Hive中的数据倾斜
列举Hive中出现数据倾斜的几种情况:
一、没开Map端聚合产生的计算不均衡
例如有一张客户表customer,里面存有客户ID(cust_id)和性别(gender),男女各1亿条记录,cust_id没有重复。
现在要按性别分组统计记录数:
select gender, count(1)
from customer
group by gender;
没开Map端聚合的数据处理流程如下:
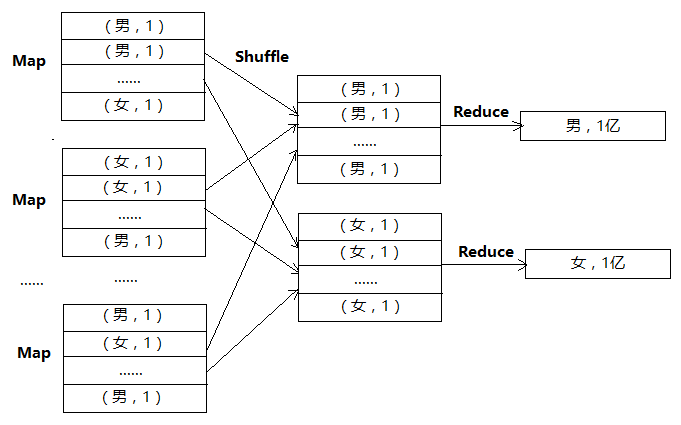
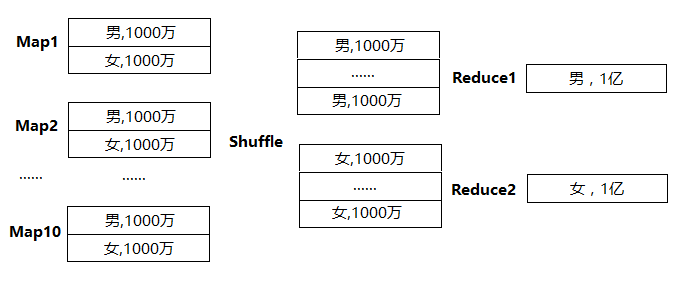
可以看到,假设Map有1万个,Map直接把groupby_key 当作reduce_key发送给Reduce做聚合,虽然Map有很多个,但Reduce只有两个在做聚合,每个Reduce处理1亿条记录,就样就导致了计算不均衡的现象。
可以通过设置参数hive.map.aggr=true来解决这个问题,此参数控制在group by的时候是否在Map端做局部聚合,这个参数默认是打开的。参数打开后的数据处理流程如下:
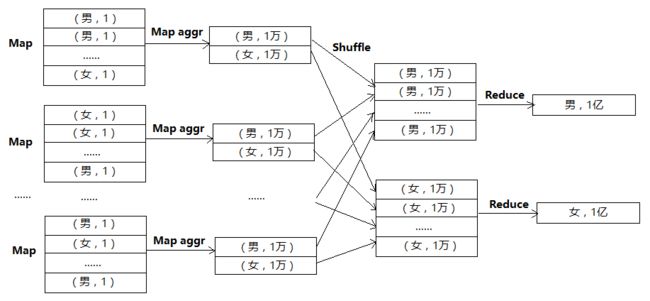
可以看到,由于Map端已经做了局部聚合,虽然最后还是只有两个Reduce做最后的聚合,但是每个Reduce只用处理1万行记录,而优化前要处理1亿行,是优化前的万分之一。
Map端聚合默认是打开的,但不是所有的聚合都需要这个优化。考虑前面的SQL,如果groupby_key是客户ID,而客户ID没有重复,此时Map端聚合就没有太大意义,反而会增加资源消耗。
select cust_id, count(1)
from customer
group by cust_id;
可以通过下面两个参数控制关闭Map端聚合的策略:
hive.groupby.mapaggr.checkinterval = 100000
Hive.map.aggr.hash.min.reduction=0.5
Map开始的时候,先尝试给前100000 条记录做hash聚合,如果聚合后的记录数/100000>0.5,说明这个groupby_key没有什么重复的,再继续做局部聚合没有意义,100000条记录后就自动关闭Map端聚合开关。
二、distinct产生的计算不均衡
例如下面的SQL:
select gender,count(distinct cust_id)
from customer
group by gender;
由于Map需要保存所有的cust_id ,Map端聚合开关会自动关闭,导致只有2个Redcue做聚合,每个Reduce处理1亿条记录。 数据处理流程如下:
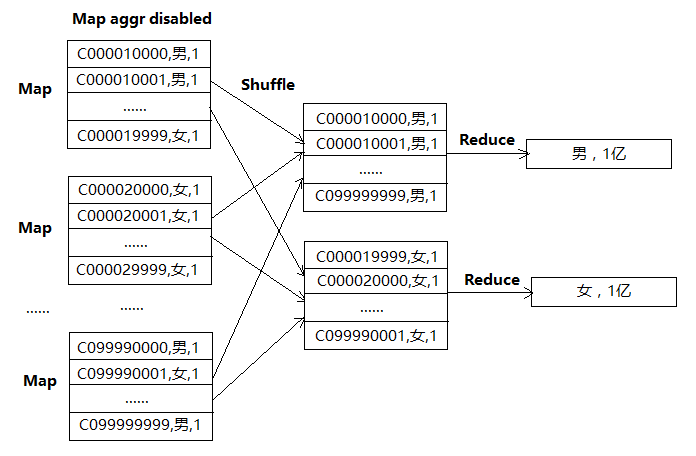
可以通过设置下面参数来解决这个问题:
hive.groupby.skewindata =true
这个参数决定group by操作是否支持倾斜数据。(注意,只能对单个字段聚合。)控制生成两个MR Job:
在第一个MapReduce中,Map的输出结果随机分布到 Reduce 中,reduce_key是gender+cust_id。因为cust_id是一个随机散列的值,因此Reduce计算是很均匀的。这样处理的结果是,相同的 Group By Key 有可能分发到不同的Reduce中,从而达到负载均衡的目的。数据处理流程如下:
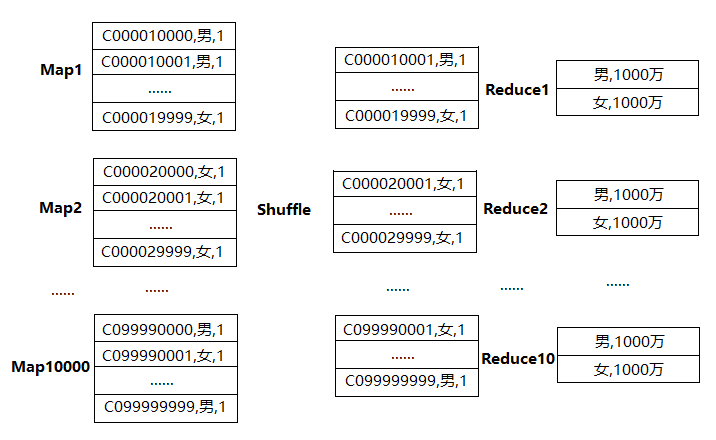
在第二个MapReduce中,会根据预处理的数据结果按照Group By Key分布到Reduce 中(这个过程可以保证相同的Group By Key分布到同一个Reduce中),完成最终的聚合操作。虽然最后也只有两个Redcue计算也没有关系,因为绝大部分计算量已经在第一个MR完成。数据处理流程如下:
hive.groupby.skewindata默认是关闭的,因此如果确定有不均衡的情况,需要手动打开这个开关。当然,并不是所有的有distinct的group by都需要打开这个开关,比如下面的SQL:
select cust_id,count (distinct gender)
from customer
group by cust_id;
因为cust_id是一个散列的值,因此已经是计算均衡的了,所有的reduce都会均匀计算。只有在groupby_key不散列,而distinct_key散列的情况下才需要打开这个开关,其他的情况Map端聚合优化就足矣。
三、Join 中的计算均衡优化
在Hive中,join操作一般都是在Reduce阶段完成的,写SQL的时候要注意把小表放在join的左边,原因是在Join操作的Reduce阶段,位于Join操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生out of memory错误的几率。一个大表和一个配置表的reduce join经常会引起计算不均衡的情况。
比如配置表gender_config(gender_id int, gender string,)。把“男”“女”字符串映射成一个id。配置表和上面的customer表join的SQL如下:
select t2.cust_id,
t1.gender_id
from gender_config t1
join customer t2
on t1.gender=t2.gender;
只有“男”“女”两个值,Hive处理join的时候把join_key作为reduce_key,因此会出现和group by类似的Reduce计算不均衡现象,只有两个Reduce参与计算,每个Reduce计算1亿条记录。数据处理流程如下: 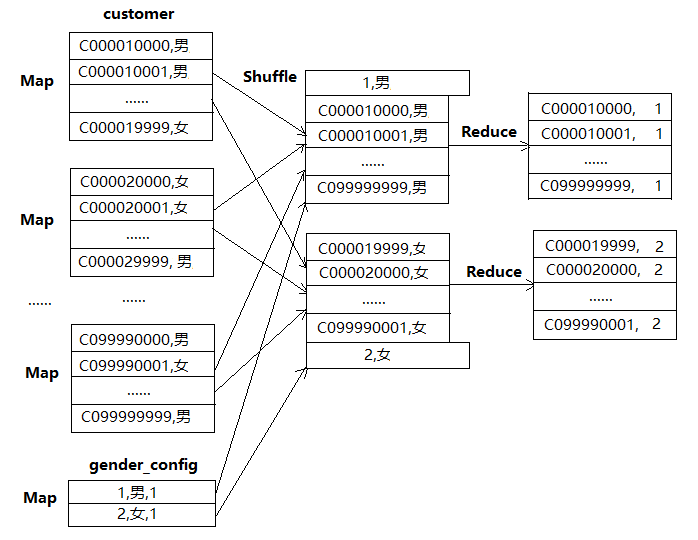
这种大表和配置表join的不均衡现象,通常采用mapjoin的方式来解决。目前hive是采用/*+ MAPJOIN(gender_config) */提示的方式告诉翻译器把SQL翻译成mapjoin,提示里必须指明配置表是哪个。
select /*+ MAPJOIN(gender_config) */ t2.cust_id,
t1.gender_id
from gender_config t1
join customer t2
on t1.gender=t2.gender;
一个大表和一个小配置表的map join里面,每个Map会把小表读到hash table,然后和大表做hash join。数据处理流程如下:
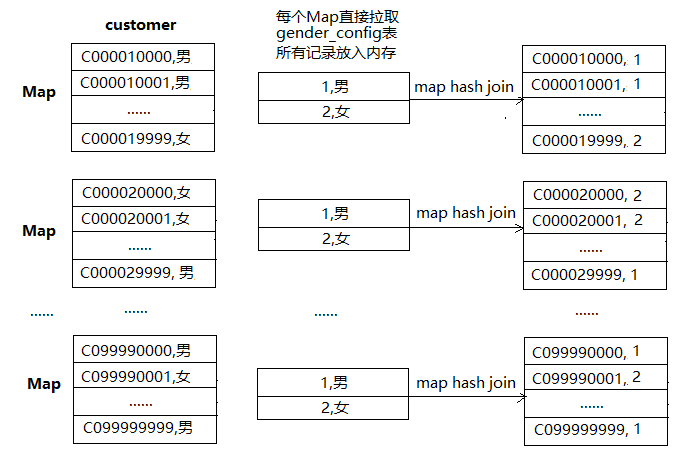
map join的关键是小表能放入map进程的内存,如果内存放不下会序列化到硬盘,效率会直线下降。成千上万个Map从HDFS读这个小表进自己的内存,使得小表的读操作变成这个join的瓶颈,甚至有些时候有些Map读这个小表会失败(因为同时有太多进程读了),最后导致join失败。临时解决办法是增加小表的副本个数。
下一步优化可以考虑把小表放入Distributed Cache里,Map读本地文件即可。 方法如下 :
1、创建MapJoin 类:
package hadoop;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MapJoin {
static class MapJoinMapper extends Mapper{
//用来缓存小文件(性别配置文件中的数据)
Map genderConfigMap = new HashMap();
Text k = new Text();
/*
* 源码中能看到在循环执行map()之前会执行一次setUp方法,可以用来做初始化
*/
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
//将性别配置文件中的数据写到缓存中,千万别写成/gender_config.data否则会提示找不到该文件
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("gender_config.data")));
String line = null;
while((line=br.readLine())!=null){
//一行数据格式为1,男(性别id,性别),因为性别配置表和客户表通过性别字段join,所以key为性别,value为性别id
String[] fields = line.split(",");
genderConfigMap.put(fields[1], fields[0]);
}
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//一行客户数据 格式为 C000010000,男(客户id,性别)
String line = value.toString();
String[] fields = line.split(",");
//根据性别配置数据在缓存中找出对应性别id,进行串接
String genderId = genderConfigMap.get(fields[1]);
k.set(line+","+genderId);
context.write(k, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//jar包位置
job.setJarByClass(MapJoin.class);
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//指定需要缓存一个文件到所有的maptask运行节点工作目录
// job.addArchiveToClassPath(archive);缓存jar包到task运行节点的classpath中
// job.addCacheArchive(uri);缓存压缩包到task运行节点的工作目录
// job.addFileToClassPath(file);//缓存普通文件到task运行节点的classpath中
//将性别配置文件缓存到task工作节点的工作目录中去
//缓存普通文件到task运行节点的工作目录(hadoop帮我们完成)
job.addCacheFile(new URI("hdfs://10.200.4.117:9000/mapjoincache/gender_config.data"));
//不需要reduce,那么也就没有了shuffle过程
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean ex = job.waitForCompletion(true);
System.exit(ex?0:1);
}
}
2、测试:
1)将以上工程打成mapjoin.jar包上传到集群的NameNode;
2)在任意节点创建客户文件和性别配置文件(customer.data和gender_config.data):
vi customer.data
输入以下内容:
C000010000,男
C000010001,男
C000010002,男
C000010003,男
C000010004,男
C000010005,男
C000010006,男
C000010007,男
C000010008,男
C000010009,男
C000020000,女
C000020001,女
vi gender_config.data
输入以下内容:
1,男
2,女
3)创建HDFS输入目录/mapjoincache/input,将customer.data传上去:
hdfs dfs -mkdir -p /mapjoincache/input
hdfs dfs -put customer.data /mapjoincache/input
4)将gender_config.data放到HDFS的/mapjoincache目录下:
hdfs dfs -put gender_config.data /mapjoincache
5)在NameNode运行程序:
hadoop jar mapjoin.jar hadoop.MapJoin /mapjoincache/input /mapjoincache/output
日志如下:
[hadoop@oracle02 hadoop]$ hadoop jar mapjoin.jar hadoop.MapJoin /mapjoincache/input /mapjoincache/output
Mar 29, 2019 6:10:55 PM org.apache.hadoop.util.NativeCodeLoader
WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Mar 29, 2019 6:10:55 PM org.apache.hadoop.yarn.client.RMProxy createRMProxy
INFO: Connecting to ResourceManager at /10.200.4.117:8032
Mar 29, 2019 6:10:56 PM org.apache.hadoop.mapreduce.JobResourceUploader uploadFiles
WARNING: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
Mar 29, 2019 6:10:57 PM org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
INFO: Total input paths to process : 1
Mar 29, 2019 6:10:57 PM org.apache.hadoop.mapreduce.JobSubmitter submitJobInternal
INFO: number of splits:1
Mar 29, 2019 6:10:57 PM org.apache.hadoop.mapreduce.JobSubmitter printTokens
INFO: Submitting tokens for job: job_1553849163903_0003
Mar 29, 2019 6:10:57 PM org.apache.hadoop.yarn.client.api.impl.YarnClientImpl submitApplication
INFO: Submitted application application_1553849163903_0003
Mar 29, 2019 6:10:57 PM org.apache.hadoop.mapreduce.Job submit
INFO: The url to track the job: http://oracle02.auditonline.prd.df.cn:8088/proxy/application_1553849163903_0003/
Mar 29, 2019 6:10:57 PM org.apache.hadoop.mapreduce.Job monitorAndPrintJob
INFO: Running job: job_1553849163903_0003
Mar 29, 2019 6:11:02 PM org.apache.hadoop.mapreduce.Job monitorAndPrintJob
INFO: Job job_1553849163903_0003 running in uber mode : false
Mar 29, 2019 6:11:02 PM org.apache.hadoop.mapreduce.Job monitorAndPrintJob
INFO: map 0% reduce 0%
Mar 29, 2019 6:11:08 PM org.apache.hadoop.mapreduce.Job monitorAndPrintJob
INFO: map 100% reduce 0%
Mar 29, 2019 6:11:08 PM org.apache.hadoop.mapreduce.Job monitorAndPrintJob
INFO: Job job_1553849163903_0003 completed successfully
Mar 29, 2019 6:11:08 PM org.apache.hadoop.mapreduce.Job monitorAndPrintJob
INFO: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=110039
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=287
HDFS: Number of bytes written=204
HDFS: Number of read operations=5
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3152
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=3152
Total vcore-milliseconds taken by all map tasks=3152
Total megabyte-milliseconds taken by all map tasks=3227648
Map-Reduce Framework
Map input records=12
Map output records=12
Input split bytes=107
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=640
CPU time spent (ms)=510
Physical memory (bytes) snapshot=166731776
Virtual memory (bytes) snapshot=2173693952
Total committed heap usage (bytes)=143130624
File Input Format Counters
Bytes Read=180
File Output Format Counters
Bytes Written=204
6)查看生成的结果文件:
hdfs dfs -cat /mapjoincache/output/part-m-00000
内容如下:
C000010000,男,1
C000010001,男,1
C000010002,男,1
C000010003,男,1
C000010004,男,1
C000010005,男,1
C000010006,男,1
C000010007,男,1
C000010008,男,1
C000010009,男,1
C000020000,女,2
C000020001,女,2
完毕。