分布式爬虫很难吗?用Python写一个小白也能听懂的分布式知乎爬虫

前言
很早就有采集知乎用户数据的想法,要实现这个想法,需要写一个网络爬虫(Web Spider)。因为在学习 python,正好 python 写爬虫也是极好的选择,于是就写了一个基于 python 的网络爬虫。
几个月前写了爬虫的初版,后来因为一些原因,暂时搁置了下来,最近重新拾起这个想法。首先优化了代码的结构,然后在学弟的提醒下,从多线程改成了多进程,一台机器上运行一个爬虫程序,会启动几百个子进程加速抓取。
但是一台机器的性能是有极限的,所以后来我使用 MongoDB 和 Redis 搭建了一个主从结构的分布式爬取系统,来进一步加快抓取的速度。
然后我就去好几个服务器厂商申请免费的试用,比如百度云、腾讯云、Ucloud…… 加上自己的笔记本,断断续续抓取了一个多周,才采集到300万知乎用户数据。中间还跑坏了运行网站的云主机,还好 自动备份 起作用,数据没有丢失,但那又是另外一个故事了……
废话不多说,下面我介绍一下如何写一个简单的分布式知乎爬虫。
抓取知乎用户的个人信息
给大家推荐一个学习交流的地方,想要学习Python的小伙伴可以一起来学习,719+139+688,入坑需谨慎,对Python没啥兴趣的就不要来凑热闹啦。我们要抓取知乎用户数据,首先要知道在哪个页面可以抓取到用户的数据。知乎用户的个人信息在哪里呢,当然是在用户的主页啦,我们以轮子哥为例 ~

红框里的便我们要抓取的用户关键信息(的一部分)。
最上面是我们的目标URL:https://www.zhihu.com/people/excited-vczh/answers。
观察一下这个URL的组成:
http://www.zhihu.com + /people + /excited-vczh + /answer
可以发现只有 excited-vczh 这部分是会变化的,它代表着知乎用户的唯一ID,在知乎的数据格式中,它的键名叫做 urlToken。
所以我们可以用拼接字符串的形式,得到我们待抓取页面的URL:
url = '%s/people/%s/answers'%(host,urlToken)
页面URL有了,而且从上图我们可以发现 不登录 也可以访问用户主页,这说明我们可以不用考虑模拟登陆的问题,可以自由的获取用户主页面源码。
那么我们如何从用户主页的源码中获取用户的数据呢?一开始我以为需要挨个匹配页面中对应的部分,但我查看源码的时候发现知乎把用户数据集集中放到了源码的一个地方,那就是 id="data" 的 div 的 data-state 属性的值中,看下图:

从上图我们可以发现,date-state 的属性值中藏有用户的信息,比如我们可以依次找到用户的教育经历(educations)、简介(headline)、参与的 Live 数量(participatedLiveCount)、关注的收藏夹数量(followingFavlistsCount)、被收藏的次数(favoritedCount)、关注他的用户数(followerCount)、关注的话题数量(followingTopicCount)、用户描述(description)等信息。通过观察我们也可以发现,数据应该是以 JSON 格式存储。
知道了用户数据都藏在 date-state 中,我们 用 BeautifulSoup 把该属性的值取出来,然后作为 JSON 格式读取,再把数据集中存储用户数据的部分提取出来即可,看代码:
# 解析htmls = BS(html,'html.parser')# 获得该用户藏在主页面中的json格式数据集data = s.find('div',attrs={'id':'data'})['data-state']
data = json.loads(data)
data = data['entities']['users'][urlToken]
如此,我们便得到了某一个用户的个人信息。
抓取知乎用户的关注者列表
刚刚我们讨论到可以通过抓取用户主页面源码来获取个人信息,而用户主页面可以通过拼接字符串的形式得到 URL,其中拼接的关键是 如何获取用户唯一ID —— urlToken?
我采用的方法是 抓取用户的关注者列表。
每个用户都会有关注者列表,比如轮子哥的:

请点击此处输入图片描述

和获取个人信息同样的方法,我们可以在该页面源码的 date-state 属性值中找到关注他的用户(一部分):

请点击此处输入图片描述
名为 ids 的键值中存储有当前列表页的所有用户的 urlToken,默认列表的每一页显示20个用户,所以我们写一个循环便可以获取当前页该用户的所有关注者的 urlToken。
# 解析当前页的 html url = '%s/people/%s/followers?page=%d'%(host,urlToken,page)
html = c.get_html(url)
s = BS(html,'html.parser')# 获得当前页的所有关注用户data = s.find('div',attrs={'id':'data'})['data-state']
data = json.loads(data)
items = data['people']['followersByUser'][urlToken]['ids']for item in items: if item!=None and item!=False and item!=True and item!='知乎用户'.decode('utf8'):
node = item.encode('utf8')
follower_list.append(node)
再写一个循环遍历关注者列表的所有页,便可以获取用户的所有关注者的 urlToken。
有了每个用户在知乎的唯一ID,我们便可以通过拼接这个ID得到每个用户的主页面URL,进一步获取到每个用户的个人信息。
我选择抓取的是用户的关注者列表,即关注这个用户的所有用户(follower)的列表,其实你也可以选择抓取用户的关注列表(following)。我希望抓取更多知乎非典型用户(潜水用户),于是选择了抓取关注者列表。当时抓取的时候有这样的担心,万一这样抓不到主流用户怎么办?毕竟很多知乎大V虽然关注者很多,但是主动关注的人相对都很少,而且关注的很可能也是大V。但事实证明,主流用户基本都抓取到了,看来基数提上来后,总有缝隙出现。
反爬虫机制
频繁抓取会被知乎封IP,也就是常说的反爬虫手段之一,不过俗话说“道高一尺,魔高一丈”,既然有反爬虫手段,那么就一定有反反爬虫手段,咳,我自己起的名……
言归正传,如果知乎封了你的IP,那么怎么办呢?很简单,换一个IP。这样的思想催生了 代理IP池 的诞生。所谓代理IP池,是一个代理IP的集合,使用代理IP可以伪装你的访问请求,让服务器以为你来自不同的机器。
于是我的 应对知乎反爬虫机制的策略 就很简单了:全力抓取知乎页面 --> 被知乎封IP --> 换代理IP --> 继续抓 --> 知乎继续封 --> 继续换 IP..... (手动斜眼)
使用 代理IP池,你可以选择用付费的服务,也可以选择自己写一个,或者选择用现成的轮子。我选择用七夜写的 qiyeboy/IPProxyPool 搭建代理池服务,部署好之后,修改了一下代码让它只保存https协议的代理IP,因为 使用http协议的IP访问知乎会被拒绝。
搭建好代理池服务后,我们便可以随时在代码中获取以及使用代理 IP 来伪装我们的访问请求啦!
(其实反爬手段有很多,代理池只是其中一种)
简单的分布式架构
多线程/多进程只是最大限度的利用了单台机器的性能,如果要利用多台机器的性能,便需要分布式的支持。
如何搭建一个简单的分布式爬虫?
我采用了 主从结构,即一台主机负责调度、管理待抓取节点,多台从机负责具体的抓取工作。
具体到这个知乎爬虫来说,主机上搭建了两个数据库:MongoDB 和 Redis。MongoDB 负责存储抓取到的知乎用户数据,Redis 负责维护待抓取节点集合。从机上可以运行两个不同的爬虫程序,一个是抓取用户关注者列表的爬虫(list_crawler),一个是抓取用户个人资料的爬虫(info_crawler),他们可以配合使用,但是互不影响。
我们重点讲讲主机上维护的集合,主机的 Redis 数据库中一共维护了5个集合:
-
waiting:待抓取节点集合
-
info_success:个人信息抓取成功节点集合
-
info_failed:个人信息抓取失败节点集合
-
list_success:关注列表抓取成功节点集合
-
list_failed:关注列表抓取失败节点集合
这里插一句,之所以采用集合(set),而不采用队列(queue),是因为集合天然的带有唯一性,也就是说可以加入集合的节点一定是集合中没有出现过的节点,这里在5个集合中流通的节点其实是 urlToken。
(其实集合可以缩减为3个,省去失败集合,失败则重新投入原来的集合,但我为了测速所以保留了5个集合的结构)
他们的关系是:
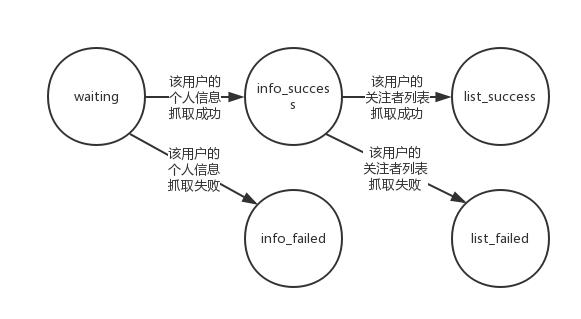
请点击此处输入图片描述
举个具体的栗子:从一个 urlToken 在 waiting 集合中出现开始,经过一段时间,它被 info_crawler 爬虫程序从 waiting 集合中随机获取到,然后在 info_crawler 爬虫程序中抓取个人信息,如果抓取成功将个人信息存储到主机的 MongoDB 中,将该 urlToken 放到 info_success 集合中;如果抓取失败则将该 urlToken 放置到 info_failed 集合中。下一个阶段,经过一段时间后,list_crawler 爬虫程序将从 info_success 集合中随机获取到该 urlToken,然后尝试抓取该 urlToken 代表用户的关注者列表,如果关注者列表抓取成功,则将抓取到的所有关注者放入到 waiting 集合中,将该 urlToken 放到 list_success 集合中;如果抓取失败,将该 urlToken 放置到 list_failed 集合中。
如此,主机维护的数据库,配合从机的 info_crawler 和 list_crawler 爬虫程序,便可以循环起来:info_crawler 不断从 waiting 集合中获取节点,抓取个人信息,存入数据库;list_crawler 不断的补充 waiting 集合。
主机和从机的关系如下图:

主机是一台外网/局域网可以访问的“服务器”,从机可以是PC/笔记本/Mac/服务器,这个架构可以部署在外网也可以部署在内网。