flink实战--资源分配与并行度(runtime)
简介
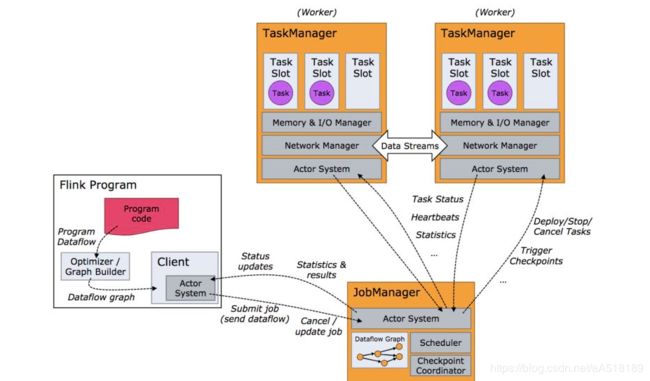
Flink运行时主要角色有两个:JobManager和TaskManager,无论是standalone集群,flink on yarn都是要启动这两个角色。JobManager主要是负责接受客户端的job,调度job,协调checkpoint等。TaskManager执行具体的Task。TaskManager为了对资源进行隔离和增加允许的task数,引入了slot的概念,这个slot对资源的隔离仅仅是对内存进行隔离,策略是均分,比如taskmanager的管理内存是3GB,假如有两个slot,那么每个slot就仅仅有1.5GB内存可用。Client这个角色主要是为job提交做些准备工作,比如构建jobgraph提交到jobmanager,提交完了可以立即退出,当然也可以用client来监控进度。
Jobmanager和TaskManager之间通信类似于Spark 的早期版本,采用的是actor系统。如下图
什么是task?
在spark中:
RDD中的一个分区对应一个task,task是单个分区上最小的处理流程单元。被送到某个Executor上的工作单元,和hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage
上述引入spark的task主要是想带着大家搞明白,以下几个概念:
Flink的并行度由什么决定的?
Flink的task是什么?
Flink的并行度由什么决定的?
这个很简单,Flink每个算子都可以设置并行度,然后就是也可以设置全局并行度。
Api的设置
.map(new RollingAdditionMapper()).setParallelism(10)全局配置在flink-conf.yaml文件中,parallelism.default,默认是1:可以设置默认值大一点

Flink的task是什么?
按理说应该是每个算子的一个并行度实例就是一个subtask-在这里为了区分暂时叫做substask。那么,带来很多问题,由于flink的taskmanager运行task的时候是每个task采用一个单独的线程,这就会带来很多线程切换开销,进而影响吞吐量。为了减轻这种情况,flink进行了优化,也即对subtask进行链式操作,链式操作结束之后得到的task,再作为一个调度执行单元,放到一个线程里执行。如下图的,source/map 两个算子进行了链式;keyby/window/apply有进行了链式,sink单独的一个。
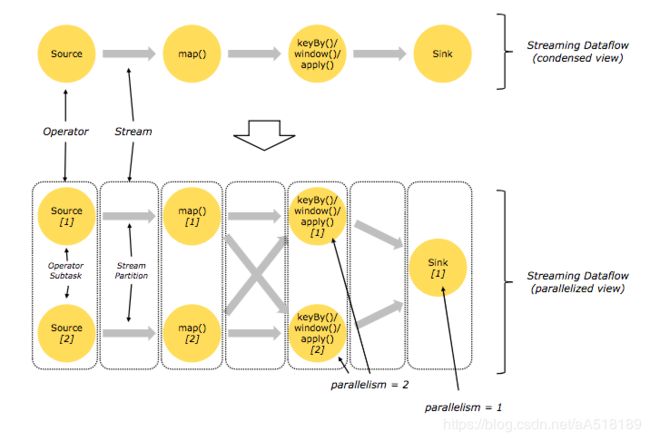
说明:图中假设是source/map的并行度都是2,keyby/window/apply的并行度也都是2,sink的是1,总共task有五个,最终需要五个线程。
默认情况下,flink允许如果任务是不同的task的时候,允许任务共享slot,当然,前提是必须在同一个job内部。
结果就是,每个slot可以执行job的一整个pipeline,如上图。这样做的好处主要有以下几点:
1.Flink 集群所需的taskslots数与job中最高的并行度一致。也就是说我们不需要再去计算一个程序总共会起多少个task了。
2.更容易获得更充分的资源利用。如果没有slot共享,那么非密集型操作source/flatmap就会占用同密集型操作 keyAggregation/sink 一样多的资源。如果有slot共享,将基线的2个并行度增加到6个,能充分利用slot资源,同时保证每个TaskManager能平均分配到重的subtasks,比如keyby/window/apply操作就会均分到申请的所有slot里,这样slot的负载就均衡了。
链式的原则,也即是什么情况下才会对task进行链式操作呢?简单梗概一下:
上下游的并行度一致
下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
上下游节点都在同一个 slot group 中(下面会解释 slot group)
下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
两个节点间数据分区方式是 forward(参考理解数据流的分区)
用户没有禁用 chain
slot和parallelism
slot
是指taskmanager的并发执行能力,在hadoop 1.x 版本中也有slot的概念,有兴趣的读者可以了解一下。

taskmanager.numberOfTaskSlots:3
每一个taskmanager中的分配3个TaskSlot,3个taskmanager一共有9个TaskSlos
slotgroup
为了防止同一个slot包含太多的task,Flink提供了资源组(group)的概念。group就是对operator进行分组,同一group的不同operator task可以共享同一个slot。默认所有operator属于同一个组"default",也就是所有operator task可以共享一个slot。我们可以通过slotSharingGroup()为不同的operator设置不同的group。
dataStream.filter(...).slotSharingGroup("groupName");Flink通过SlotSharingGroup和CoLocationGroup来决定哪些task需要被共享,哪些task需要被单独的slot使用
SlotSharingGroup
表示不同的task可以共享slot,但是这是soft的约束,即也可以不在一个slot
默认情况下,整个StreamGraph都会用一个默认的“default” SlotSharingGroup,即所有的JobVertex的task都可以共用一个slot
2.parallelism是指taskmanager实际使用的并发能力
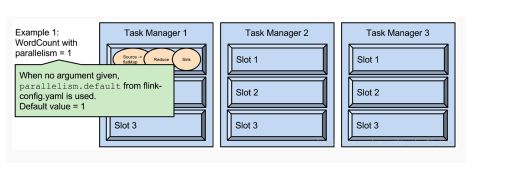
parallelism.default:1
运行程序默认的并行度为1,9个TaskSlot只用了1个,有8个空闲。设置合适的并行度才能提高效率。
3.parallelism是可配置、可指定的
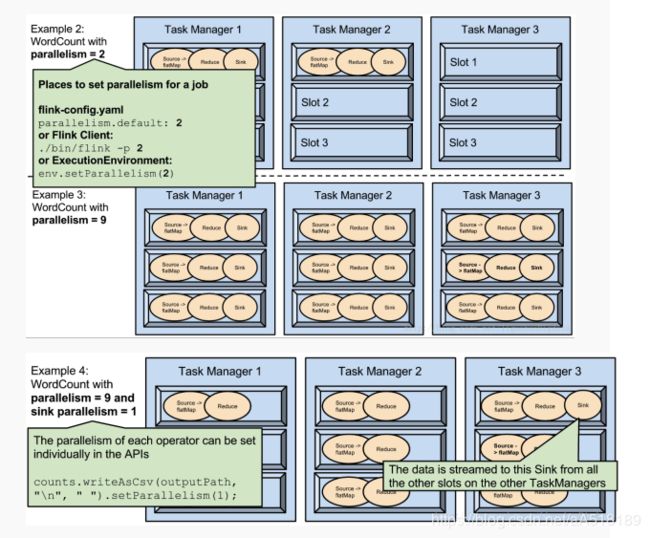
1.可以通过修改$FLINK_HOME/conf/flink-conf.yaml文件的方式更改并行度
2.可以通过设置$FLINK_HOME/bin/flink 的-p参数修改并行度
3.可以通过设置executionEnvironmentk的方法修改并行度
4.可以通过设置flink的编程API修改过并行度
5.这些并行度设置优先级从低到高排序,排序为api>env>p>file.
6.设置合适的并行度,能提高运算效率
7.parallelism不能多与slot个数。
slot和parallelism总结
1.slot是静态的概念,是指taskmanager具有的并发执行能力
2.parallelism是动态的概念,是指程序运行时实际使用的并发能力
3.设置合适的parallelism能提高运算效率,太多了和太少了都不行
4.设置parallelism有多中方式,优先级为api>env>p>file
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
