TensorFlow学习--VGGNet实现&图像识别
VGGNet架构
VGGNet结构
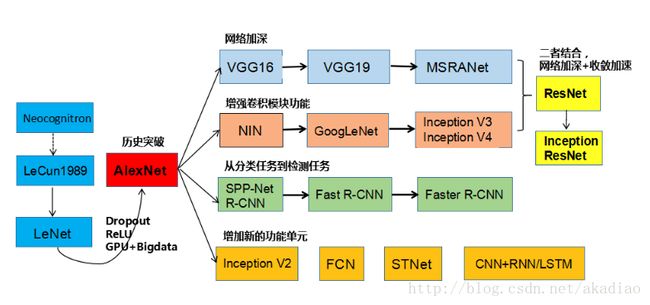
CNN的发展(刘昕博士的《CNN的近期进展与实用技巧》)如图:
VGGNet是由牛津大学计算机视觉组和Google DeepMind公司研发的深度卷积神经网络,通过加深网络结构提升性能.具体来说,VGGNet通过反复堆叠3*3的小卷积核和2*2的最大池化层构造了16-19层深的卷积神经网络.凭借该结构,VGGNet在ILSVRC-2014比赛上取得了分类项目的第2名和定位项目的第1名的成绩.
如图,VGGNet各级别网络结构图:
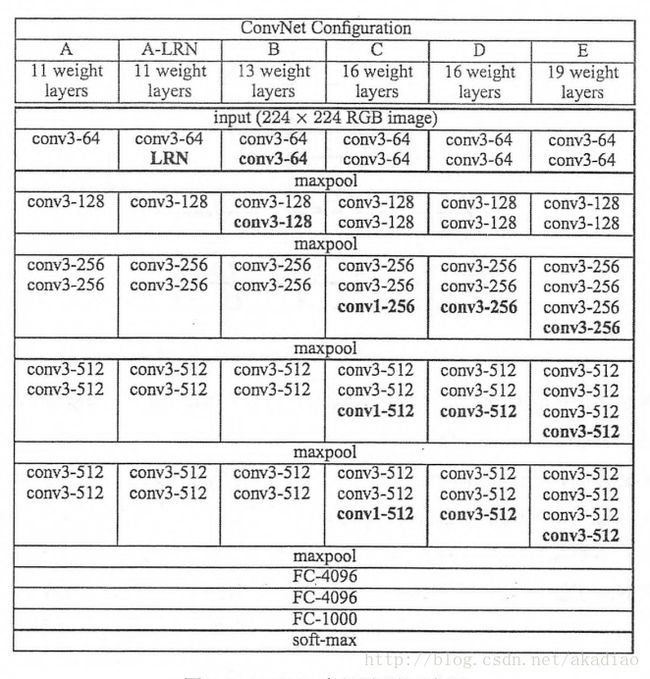
其中,网络D即VGGNet-16,网络E即VGGNet-19.
从A到E每一级网络逐渐变深.由于参数量主要消耗在最后3个全连接层上,所以网络的参数量并未随深度的加深而大量增加.
VGGNet各级别网络参数量,如图:

VGG16的宏观架构
VGG16的宏观架构:

VGGNet有5段卷积,每一段有2-3个卷积层,每段结尾由一个最大池化层来缩小图片尺寸.
每段内的卷积核数量一样,越靠后的段卷积核数量越多: 64→128→256→512→512 .其中2个3*3的卷积层串联相当于1个5*5的卷积层,即感受野大小为5*5,如图:
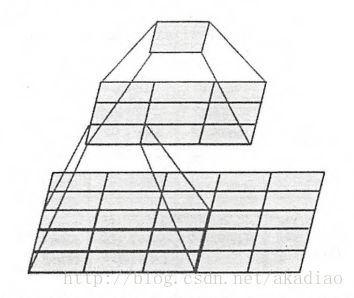
同样,3个3*3的卷积层串联相当于1个7*7的卷积层,但串联后的卷积层会拥有更少的参数量和更多的非线性变换,使得CNN对特征的学习能力更强.
VGG结论
VGG作者对比各级网络时总结出一下观点:
- LRN层作用不大.
- 越深的网络效果越好.
- 1*1的卷积也是很有效的,但没有3*3的卷积好,大一些的卷积核可以学到更大的空间特征.
TensorFlow实现VGGNet-16
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# TensorFlow实现VGGNet-16
from datetime import datetime
import math
import time
import tensorflow as tf
# 卷积层
# kh, kw:卷积核尺寸
# n_out:卷积核输出通道数
# dh, dw:步长
# p:参数列表
def convLayer(x, name, kh, kw, n_out, dh, dw, p):
# 输入数据的通道数
n_in = x.get_shape()[-1].value
# 设置scope
with tf.name_scope(name) as scope:
# 卷积核参数
kernel = tf.get_variable(scope+'w',
shape=[kh, kw, n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
# 卷积处理
conv = tf.nn.conv2d(x, kernel, (1, dh, dw, 1), padding='SAME')
# biases:初始化
bias_init = tf.constant(0.0, shape=[n_out], dtype=tf.float32)
biases = tf.Variable(bias_init, trainable=True, name='b')
# conv + biases
z = tf.nn.bias_add(conv, biases)
activation = tf.nn.relu(z, name=scope)
# 将本层参数kernel和biases存入参数列表
p += [kernel, biases]
return activation
# 全连接层
def fcLayer(x, name, n_out, p):
# 输入x的通道数
n_in = x.get_shape()[-1].value
# 设置scope
with tf.name_scope(name) as scope:
#
kernel = tf.get_variable(scope+'w',
shape=[n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer())
# 将biases初始化一个较小的值以避免dead neuron
biases = tf.Variable(tf.constant(0.1, shape=[n_out], dtype=tf.float32), name='b')
# Relu(x * kernel + biases).
activation = tf.nn.relu_layer(x, kernel, biases, name='b')
# 将本层参数存入参数列表
p += [kernel, biases]
return activation
#
def VGGNet(x, keep_prob):
p = []
# 卷积1 卷积核3*3,数量64,步长1*1
# 输入224*224*3,输出224*224*64
conv1_1 = convLayer(x, name='conv1_1', kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
# 输入224*224*64,输出224*224*64
conv1_2 = convLayer(conv1_1, name='conv1_2', kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
# 池化尺寸2*2,步长2*2
# 输入224*224*64,输出112*112*64
pool1 = tf.nn.max_pool(conv1_2,ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],padding='SAME', name='pool1')
# 卷积2 卷积核3*3,数量128,步长1*1
# 输入112*112*64,输出112*112*128
conv2_1 = convLayer(pool1, name='conv2_1', kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
# 输入112*112*128,输出112*112*128
conv2_2 = convLayer(conv2_1, name='conv2_2', kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
# 池化尺寸2*2,步长2*2
# 输入112*112*128,输出56*56*128
pool2 = tf.nn.max_pool(conv2_2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool2')
# 卷积3 卷积核3*3,数量256,步长1*1
# 输入56*56*128,输出56*56*256
conv3_1 = convLayer(pool2, name='conv3_1', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
# 输入56*56*256,输出56*56*256
conv3_2 = convLayer(conv3_1, name='conv3_2', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
# 输入56*56*256,输出56*56*256
conv3_3 = convLayer(conv3_2, name='conv3_3', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
# 池化尺寸2*2,步长2*2
# 输入56*56*256,输出28*28*256
pool3 = tf.nn.max_pool(conv3_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool3')
# 卷积4 卷积核3*3,数量512,步长1*1
# 输入28*28*256,输出28*28*512
conv4_1 = convLayer(pool3, name='conv4_1', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 输入28*28*512,输出28*28*512
conv4_2 = convLayer(conv4_1, name='conv4_2', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 输入28*28*512,输出28*28*512
conv4_3 = convLayer(conv4_2, name='conv4_3', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 池化尺寸2*2,步长2*2
# 输入28*28*512,输出14*14*512
pool4 = tf.nn.max_pool(conv4_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool4')
# 卷积5 卷积核3*3,数量512,步长1*1
# 输入14*14*512,输出14*14*512
conv5_1 = convLayer(pool4, name='conv5_1', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 输入14*14*512,输出14*14*512
conv5_2 = convLayer(conv5_1, name='conv5_2', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 输入14*14*512,输出14*14*512
conv5_3 = convLayer(conv5_2, name='conv5_3', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 池化尺寸2*2,步长2*2
# 输入14*14*512,输出7*7*512
pool5 = tf.nn.max_pool(conv5_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool5')
shp = pool5.get_shape()
flattened_shape = shp[1].value * shp[2].value * shp[3].value
# 将每个样本化为长度为7*7*512的一维向量
resh1 = tf.reshape(pool5, [-1, flattened_shape], name='resh1')
# 全连接层 FC-4096
fc6 = fcLayer(resh1, name='fc6', n_out=4096, p=p)
# Dropout层训练时节点保留率为0.5
fc6_drop = tf.nn.dropout(fc6, keep_prob, name='fc6_drop')
# 全连接层 FC-4096
fc7_drop = fcLayer(fc6_drop, name='fc7', n_out=4096, p=p)
# 全连接层 FC-1000
fc8 = fcLayer(fc7_drop, name='fc8', n_out=1000, p=p)
softmax = tf.nn.softmax(fc8)
# 求出概率最大的类别
predictions = tf.argmax(softmax, 1)
return predictions, softmax, fc8, p
#
def time_tensorflow_run(session, target, feed, info_string):
num_batches = 100
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target, feed_dict=feed)
# 持续时间
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print '%s: step %d, duration = %.3f' % (datetime.now(), i - num_steps_burn_in, duration)
# 总持续时间
total_duration += duration
# 总持续时间平方和
total_duration_squared += duration * duration
# 计算每轮迭代的平均耗时mn,和标准差sd
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
# 打印出每轮迭代耗时
print '%s: %s across %d steps, %.3f +/- %.3f sec /batch' % (datetime.now(), info_string, num_batches, mn, sd)
#
def run_benchmark():
with tf.Graph().as_default():
batch_size = 32
image_size = 224
# 生成尺寸为224*224的随机图片
images = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size,3],
dtype=tf.float32,
stddev=1e-1))
keep_prob = tf.placeholder(tf.float32)
# 构建VGGNet-16网络
predictions, softmax, fc8, p =VGGNet(images, keep_prob)
# 创建Session并初始化全局参数
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 将keep_prob置为1,进行预测predictions,测评forward运算时间
time_tensorflow_run(sess, predictions, {keep_prob:1.0}, 'Froward')
objective = tf.nn.l2_loss(fc8)
grad = tf.gradients(objective, p)
# 将keep_prob置为0.5,求解梯度操作grad,测评backward运算时间
time_tensorflow_run(sess, grad, {keep_prob:0.5}, 'Forward-backward')
if __name__ == '__main__':
run_benchmark()打印输出:
2017-11-24 09:47:57.623426: step 0, duration = 90.848
2017-11-24 10:00:07.691008: step 10, duration = 61.761
2017-11-24 10:10:50.857570: step 20, duration = 66.089
2017-11-24 10:22:25.293988: step 30, duration = 73.029
2017-11-24 10:34:29.140638: step 40, duration = 70.612
2017-11-24 10:45:46.713019: step 50, duration = 69.431
2017-11-24 10:57:05.660523: step 60, duration = 70.731
2017-11-24 11:08:44.128224: step 70, duration = 71.724
2017-11-24 11:20:48.707626: step 80, duration = 76.572
2017-11-24 11:32:42.663774: step 90, duration = 68.053
2017-11-24 11:42:23.652837: Froward across 100 steps, 7.188 +/- 21.691 sec /batch
2017-11-24 12:08:49.406644: step 0, duration = 101.215
2017-11-24 12:32:49.628456: step 10, duration = 170.579
2017-11-24 12:56:07.453533: step 20, duration = 140.820
2017-11-24 13:34:04.651331: step 30, duration = 208.970
2017-11-24 14:07:06.223686: step 40, duration = 212.811
2017-11-24 14:42:08.806884: step 50, duration = 203.940
2017-11-24 15:16:49.314282: step 60, duration = 206.452
2017-11-24 15:51:43.567262: step 70, duration = 189.478
2017-11-24 16:28:05.278715: step 80, duration = 224.151
2017-11-24 17:00:15.769221: step 90, duration = 184.321
2017-11-24 17:29:12.099079: Forward-backward across 100 steps, 18.427 +/- 56.436 sec /batch利用VGGNet-16图像识别:
利用VGGNet-16图像识别并输出识别结果.
import tensorflow as tf
import numpy as np
from scipy.misc import imread, imresize
from imagenet_classes import class_names
import cv2
# 卷积层
def convLayer(x, name, kh, kw, n_out, dh, dw, p):
# 输入数据的通道数
n_in = x.get_shape()[-1].value
# 设置scope
with tf.name_scope(name) as scope:
# 卷积核参数
kernel = tf.Variable(tf.truncated_normal([kh, kw, n_in, n_out], dtype=tf.float32, stddev=1e-1), name='weights')
# 卷积处理
conv = tf.nn.conv2d(x, kernel, (1, dh, dw, 1), padding='SAME')
# biases:初始化
bias_init = tf.constant(0.0, shape=[n_out], dtype=tf.float32)
biases = tf.Variable(bias_init, trainable=True, name='biases')
# conv + biases
z = tf.nn.bias_add(conv, biases)
activation = tf.nn.relu(z, name=scope)
# 将本层参数kernel和biases存入参数列表
p += [kernel, biases]
return activation, p
class VGGNet16:
def __init__(self, imgs, weights=None, sess=None):
self.imgs = imgs
self.convlayers()
self.fc_layers()
self.probs = tf.nn.softmax(self.fc3l)
if weights is not None and sess is not None:
self.load_weights(weights, sess)
def convlayers(self):
self.parameters = []
# 图像预处理:将RGB图像的像素值的范围设置为0-255,然后减去平均图像值
with tf.name_scope('preprocess') as scope:
mean = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32, shape=[1, 1, 1, 3], name='img_mean')
images = self.imgs-mean
# conv1_1
self.conv1_1, self.parameters =convLayer(images, name='conv1_1',
kh=3, kw=3, n_out=64, dh=1, dw=1, p=self.parameters)
# conv1_2
self.conv1_2, self.parameters =convLayer(self.conv1_1, name='conv1_2',
kh=3, kw=3, n_out=64, dh=1, dw=1, p=self.parameters)
# pool1
self.pool1 = tf.nn.max_pool(self.conv1_2, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME', name='pool1')
# conv2_1
self.conv2_1, self.parameters =convLayer(self.pool1, name='conv2_1',
kh=3, kw=3, n_out=128, dh=1, dw=1, p=self.parameters)
# conv2_2
self.conv2_2, self.parameters =convLayer(self.conv2_1, name='conv2_2',
kh=3, kw=3, n_out=128, dh=1, dw=1, p=self.parameters)
# pool2
self.pool2 = tf.nn.max_pool(self.conv2_2, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME', name='pool2')
# conv3_1
self.conv3_1, self.parameters =convLayer(self.pool2, name='conv3_1',
kh=3, kw=3, n_out=256, dh=1, dw=1, p=self.parameters)
# conv3_2
self.conv3_2, self.parameters =convLayer(self.conv3_1, name='conv3_2',
kh=3, kw=3, n_out=256, dh=1, dw=1, p=self.parameters)
# conv3_3
self.conv3_3, self.parameters =convLayer(self.conv3_2, name='conv3_3',
kh=3, kw=3, n_out=256, dh=1, dw=1, p=self.parameters)
# pool3
self.pool3 = tf.nn.max_pool(self.conv3_3, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],padding='SAME', name='pool3')
# conv4_1
self.conv4_1, self.parameters =convLayer(self.pool3, name='conv4_1',
kh=3, kw=3, n_out=512, dh=1, dw=1, p=self.parameters)
# conv4_2
self.conv4_2, self.parameters =convLayer(self.conv4_1, name='conv4_2',
kh=3, kw=3, n_out=512, dh=1, dw=1, p=self.parameters)
# conv4_3
self.conv4_3, self.parameters =convLayer(self.conv4_2, name='conv4_3',
kh=3, kw=3, n_out=512, dh=1, dw=1, p=self.parameters)
# pool4
self.pool4 = tf.nn.max_pool(self.conv4_3, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME', name='pool4')
# conv5_1
self.conv5_1, self.parameters =convLayer(self.pool4, name='conv5_1',
kh=3, kw=3, n_out=512, dh=1, dw=1, p=self.parameters)
# conv5_2
self.conv5_2, self.parameters =convLayer(self.conv5_1, name='conv5_2',
kh=3, kw=3, n_out=512, dh=1, dw=1, p=self.parameters)
# conv5_3
self.conv5_3, self.parameters =convLayer(self.conv5_2, name='conv5_3',
kh=3, kw=3, n_out=512, dh=1, dw=1, p=self.parameters)
# pool5
self.pool5 = tf.nn.max_pool(self.conv5_3, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],padding='SAME',name='pool4')
def fc_layers(self):
# 全连接层fc1
with tf.name_scope('fc1') as scope:
shape = int(np.prod(self.pool5.get_shape()[1:]))
fc1w = tf.Variable(tf.truncated_normal([shape, 4096], dtype=tf.float32,stddev=1e-1), name='weights')
fc1b = tf.Variable(tf.constant(1.0, shape=[4096], dtype=tf.float32), trainable=True, name='biases')
pool5_flat = tf.reshape(self.pool5, [-1, shape])
fc1l = tf.nn.bias_add(tf.matmul(pool5_flat, fc1w), fc1b)
self.fc1 = tf.nn.relu(fc1l)
self.parameters += [fc1w, fc1b]
# 全连接层fc2
with tf.name_scope('fc2') as scope:
fc2w = tf.Variable(tf.truncated_normal([4096, 4096], dtype=tf.float32, stddev=1e-1), name='weights')
fc2b = tf.Variable(tf.constant(1.0, shape=[4096], dtype=tf.float32), trainable=True, name='biases')
fc2l = tf.nn.bias_add(tf.matmul(self.fc1, fc2w), fc2b)
self.fc2 = tf.nn.relu(fc2l)
self.parameters += [fc2w, fc2b]
# 全连接层fc3
with tf.name_scope('fc3') as scope:
fc3w = tf.Variable(tf.truncated_normal([4096, 1000], dtype=tf.float32, stddev=1e-1), name='weights')
fc3b = tf.Variable(tf.constant(1.0, shape=[1000], dtype=tf.float32), trainable=True, name='biases')
self.fc3l = tf.nn.bias_add(tf.matmul(self.fc2, fc3w), fc3b)
self.parameters += [fc3w, fc3b]
# 加载训练好的文件模型
def load_weights(self, weight_file, sess):
weights = np.load(weight_file)
keys = sorted(weights.keys())
for i, k in enumerate(keys):
print i, k, np.shape(weights[k])
sess.run(self.parameters[i].assign(weights[k]))
if __name__ == '__main__':
sess = tf.Session()
imgs = tf.placeholder(tf.float32, [None, 224, 224, 3])
# VGGNet16模型
vgg = VGGNet16(imgs, 'vgg16_weights.npz', sess)
# img = cv2.imread('cat.jpg')
img = cv2.imread('crane.jpg')
img1 = imresize(img, (224, 224))
prob = sess.run(vgg.probs, feed_dict={vgg.imgs: [img1]})[0]
# 输出概率最高的前5种类别,以及对应的概率大小
preds = (np.argsort(prob)[::-1])[0:5]
for p in preds:
print class_names[p], prob[p]
# 概率最大的类
res = class_names[preds[0]]
font = cv2.FONT_HERSHEY_SIMPLEX
# 显示类的名字
cv2.putText(img, res, (int(img.shape[0] / 10), int(img.shape[1] / 10)), font, 1, (255, 0, 0), 2)
cv2.imshow("test", img)
cv2.waitKey(0)输出:
0 conv1_1_W (3, 3, 3, 64)
1 conv1_1_b (64,)
2 conv1_2_W (3, 3, 64, 64)
3 conv1_2_b (64,)
4 conv2_1_W (3, 3, 64, 128)
5 conv2_1_b (128,)
6 conv2_2_W (3, 3, 128, 128)
7 conv2_2_b (128,)
8 conv3_1_W (3, 3, 128, 256)
9 conv3_1_b (256,)
10 conv3_2_W (3, 3, 256, 256)
11 conv3_2_b (256,)
12 conv3_3_W (3, 3, 256, 256)
13 conv3_3_b (256,)
14 conv4_1_W (3, 3, 256, 512)
15 conv4_1_b (512,)
16 conv4_2_W (3, 3, 512, 512)
17 conv4_2_b (512,)
18 conv4_3_W (3, 3, 512, 512)
19 conv4_3_b (512,)
20 conv5_1_W (3, 3, 512, 512)
21 conv5_1_b (512,)
22 conv5_2_W (3, 3, 512, 512)
23 conv5_2_b (512,)
24 conv5_3_W (3, 3, 512, 512)
25 conv5_3_b (512,)
26 fc6_W (25088, 4096)
27 fc6_b (4096,)
28 fc7_W (4096, 4096)
29 fc7_b (4096,)
30 fc8_W (4096, 1000)
31 fc8_b (1000,)
crane 0.977137
red-breasted merganser, Mergus serrator 0.00527312
peacock 0.0034342
black stork, Ciconia nigra 0.00178344
magpie 0.00142922

VGGNet相关连接:
1.牛津大学计算机视觉组Visual Geometry Group
2.Very Deep Convolutional Network For Large-scale Image Recognition论文连接
3.ImageNet-2014大规模视觉识别挑战赛Large Scale Visual Recognition Challenge 2014 (ILSVRC2014)
3.TensorFlow实现VGG