An end-to-end TextSpotter with Explicit Alignment and Attention
An end-to-end TextSpotter with Explicit Alignment and Attention
Tong He;, Zhi Tian;, Weilin Huang, Chunhua Shen 中国科学院深圳先进技术研究院
2018 CVPR
这是一个端到端的end-to-end方法,本文的three-fold主要贡献是:
1)我们提出了一种新颖的文本对齐层,允许它以任意方向精确计算文本实例的卷积特征,这是提高性能的关键;
2)通过使用字符空间信息作为明确监督,引入字符关注机制,使识别得到很大改善;
3)两种技术以及用于字识别的新RNN分支无缝集成到可端到端训练的单个模型中。这允许两个任务通过共享卷积特征协同工作,这对于识别具有挑战性的文本实例至关重要。我们的模型在ICDAR2015 [1]数据集的端到端识别方面取得了令人瞩目的成果,显着推进了最新的结果[2],改进了F-measure(0:54; 0:51; 0:47)到(0:82; 0:77; 0:63),分别使用强,弱和通用词典。归功于联合训练,通过在两个数据集上实现最新的最先进的检测性能,我们的方法也可以作为一个好的检测器。
最近的text detection方法通常是使用一般的目标检测器,如faster rcnn,ssd等直接进行边框回归,或者使用语义分割的方法来预测每个像素是文本/非文本来检测。
word recognition可以转化为序列标记问题,其中最近开发了卷积递归模型。其中的一些进一步与注意力机制结合,以改善性能。但是,分别训练两个任务并没有利用卷积网络的全部潜力,其中卷积特征不被共享。 如果我们清楚地理解或认识到一个词及其中所有字符的含义,我们自然会做出更可靠的决定。 此外,还可以引入许多启发式规则和超参数调整成本高昂,使整个系统变得非常复杂。
最近的MASK R-CNN将实例分割任务合并到faster R-CNN [12]检测框架中,从而产生一个多任务学习模型,它共同预测每个对象实例的边界框和分割mask。我们的工作从这个管道中汲取灵感,但有一个不同的目标是学习输入图像和一组字符序列之间的直接映射。我们创造了一个在文本检测框架内进行单词识别的循环序列建模分支,其中基于RNN的单词识别与检测任务并行处理。然而,随着时间的推移,梯度反向传播的RNN分支显然比检测中的边界框回归任务更难以优化。这自然会导致两个任务之间的学习困难和收敛率的显着差异,使得该模型特别具体难以共同训练。例如,用于训练文本检测模型的图像的大小约为103(例如,ICDAR 2015中的1000个训练图像[1])但是,当训练基于RNN的文本识别模型时,数量显着增加了许多数量级,例如[20]中使用的800K合成图像。此外,简单地使用一组字符序列作为直接监督可能过于抽象(高级)以提供有意义的详细信息以有效地训练这样的集成模型,这将使模型难以收敛。在这项工作中,我们在单词和字符级别引入了强大的空间约束,这允许通过减少模型来逐渐优化模型每一步搜索空间。
训练文本检测模型的图像数量需要几千张即可,但是训练基于RNN的文本识别模型,则需要几十万张图像,
首先,我们通过引入网格采样方案而不是传统的RoI pooling来开发文本对齐层。它计算固定长度的卷积特征,精确对准任意方向的检测文本区域,成功地避免了由方向改变和RoI合并的量化因子引起的负面影响。
其次,我们通过使用角色空间信息作为附加监督来引入角色关注机制。这明确地将字符的强烈空间注意力编码到模型中,这允许RNN关注于解码中的当前注意特征,从而导致字识别中的性能提升。
第三,这两种方法与用于单词识别的新RNN分支一起优雅地集成到CNN检测框架中,从而产生可以以端到端方式训练的单个模型。我们开发了一种原则性和直观的学习策略,通过共享功能和快速收敛,可以有效地训练这两项任务。
最后,我们通过实验证明了单词识别这可以显着提高我们模型中的检测准确性,展示它们的强大互补性,这是高度特定领域的独特性应用。我们的模型在ICDAR2015上实现了最先进的结果,在多端方向文本的端到端识别中,大多数都超过了最多
最近的结果在[2]中,F-measure的改进从(0:54; 0:51; 0:47)到(0:82; 0:77; 0:63)在使用强弱,弱通用词典。代码可用 -
能够访问https://github.com/tonghe90/textspotter
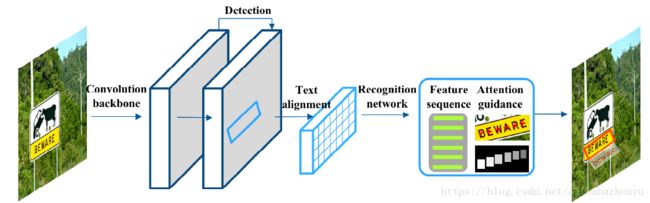
Our model is a fully convolutional architecture built on the PVAnet framework,本文引入了一个新的循环分支用于word识别,它与现有的文本边界框回归检测分支并行地集成到我们的CNN模型中。RNN分支由新的文本对齐层和基于LSTM的循环模块组成,具有新颖的字符注意嵌入机制。文本对齐层在检测到的区域内提取精确的序列特征,防止编码无关文本或背景信息。 字符注意力嵌入机制通过提供更详细的字符监督来调节解码过程。我们的文本除了简单的非最大抑制(NMS)之外,一次性直接输出nal结果,没有任何后处理步骤。
Network architecture
我们的模型是受[8]启发的完全卷积体系结构,其中PVA网络[32]由于其显着低的计算成本而被用作主干,与通用对象不同,文本在大小和宽高比方面通常具有更大的变化。 因此,它不仅需要保留小规模文本实例的本地细节,而且还应该为很长的实例维护一个大的接收字段。受语义分割成功的启发[33],我们通过逐渐结合conv5,conv4,conv3和conv2层的卷积特征来利用特征融合,目的是维护局部细节特征和高级上下文信息。 这样可以对多尺度文本实例进行更可靠的预测。 为简单起见,顶层的大小是输入图像的1/4。
Text detection:
它在顶部卷积层上包含两个子分支,设计用于联合文本/非文本分类和多方向边界框回归。第一个子分支返回具有顶部特征图的相等空间大小的分类图,使用softmax函数指示预测的文本/非文本概率。 第二子分支输出具有相同空间大小的ve定位图,其在文本区域的每个空间位置处以任意方向估计每个边界框的ve参数。 ve参数表示距离当前指向相关联的边界框的顶部,底部,左侧和右侧以及其倾斜方向。 通过这些配置,检测分支能够为每个文本实例预测任意方向的四边形。 然后,通过下面描述的文本对齐层将检测到的四边形区域的特征馈送到RNN分支以进行单词识别。
TextAlignment Layer
我们为单词识别创建了一个新的循环分支,其中提出了一个文本对齐层,用于从任意大小的四边形区域精确计算固定大小的卷积特征。 文本对齐层是从RoI pooling扩展而来,它广泛用于一般的目标检测。 RoI池化通过执行量化操作,从任意大小的矩形区域计算固定大小的卷积特征(例如,7-7)。 它可以集成到卷积层中,用于网络内区域裁剪,这是端到端训练检测框架的关键组成部分。 但是,直接将RoI池应用于文本区域将导致由于未对齐问题导致的字识别性能显着下降。
首先,与目标检测和分类不同,其中RoI池化计算用于区分目标的RoI区域的全局特征,单词识别需要更详细和准确的局部特征和空间信息以顺序地预测每个字符。 正如[19]中所指出的,RoI池化执行量化这不可避免地会在原始RoI区域和提取的特征之间引入错位。 这种错位对预测字符有很大的负面影响,特别是对于一些小规模的角色,如“i”,“l”。
此外,当矩形RoI区域应用于高度倾斜的文本实例时,很容易编码大量的背景信息和不相关的文本,如图3所示。这严重降低了RNN解码的性能。识别连续字符的过程。
这激发了当前的工作,开发了一个新的文本对齐层,为文本实例量身定制,这是一个任意方向的四边形。 它提供了强大的字级对齐和精确的每像素对应,这是至关重要的从卷积图中提取精确文本信息的重要性,如图3所示。
具体来说,给定一个四边形区域,我们首先建立一个大小为h x w的采样网格。 w在顶部卷积图上。 采样点在区域内以等距间隔生成,并且采样点(p)在空间中生成的特征向量(vp)位置(px; py),通过双线性采样[19]计算如下,
Word Recognition with Character Attention(字符级的attention)
字识别模块建立在文本对齐层上,其中输入是从文本对齐池化层、大小为 wx H x C的输出固定大小的卷积特征,其中C是卷积通道的数量。卷积特征被馈送到多个初始模块并生成一系列特征向量,例如64?C维特征,如图4所示。在下一部分中,我们将简要介绍引入注意机制和三种策略来提高注意力。
评价数据集:ICDAR2013 and ICDAR2015.
Attention Mechanism
在编码过程中,利用双向LSTM层来编码顺序矢量。 它输出隐藏状态1; 他2;:::; 他有相同的数字,它编码来自过去和未来信息的强顺序上下文特征。 与使用每个隐藏状态解码字符(包括非字符标签)的先前工作[9,16]不同,注意机制引入了新的解码过程,其中在每次解码迭代时自动学习注意权重(Δt2Rw)。 并且解码器通过使用该注意向量来预测字符标签(yt)。
我们介绍了一种增强字识别中字符注意力的新方法。我们开发了明确编码的字符对齐机制强大的字符信息,以及面具监督任务,为模型学习提供有意义的局部细节和角色空间信息。此外,还介绍了注意位置嵌入。它从输入序列中识别出最重要的点,进一步增强了推理中相应的文本特征。 这些技术改进无缝集成到端到端可训练的统一框架中。 每个模块的细节描述如下。
Attention alignment
Our methods require character-level bounding boxes for generating character coordinates and masks.这个方法需要字符级的边界框标注?
把在合成图像上训练的数据集泛化到自然图像上的方法:
整个model是在caffe上实现的。
读语言检测数据集http://rrc.cvc.uab.es/?ch=8&com=introduction
文本检测的评估protocols:DetEval and ICDAR2013 standard [37].
“弱”词典包含测试数据集中出现的所有单词。 'Generic'词典有90K字。 有一点需要注意的是,所有单词的长度字典大于3,不包括符号和数字。 有两种评估协议:端到端和字识别。 端到端的需求无论字典是否包含这些字符串,都能准确地识别所有单词。 另一方面,单词识别只检查是否在单词中字典出现在图像中,使其不像端对端那样严格忽略长度小于3的符号,数字和单词。
RoI Pooling vs Text alignment
boosting from 60.7% to 67.6%.
Character Attention
所提出的方法比注意力LSTM提供更准确的字符定位,导致准确度提高约2%。
识别任务大大提高了检测的性能,如召回和精确度,使F-Measure提高3%。联合训练使文本背景和复杂的文本实例更加健壮。
Conclusion
我们提出了一种新颖的文本对齐层,它可以提取精确的序列信息,而无需编码不相关的背景或文本。 我们还通过在解码过程中增强字符的注意力来提高传统LSTM的准确性。我们提出的方法在两个开放的基准测试中实现了最先进的性能:ICDAR2013和ICDAR2015,并且大大优于以前的最佳方法。