Faster R-CNN详解
1. 摘要
最好的目标检测网络依靠区域建议算法来推测目标的位置。SPPnet [1]和Fast R-CNN [2]等已经减少了这些检测网络的运行时间,但是暴露了区域建议的计算瓶颈问题。因此,我们引入了一个区域建议网络(RPN),该网络与目标检测网络共享图像的全卷积特征,从而实现了几乎无成本的区域建议过程。RPN是一个全卷积网络,可同时预测每个位置的目标边界框和目标预测得分。RPN经过端对端训练以生成高质量的区域建议框,然后Fast R-CNN将其用于目标检测。我们进一步将RPN和Fast R-CNN通过共享其卷积特征图合并为一个网络。基于VGG-16深度模型[3],我们的检测框架在GPU上的帧速率为5fps(包括所有步骤),同时在PASCAL VOC 2007,2012上实现了最优的目标检测精度,在MS COCO数据集上每张图片只产生300个区域建议框。
2. Introduction
最近目标检测的发展是由区域建议方法[4]和基于区域建议的卷积神经网络(R-CNNs)[5]的成功所推动的。尽管[5]中最初开发的基于区域建议的CNNs的计算量很大,但由于共享卷积[1],[2]使得其计算量已大幅降低。 Fast R-CNN [2]使用非常深的网络实现接近实时的速率[3],而忽略了花在区域建议上的时间。但是,区域建议是检测框架中测试时间的计算瓶颈。
区域建议方法通常依赖特征和推断。Selective Search [4]是最流行的方法之一。然而,与有效的检测网络[2]相比,选择性搜索算法速度慢了一个数量级,在CPU上实现,每个图像需2秒。EdgeBoxes[6]目前在区域建议框的质量和速度之间提供了最佳平衡,每张图像只有0.2秒。尽管如此,区域建议的步骤仍然会消耗与检测网络一样多的运行时间。
有人可能会注意到,Fast R-CNN利用了GPU,而在研究中使用的区域建议方法是在CPU上实现,使得这种运行时间比较不公平。加速区域建议计算的一个明显的方法是也将其在GPU实现。这可能是一个有效的工程解决方案,但重新实施则忽略了下游检测网络,因此错过了共享计算的重要机会。
在本文中,我们展示了算法的变化 - 计算区域建议的卷积神经网络 -一个优雅和有效的解决方案,建议计算检测网络的计算几乎无成本。为此,我们引入了新颖的区域建议网络(RPNs),它们共享具有最新目标检测网络的卷积层[1],[2]。通过在测试时共享卷积层,计算建议的边际成本就很小(例如,每个图像10ms)。
我们的结果是基于区域检测的卷积特征图(如Fast RCNN)也可用于生成区域建议。在这些卷积特征之上,我们通过添加一些额外的卷积层来构建RPN,这些卷积层同时在regular grid的每个位置处生成回归区域边界和目标预测得分。RPN因此是一种全卷积网络(FCN)[7],并且可以专门用于生成检测建议框。
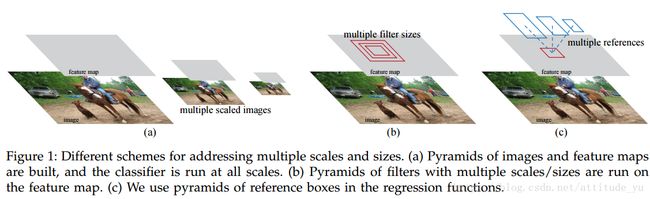
RPN旨在有效预测各种scale和aspect ration的区域建议框。与使用图像金字塔(图1,a)或滤波金字塔(图1,b)的方法[8],[9],[1],[2]对比,我们引入了”anchor”框。我们的方案可以被认为是回归参考金字塔(图1,c),它避免了需枚举多个scale和aspect ration的图像或滤波器。该模型在使用single-scale图像进行训练和测试时表现良好,从而有利于提升运行速度。
为了将RPN与Fast R-CNN [2]目标检测网络统一起来,我们提出了一种训练方案,该方案在区域建议网络的微调和微调目标检测网络之间进行交替,同时保持建议框的固定。该方案迅速收敛并产生具有卷积特征的统一网络,这些特征在两个任务之间共享。
我们在PASCAL VOC检测基准[11]中综合评估了我们的方法,其中使用RPNs的Fast R-CNN产生的检测精度优于使用selective search 算法的Fast R-CNN。同时,我们的方法在测试时几乎免除了selective search的所有计算负担 – 建议框的有效运行时间仅为10毫秒。使用[3]的更深的深度模型,我们的检测方法在GPU上仍然具有5fps的帧率(包括所有步骤),因此在速度和准确性方面都是实用的目标检测框架。我们还说明了MS COCO数据集[12]的结果,并使用COCO数据研究了对PASCAL VOC的改进。
这篇手稿的初稿已经在之前发表[10]。从那时起,RPN和Faster R-CNN的框架已被采用并推广到其他方法,如3D目标检测[13],基于部分的检测[14],实例分割[15]和图像标注[16]。我们的快速和有效的目标检测框架也已应用在商业系统中,如Pinterests [17]。
在ILSVRC和COCO 2015比赛中,Faster R-CNN和RPN是ImageNet目标检测跟踪,ImageNet定位,COCO检测和COCO分割中第一名[18]的基础。RPNs完全从数据中学习提出区域建议框,因此可以从更深入和更具表现力的特征(例如[18]中采用的101层残差网络)中轻松获益。Faster R-CNN和RPN也被这些比赛中的其他几个主要参赛者使用。这些结果表明,我们的方法不仅是实际使用的经济高效的解决方案,而且是提高目标检测精度的有效方法。
3. Faster R-CNN
我们的目标检测框架称为Faster R-CNN,由两个模块组成。第一个模块是提出区域建议框的深度全卷积网络RPN,第二个模块是使用提出区域建议框的Fast R-CNN检测框架[2]。整个框架是用于目标检测的统一网络(图2)。 RPN模块使用最近流行的具有'attention'[31]机制的神经网络术语,告诉Fast R-CNN模块在哪里寻找目标。在第3.1节中,我们介绍区域建议网络的设计和属性。在第3.2节中,我们介绍用于训练具有共享特征模块的算法。

3.1 Region Proposal Networks
一个区域建议网络(RPN)以任意大小的图像作为输入,并输出一组矩形目标建议,每个建议框都有一个目标预测得分。我们用全卷积网络对这个过程进行建模[7]。因为我们的最终目标是与Fast R-CNN目标检测网络共享计算[2],所以我们假设两个网络共享一组共同的卷积层。在我们的实验中,我们研究了具有5个可卷积层的Zeiler Fergus模型[32](ZF)和具有13个卷积层的Simonyan Zisserman模型[3](VGG-16)。
为了生成区域建议框,我们在由最后的共享卷积层上滑动一个小网络。这个小网络将输入卷积特征图的n×n空间窗口作为输入。每个滑动窗口被映射到一个较低维度的特征向量上(ZF为256-d,VGG为512-d,ReLU[33]如下)。这个特征向量被输入到两个全连接层 - 一个边界框回归层(reg)和一个边界框分类层(cls)。我们在本文中使用n = 3,注意到在输入图像上的有效接受区域很大(分别ZF和VGG分别为171和228像素)。这个mini网络在图3(左)的单个位置进行说明。因为mini网络以滑动窗口的方式操作,所有空间位置共享全连接层。这种架构自然地先用一个n×n卷积层,然后是两个1×1卷积层(分别用于reg和cls)来实现。
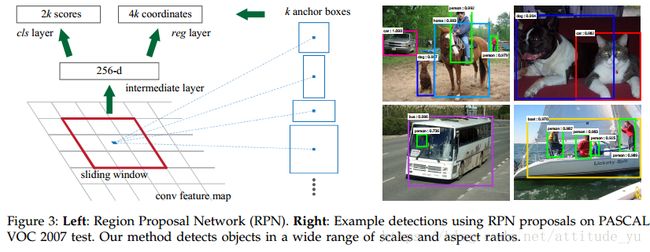
3.1.1 Anchors
在每个滑动窗口位置,我们同时预测多个区域建议框,其中每个位置的最大可能建议的数量被表示为k。因此,reg层具有4k个输出,即k个框的坐标,并且cls层输出2k个预测得分,其估计每个建议框是目标或不是的概率。k个建议框被参数化为k个参考框,我们称之为Anchor。Anchor位于滑动窗口的中心,并且与scale和aspect ratio相关(图3左)。默认情况下,我们使用3个scale和3个aspect ratio,即在每个滑动框产生k=9个Anchor。对于大小为W×H(通常约为2400)的卷积特征映射,总共有W*H*k个Anchor。
由于这种基于anchor的多尺度设计,我们可以简单地使用在单尺度图像上计算卷积特征,Fast R-CNN检测器也是如此。多尺度anchor的设计是共享特征的关键部分,不需要额外的成本来解决尺度问题。
3.1.2 Loss Function
为了训练RPNs,我们为每个anchor分配一个二类标签(是目标或不是)。我们为两种情况下的anchor赋值正标签:(i)anchor/anchors具有最高IoU,或者(ii)IoU高于0.7的任何ground truth。注意,单个ground truth框可以为多个anchors赋值正标签。通常第二个条件足以确定正样本;但我们仍然采用第一个条件,原因是在少数情况下,第二个条件可能找不到正样本。如果其所有ground truth框的IoU低于0.3,我们会为非负anchor赋值负标签。既不是正也不是负的anchor不会有助于训练。
通过这些定义,我们将Fast R-CNN中的多任务损失的目标函数最小化[2]。我们对图像的损失函数定义为:
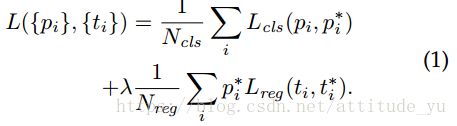
i是一个小批量样本中anchor的索引,pi是anchor i作为目标的预测概率。如果anchor为正,则ground truth标签pi*为1,如果anchor为负,则pi*为0。ti是表示预测边界框的4个参数化坐标的矢量,并且ti*是与正anchor相关联的ground truth框的矢量。分类损失Lcls是两个类(目标与非目标)的对数损失。对于回归损失,我们使用L reg(ti;ti*)= R(ti-ti*),其中R是[2]中定义的鲁棒损失函数(平滑L1)。pi* Lreg表示回归损失仅在anchor(pi* = 1)是正标签时被激活,否则被禁用(pi* = 0)。cls和reg层的输出分别是pi和ti。
这两项通过Ncls和Nreg进行归一化,并由平衡参数λ加权。在我们当前的实现中(发布的代码中),方程(1)中的cls项通过最小批量(即,Ncls = 256)进行归一化,并且通过anchor位置的数量(即〜2400)。默认情况下,我们设λ= 10,因此cls和reg项的权重大致相等。我们通过实验表明,结果在很宽的范围内对λ的值不敏感(表9)。我们还注意到,如上所述的归一化不是必需的,可以省略。
对于边界框回归,我们采用[5]对4个坐标参数化:
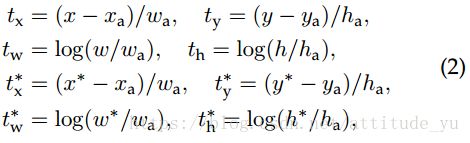
其中x,y,w和h表示框的中心坐标及其宽度和高度。变量x,xa和x*分别表示预测框,acnchor框和ground truth框(同样适用y; wa; h*)。这可以被认为是从anchor 框到附近的ground truth框的边界框回归。
尽管如此,我们的方法通过与之前的基于RoI(Region of Interest)方法不同的方式实现了边界框回归[1],[2]。在[1],[2]中,对来自任意大小的RoIs在features pooled执行边界框回归,并且回归权重由所有region sizes共享。在我们的公式中,用于回归的特征在特征图上具有相同的空间大小(3×3)。为了说明不同的尺寸,学习一组k个边界框回归器。每个回归器代表一个scale和一个aspect ratio,而k个regressor不共享权重。 因此,由于anchor的设计,即使特征具有固定的size/scale,仍然可以预测各种尺寸的anchors。
3.2 Sharing Features for RPN and Fast R-CNN
到目前为止,我们已经描述了如何训练用于区域建议框生成的网络,而没考虑将利用这些建议框的目标检测CNN。对于检测网络,我们采用Fast R-CNN [2]。接下来,我们将介绍使用共享卷积层学习由RPN和Fast R-CNN组成的统一网络的算法(图2)。
独立训练的RPN和Fast R-CNN将以不同的方式修改卷积层。因此,我们需要开发一种允许在两个网络之间共享卷积层的技术,而不是学习两个单独的网络。我们讨论了特征共享的三种训练网络的方法:
3.2.1交替训练。
在这个解决方案中,我们首先训练RPN,并使用这些建议框来训练Fast R-CNN。由Fast R-CNN微调的网络然后用于初始化RPN,并且该过程是重复的。这是本文所有实验中使用的解决方案。
3.2.2近似联合训练。
在这个解决方案中,RPN和Fast R-CNN网络在训练期间合并为一个网络,如图2所示。在每次SGD迭代中,前向传播生成区域建议。在训练Fast R-CNN检测器时,这些区域建议与固定的区域建议一样。 反向传播像平常一样,其中对于共享层,来自RPN得损失和Fast R-CNN的损失的反向传播被结合。这个解决方案很容易实现。但是这个解决方案忽略了区域建议框的坐标导数w.r.t.,其也是网络responses,所以是近似的。在我们的实验中,我们凭经验发现这个sover产生了接近的结果,与交替训练相比,训练时间减少了约25-50%。这个sover包含在我们发布的Python代码中。
3.2.3非近似联合训练。
如上所述,由RPN预测的边界框也是输入的函数。Fast R-CNN中的RoI池化层[2]接受卷积特征和预测的边界框作为输入,所以理论上有效的反向传播solver也应该包含边框坐标梯度w.r.t.。在上述近似联合训练中,这些梯度被忽略。在一个非近似的联合训练解决方案中,我们需要一个可区分边框坐标梯度w.r.t.的RoI池层。这是一个nontrivial问题,可以通过[15]中的“RoI warping”层给出解决方案,这超出了本文的范围。
3.2.4四步交替训练。
在本文中,我们采用实用的4步训练算法通过交替优化来学习共享特征。在第一步中,我们按照3.1.3节的描述训练RPN。该网络使用ImageNet预先训练的模型进行初始化,并针对区域建议任务进行端到端微调。在第二步中,我们使用由第一步RPN生成的建议框,送入Fast R-CNN训练单独的检测网络。该检测网络也由ImageNet预先训练的模型初始化。前两步两个网络不共享卷积层。在第三步中,我们使用检测网络初始化RPN,但是此时我们固定共享卷积层,并且只对RPN的层进行微调。此时这RPN网络和Fast R-CNN网络共享卷积层。最后,保持共享卷积层的固定,我们对Fast R-CNN的层进行微调。因此,两个网络共享相同的卷积层并形成统一的网络。类似的交替训练可以运行更多次迭代,但我们观察到可以忽略这些迭代。
4. Conclusion
我们已经提出了RPNs以便生成高效和准确的区域建议框。通过与FastR-CNN检测网络共享卷积特征,区域建议步骤几乎没有成本。我们的方法是统一的,基于深度学习的目标检测系统能够以接近实时的帧率运行。学习到的RPN也提高了区域建议质量,从而提高了整体目标检测的准确性。
推荐博客:
1. 从代码角度理解Faster R-CNN
https://blog.csdn.net/e01528/article/details/79615987
https://blog.csdn.net/u013010889/article/details/78574879
https://blog.csdn.net/lanyuelvyun/article/details/77720260