TextSnake详解
1. 摘要
在深度神经网络和大规模数据集的推动下,自然场景文本检测方法在过去的几年里取得了巨大的进步,不断刷新各种基准记录。然而,如下图所示,受到描述文本表征(水平矩形框、旋转矩形框或任意四边形框)的限制,现有的方法在处理更自由形式的文本实例(例如弯曲文本)时可能会表现的差强人意,而这些文本实例往往在实际中非常常见。为了解决这个问题,本文提出了一种更灵活的场景文本表征,称为TextSnake,它能够以水平、多方向和弯曲的形式有效地表征文本实例。在TextSnake中,文本实例检测框表征为以对称轴为中心的有序的、重叠的圆盘序列,每个圆盘都有其可变的半径和方向。

2. TextSnake算法
2.1 文本表征

文本区域TR(黄色)利用一系列有序圆盘(蓝色)来表示,每个圆盘位于中心线TCL(绿色,即对称轴)上,圆盘的几何形状与半径r和方位θ相关联。其与传统的表征方式(轴对齐矩形、旋转矩形和四边形)相比,不考虑文本区域的形状和长度。
数学定义:由几个字符组成的文本实例t可以看作是一个有序列表S(t)。S(t)={D0,D1,…,Di,…,Dn},其中Di代表ith圆盘,n代表圆盘数。每个圆盘D又由一组几何属性表示,即D=(c, r, θ),其中c、r和θ分别是圆盘D的中心、半径和方向。半径r定义为t的局部区域宽度的一半,而方向θ是当前圆盘与下一个圆盘中心点连线与水平方向的夹角。当获得S(t)后,则可重建弯曲的文本区域。另外注意,圆盘不对应t中的单个字符,即圆盘是重叠的。
2.2 网络结构
基于FCN+FPN网络预测文本框,包含特征提取、特征合并、输出层三个阶段。

特征提取:VGG-16/19;
特征合并:按顺序叠加各个阶段,每个阶段由一个从上一阶段提取的特征图和相应的主干网络层组成。合并过程由下列方程定义:

输出层: 第五个合并阶段之后,得到一个新的特征图,其size为原始输入图像的1/2;然后,增加上采样层和2个卷积层产生最终的像素级预测输出层P:

输出层P特征图size是(BatchSize,7,h,w)。其中,文本中心线(TCL,Text Center Line)2个通道、文本区域(TR,Text Region)2个通道,圆盘的几何属性(r、cosθ和sinθ)3个通道。

2.4 前向传播
首先,在前向传播之后,网络输出层生成TCL、TR和几何图属性。对于TCL和TR的后处理,分别采用Ttcl和Ttr值阈值操作;然后,利用TR与TCL的交集(消除噪点)给出TCL的最终预测;最后,基于striding算法重构文本区域。
striding算法:提取一个表示文本实例形状和过程的有序点列表,对文本实例区域进行重构。首先采用两种简单的启发式算法对false positive文本实例进行过滤:
(1) TCL像素数至少为其平均半径的0.2倍,否则滤除;
(2) 预测的文本区域与TR的交集,至少是TR的一半,否则滤除。
后处理算法框架:


act (a) centralizing:将给定的点重新定位到中轴;如图6所示,随机选择TCL上的一个点,画出切线(虚线)和法线(实线),通过法线与TCL区域交点的中点获得中点。
act(b) striding算法:该算法向下一个搜索点迈出一大步,分别朝向文本实例的两个末端方向搜索;每一步位移的计算方式为
。如果下一步是在TCL区域之外,则逐渐减少步幅,直到它在区域内,或到达末端。
act(c) sliding算法:该算法在中轴线上迭代并沿中轴线绘制圆圈,圆的半径是r。圆圈所涵盖的区域表示预测的文本实例。
2.5 生成标签

文本中心线:本文方法也依赖一个前提假设,即假设文本实例是蛇形的,不会分叉到多个分支。对于蛇形文本实例,它有两个边,分别是头部和尾部,即如图7(a)中的AH和DE(底边)。头部或尾部附近的两条边是平行的,但方向相反,如图7(a)中的AB和GH。
a. 确定底边
由一组顶点{v0,v1,v2,…,vn}按顺时针或逆时针顺序表示文本实例t,确定一条边ei,i+1是底边的度量方式是旁边的两条边夹角是180度,公式化为:
![]()
b.采样锚点
对两个边线(ABCD和HGFE)上采样相同数量的锚点(anchor points);
c.计算TCL点
计算 TCL点,即为两条边线上相应锚点的中点。另外,将TCL的两端缩小1/2 r(两端TCL点的半径)像素,这可以令TCL位于TR内,并使网络更容易学习两个相邻的文本实例。又因为单点线容易产生噪声,所以本文将TCL的面积扩大1/5 r。
计算r和θ:r是利用边线上对应点的距离计算获得的;
θ是利用相邻的TCL点连接成一条直线来计算获得的。对于非TCL像素,将其相应的几何属性设置为0。
2.6 损失函数
以下列损失函数为目标的端到端训练:

其中,Lcls代表TR和TCL的分类损失,Lreg代表r、cosθ和sinθ的回归损失;Ltr和Ltcl分别是TR和TCL的交叉熵损失;Lr, Lsin和Lcos为smooth-L1损失:
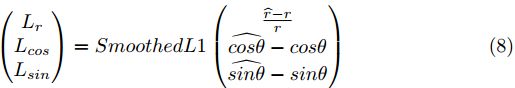
权重常数λ1、λ2、λ3、λ4和λ5都设置为1。
3. 实验
3.1 数据集
实验数据集包括:SynthText、TotalText、CTW1500、ICDAR2015、MSRA-TD500.
其中,使用SynthText数据集预训练模型。
3.2 数据增强
a. 图像随机旋转;
b. 图像随机裁剪,裁剪面积从0.24到1.69,纵横比从0.33到3;
c. 随机调整噪声、模糊度和亮度,并确保增强图像上的文本仍然清晰。
3.3 训练参数
本文方法是基于TensorFlow 1.3.0框架实现,该网络首先在SynthText数据集预训练一个epoch,然后在其他数据集进行fine-tuned;采用Adam优化算法;在预训练阶段,学习率固定在e−3;在fine-tuning阶段,学习速率最初设置为e−3,每5000次迭代的学习速率衰减0.8倍。
3.4 实验结果

上图为不同数据集的预测情况,上面四个图中的黄色框为预测框,绿色框为标注框;下面四个图是得分特征图,其中TR是红色区域,TCL是黄色区域。
以Total-Text和CTW1500数据集训练为例:
这两个数据集fine-tuning 迭代5k次,阈值Ttr和Ttcl分别设置为(0.4,0.6)和(0.4,0.5)。在测试中,Total-Text图像被resize为512×512,而对于CTW 1500,由于CTW 1500中的图像相当小,则不resize。

4. 算法分析
本文的方法能够精确地预测文本实例的形状和过程,主要原因在于TCL机制,文本中心线可以看作是支撑文本实例的骨架,几何属性在其之上提供更多的细节。优点如下:
(1) 较小的TCL能够更好地描述文本实例的过程和形状;
(2) TCL从直观上来看并不重叠,使得实例分割可以非常简单、直观,从而简化了pipeline。
5. 代码实现