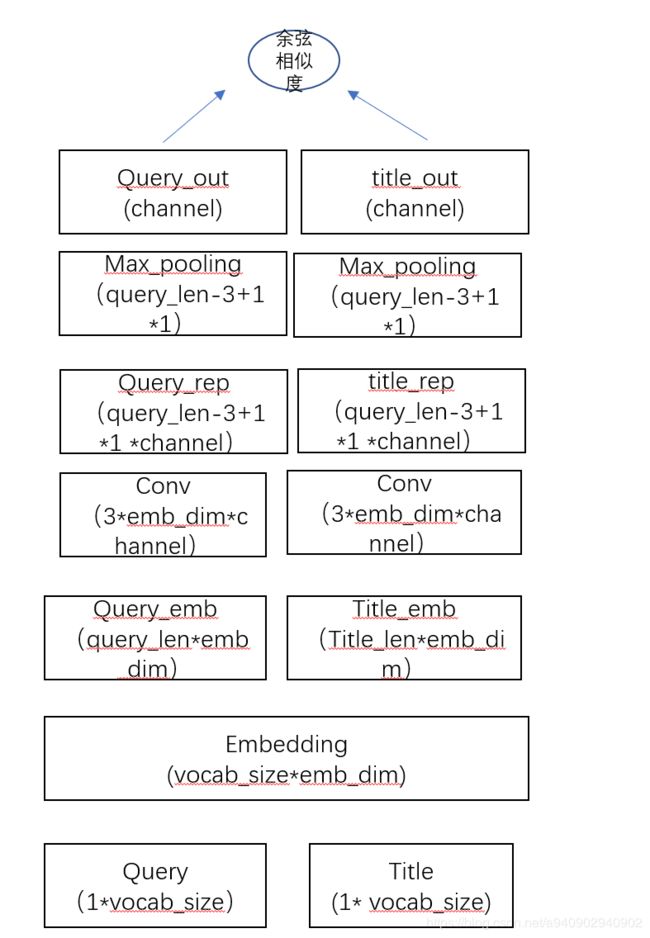
对于输入的句子 :[A,B,C,D] 首先映射成one hot格式 然后经过embedding 每一个word映射成k维向量 得到 query_lenk 矩阵
特征提取层:使用3K *channel的卷积层 分别对query和title进行特征提取 提取局部特征 保持局部特征的位置信息
pooling层:丢弃位置信息 抓取全局中最强的局部信息作为全局表征 ,减少参数 同时通过channel数控制query和title经过pooling之后维度一直(这里max pooling可能损失较多信息 可以使用max-k pooling来替代)
score计算:可以使用余弦相似度 或者2.1中任意方法进行计算
ABCNN
ABCNN中最重要的一点就是引入了Attention机制 ,借由ABCNN来梳理一下在特征提取的时候Attention机制带来的作用
ABCNN 使用Attention的地方可以有两个 第一个就是将原始word embedding之后,使用卷积核进行卷积操作之前,另一种attention是在经过卷积提取特征之后 在average pooling之前进行attention操作
首先 对于第一种Attention进行解析

Attention机制可以理解为一种加权机制,那么权重的确定就是attention最为重要的地方,对于输入的query 和 title 进行embedding,然后将embedding之后的向量进行内积,即 假设输入query为[5,8](query_len,embedding_size) 输入title为[7,8], query和title进行欧式距离得到attention matrix [5,7] 每i 行第j列表示query中第i个词关于title中第j个词的相关性,要以此为依据得到attention feature map,
对于query的attention feature map 可以初始化一个 87矩阵 和Attention matrixT 做内积 Attention matrixT 为7乘5矩阵,第i,j 位置表示title中第i个word 和query中第j个word的相关性 ,所以第i列表示title中所有word和query中第i个word的相关性
使用87矩阵做内积得到8*5矩阵 第i列表示 每一个word应该分配到的相似度,因此得到的attention feature map和原始representation feature map组成2个channel的输入