吴恩达机器学习笔记之支持向量机
优化目标(Optimization Objective):
Support Vector Machines(SVMs)支持向量机是一种非常强大的算法,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。我们首先从优化目标开始一步一步认识SVMs,首先从逻辑回归的优化目标开始:
下图是逻辑回归中的假设函数-sigmoid函数,

我们已经清楚的知道逻辑回归的优化目标,下图表示的为一个样本对于总体优化目标的贡献:

图中紫红色的线表示的SVMs的优化目标中对逻辑回归的一点修改,我们通过去除m,并且通过系数调整,让正则化项中的lambda变成1,在前面的代价函数中增加系数C,这样的目的只是为了换一种形式表达,其物理意义还是通过C的值来改变代价函数或者正则项在优化目标中的权重。得到的SVMs的优化目标如下所示:

另外,值得注意的是SVMs输出的结果不像逻辑回归一样是概率,而是直接输出是0或者是1,学习参数theta就是SVMs的假设函数形式。

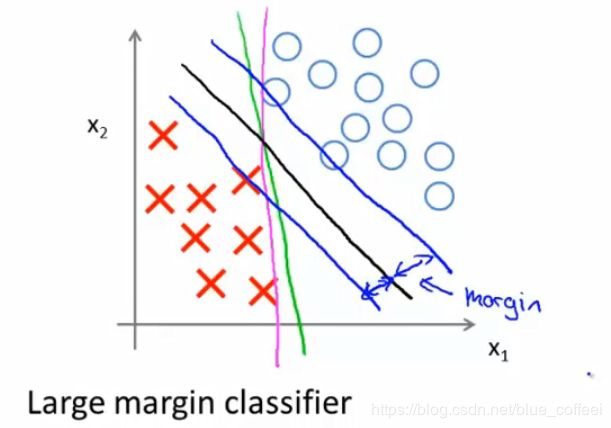
直观上对大间隔的理解(Large Margin Intuition):
SVMs也被叫做大间距分类器,意思是SVMs会以最大的间隔来分离正负样本,如下图所示,绿色和粉红色的线虽然可以将样本分开,但是如果用大间距分类,得到的结果是中间那条黑色的线,可以看到与黑色的线平行的两条绿色的线,虽然也可以分离样本,但是不符合最大间距的思想。这也是为什么当C设置非常大的时候,把它叫做大间距分类器的原因。
但是如果分类之后出现了一个异常的数据,比如下图左下角的红叉,那么如果我们还将C设置的非常大的话,即还是使用大间距分类的话,那么我们的决策边界就会由黑色的线变成粉红色的线,但是这不是一个好主意。那么有趣的是,SVMs做的其实远不止大间距分类,这个时候如果我们不在把C设置的很大,而是一个相对来说足够小的数,那么我们SVMs得到的决策边界就仍然是黑色的那条线。对于非线性可分的数据集,我们的SVMs也能将数据集进行很好的划分。
这只是为了让我们对大间距分类有一个更直观的印象和了解,这里的参数C我们可以将它的作用想象成1/lambda,当C很大时,对应的是lambda很小,C很小时,对应的是lambda很大。

大间隔分类的数学原理:
首先复习一下向量内积的性质:
假设有两个向量u,v做内积,那么他们的内积为p*||u||,p为v在u上的投影,注意p可以是负值,当u和v之间的夹角大于90度时为负值,||u||表示向量u的范数,即向量u的长度。

下面我们用向量内积的性质来看一看大间距分类在做些什么。我们先假设只有两个特征值,并且为了便于分析,我们先忽略截距![]() ,于是我们可以将我们的约束条件
,于是我们可以将我们的约束条件![]() 转换为
转换为![]() ||
||![]() ||。
||。

于是我们得到下面的结果,我们优化目标是最小化![]() 的范数,接下来我们看一个例子,如下图所示,我们的SVMs会怎样选择决策边界呢,首先看左下图的绿色的线,如果选择这条线作为我们的决策边界,我们知道,我们的
的范数,接下来我们看一个例子,如下图所示,我们的SVMs会怎样选择决策边界呢,首先看左下图的绿色的线,如果选择这条线作为我们的决策边界,我们知道,我们的![]() 是垂直于我们的决策边界的,因此对于一个正样本来说,我们的约束条件为
是垂直于我们的决策边界的,因此对于一个正样本来说,我们的约束条件为![]() ||
||![]() ||
||![]() 1,但是可以看出,此时的
1,但是可以看出,此时的![]() 非常小,因此对应的,为了满足条件我们就必须增大||
非常小,因此对应的,为了满足条件我们就必须增大||![]() ||的值,但是我们优化目标是最小化||
||的值,但是我们优化目标是最小化||![]() ||的值,因此发生矛盾。所以我们的大间距分类是不会选择这条决策边界的。而右下角的图就正好展示了我们选择的决策边界,它将满足使得我们的||
||的值,因此发生矛盾。所以我们的大间距分类是不会选择这条决策边界的。而右下角的图就正好展示了我们选择的决策边界,它将满足使得我们的||![]() ||最小。换句话说,SVMs的目标就是寻找尽可能大的
||最小。换句话说,SVMs的目标就是寻找尽可能大的![]() ,也就对应了所谓margin,这也就是大间距分类的由来。可以证明,当
,也就对应了所谓margin,这也就是大间距分类的由来。可以证明,当![]()
![]() 0,结论也是成立的。
0,结论也是成立的。

核函数(Kernels):
构造复杂的非线性分类器,回忆之前的如果要得到下图所示的决策边界,我们会用更高次项的多项式来表示,在这里我们换一种表示方式,即令![]() ,
,![]() 等等,从而引发一个思考,我们是否可以选择另一种方式来定义我们的
等等,从而引发一个思考,我们是否可以选择另一种方式来定义我们的![]() ?
?

首先假设我们选出三个点(怎么选择在后面会说明),然后我们定义我们的样本与这些选定点的相似度作为我们新的特征,
![]() ,这种相似关系的度量就是我们的核函数,在这里这种形式叫做高斯核函数,还有其他类型的核函数,在后面也会提及到。
,这种相似关系的度量就是我们的核函数,在这里这种形式叫做高斯核函数,还有其他类型的核函数,在后面也会提及到。

下图是这个核函数的图像,我们去样本x和标记点![]() 进行分析,当x和
进行分析,当x和![]() 的距离很近时,则核函数的输出为1,当x和
的距离很近时,则核函数的输出为1,当x和![]() 的距离很远时,核函数的输出为0.这也可以直观的说明为什么叫相似性函数。下图我们还比较了不同的
的距离很远时,核函数的输出为0.这也可以直观的说明为什么叫相似性函数。下图我们还比较了不同的![]() 对图像造成的印象,当
对图像造成的印象,当![]() 减小时,图像会变得尖锐一些,这时我们的结果是有低偏差,高方差;当
减小时,图像会变得尖锐一些,这时我们的结果是有低偏差,高方差;当![]() 变大时,图像会变得平滑一些,此时的结果是有高偏差,低方差。
变大时,图像会变得平滑一些,此时的结果是有高偏差,低方差。

下图展示了我们核函数的工作原理,当我们选定三个标记点![]() 、
、![]() 、
、![]() 后,如果对于靠近
后,如果对于靠近![]() 、
、![]() 的点,我们的输出为1,对于靠近
的点,我们的输出为1,对于靠近![]() 的点,我们的输出为零,那么我们就可以画出如下图所示的决策边界。
的点,我们的输出为零,那么我们就可以画出如下图所示的决策边界。

那么我们应该如何选择这些标记点呢?方法是我们将我们所有的数据集里的点都作为我们的标记点,这样的好处是,我们得到的新特征是建立在原有特征与训练集中所有其他特征之间的距离的基础上的。


然后我们将我们的核函数带入我们的SVMs中:


如果我们使用的核函数是高斯核函数,那么进行特征缩放是非常必要的。另外,我们的SVMs还可以不使用核函数,不使用核函数我们称之为线性核函数。当我们不采用复杂的函数时,或者我们训练集的特征值的数量非常多而实例非常少的时候,我们就可以使用这种不带核函数的SVMs。
使用SVM:
我们在实际中使用SVM的时候,有很多优化包可以使用, 比如liblinear 和 libsvm,但是都需要我们自己编写核函数,如下图所示:

高斯核函数和线性核函数是最常见的核函数。其他的核函数还有:多项式核函数(Polynomial Kernel)、字符串核函数(String kernel)、卡方核函数( chi-square kernel)、直方图交集核函数(histogram intersection kernel)。在进行高斯核函数之前,记得要进行特征缩放。所有的核函数都要满足默塞尔定理,才能被SVM的优化包正确使用。
如何选择逻辑回归还是SVM:假设n表示特征的数量,m表示训练样本的数量
(1)如果相较于m而言,n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果n较小,而且m大小中等,例如n在 1-1000 之间,而m在 10-10000 之间,使用高斯核函数的支持向量机。
(3)如果n较小,而m较大,例如n在 1-1000 之间,而m大于 50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。