1、残差
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。在集成学习中可以通过基模型拟合残差,使得集成的模型变得更精确;在深度学习中也有人利用layer去拟合残差将深度神经网络的性能提高变强。这里笔者选了Gradient Boosting和Resnet两个算法试图让大家更感性的认识到拟合残差的作用机理。
2、Gradient Boosting
Gradient Boosting模型大致可以总结为三部:
- 训练一个基学习器Tree_1(这里采用的是决策树)去拟合data和label。
- 接着训练一个基学习器Tree_2,输入时data,输出是label和上一个基学习器Tree_1的预测值的差值(残差),这一步总结下来就是使用一个基学习器学习残差。
- 最后把所有的基学习器的结果相加,做最终决策。
下方代码仅仅做了3步的残差拟合,最后一步就是体现出集成学习的特征,将多个基学习器组合成一个组合模型。
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X, y)
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X, y2)
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X, y3)
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))其实上方代码就等价于调用sklearn中的GradientBoostingRegressor这个集成学习API,同时将基学习器的个数n_estimators设为3。
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
gbrt.fit(X, y)形象的理解Gradient Boosting,其的过程就像射箭多次射向同一个箭靶,上一次射的偏右,下一箭就会尽量偏左一点,就这样慢慢调整射箭的位置,使得箭的位置和靶心的偏差变小,最终射到靶心。这也是boosting的集成方式会减小模型bias的原因。
残差网络的作用:
(1)为什么残差学习的效果会如此的好?与其他论文相比,深度残差学习具有更深的网络结构,此外,残差学习也是网络变深的原因?为什么网络深度如此的重要?
解:一般认为神经网络的每一层分别对应于提取不同层次的特征信息,有低层,中层和高层,而网络越深的时候,提取到的不同层次的信息会越多,而不同层次间的层次信息的组合也会越多。
(2)为什么在残差之前网络的深度最深的也只是GoogleNet 的22 层, 而残差却可以达到152层,甚至1000层?
解:深度学习对于网络深度遇到的主要问题是梯度消失和梯度爆炸,传统对应的解决方案则是数据的初始化(normlized initializatiton)和(batch normlization)正则化,但是这样虽然解决了梯度的问题,深度加深了,却带来了另外的问题,就是网络性能的退化问题,深度加深了,错误率却上升了,而残差用来设计解决退化问题,其同时也解决了梯度问题,更使得网络的性能也提升了。
残差网络的基本结构:
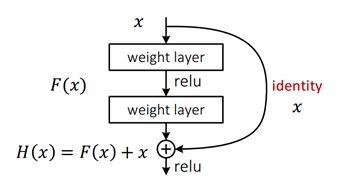
将输入叠加到下层的输出上。对于一个堆积层结构(几层堆积而成)当输入为x时其学习到的特征记为H(x),现在我们希望其可以学习到残差F(x)=H(x)-x,这样其实原始的学习特征是F(x)+x 。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。
对着下方代码我们可以更清晰的看到residual block的具体操作:
- 输入x,
- 将x通过三层convolutiaon层之后得到输出m,
- 将原始输入x和输出m加和。
就得到了residual block的总输出,整个过程就是通过三层convolutiaon层去拟合residual block输出与输出的残差m。
from keras.layers import Conv2D
from keras.layers import add
def residual_block(x, f=32, r=4):
"""
residual block
:param x: the input tensor
:param f: the filter numbers
:param r:
:return:
"""
m = conv2d(x, f // r, k=1)
m = conv2d(m, f // r, k=3)
m = conv2d(m, f, k=1)
return add([x, m])在resnet中残差的思想就是去掉相同的主体部分,从而突出微小的变化,让模型集中注意去学习一些这些微小的变化部分。这和我们之前讨论的Gradient Boosting中使用一个基学习器去学习残差思想几乎一样。
3、slim库
要学习残差网络,先学习slim库的用法。
首先让我们看看tensorflow怎么实现一个层,例如卷积层:
input = ...
with tf.name_scope('conv1_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 128], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(input, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
然后slim的实现:
input = ...
net = slim.conv2d(input, 128, [3, 3], scope='conv1_1')但这个不是重要的,因为tenorflow目前也有大部分层的简单实现,这里比较吸引人的是slim中的repeat和stack操作:
假设定义三个相同的卷积层:
net = ...
net = slim.conv2d(net, 256, [3, 3], scope='conv3_1')
net = slim.conv2d(net, 256, [3, 3], scope='conv3_2')
net = slim.conv2d(net, 256, [3, 3], scope='conv3_3')
net = slim.max_pool2d(net, [2, 2], scope='pool2')在slim中的repeat操作可以减少代码量:
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool2')而stack是处理卷积核或者输出不一样的情况:
假设定义三层FC:
x = slim.fully_connected(x, 32, scope='fc/fc_1')
x = slim.fully_connected(x, 64, scope='fc/fc_2')
x = slim.fully_connected(x, 128, scope='fc/fc_3')使用stack操作:
slim.stack(x, slim.fully_connected, [32, 64, 128], scope='fc')
同理卷积层也一样:
# 普通方法:
x = slim.conv2d(x, 32, [3, 3], scope='core/core_1')
x = slim.conv2d(x, 32, [1, 1], scope='core/core_2')
x = slim.conv2d(x, 64, [3, 3], scope='core/core_3')
x = slim.conv2d(x, 64, [1, 1], scope='core/core_4')
# 简便方法:
slim.stack(x, slim.conv2d, [(32, [3, 3]), (32, [1, 1]), (64, [3, 3]), (64, [1, 1])], scope='core')采用如上方法,定义一个VGG也就十几行代码的事了。
def vgg16(inputs):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
net = slim.fully_connected(net, 4096, scope='fc6')
net = slim.dropout(net, 0.5, scope='dropout6')
net = slim.fully_connected(net, 4096, scope='fc7')
net = slim.dropout(net, 0.5, scope='dropout7')
net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc8')
return net这个没什么好说的,说一下直接拿经典网络来训练吧。
import tensorflow as tf
vgg = tf.contrib.slim.nets.vgg
# Load the images and labels.
images, labels = ...
# Create the model.
predictions, _ = vgg.vgg_16(images)
# Define the loss functions and get the total loss.
loss = slim.losses.softmax_cross_entropy(predictions, labels)【注】slim的卷积层默认是SAME模式的padding,这也就意味着卷积之后和卷积之前的大小相同。残差网络恰好需要这个特性。
4、残差网络模型
编写残差网络单元
import tensorflow as tf
import tensorflow.contrib.slim as slim
def resnet_block(inputs,ksize,num_outputs,i):
with tf.variable_scope('res_unit'+str(i)) as scope:
part1 = slim.batch_norm(inputs,activation_fn=None)
part2 = tf.nn.elu(part1)
part3 = slim.conv2d(part2,num_outputs,[ksize,ksize],activation_fn=None)
part4 = slim.batch_norm(part3,activation_fn=None)
part5 = tf.nn.elu(part4)
part6 = slim.conv2d(part5,num_outputs,[ksize,ksize],activation_fn=None)
output = part6 + inputs
return output
def resnet(X_input,ksize,num_outputs,num_classes,num_blocks):
layer1 = slim.conv2d(X_input,num_outputs,[ksize,ksize],normalizer_fn=slim.batch_norm,scope='conv_0')
for i in range(num_blocks):
layer1 = resnet_block(layer1,ksize,num_outputs,i+1)
top = slim.conv2d(layer1,num_classes,[ksize,ksize],normalizer_fn=slim.batch_norm,activation_fn=None,scope='conv_top')
top = tf.reduce_mean(top,[1,2])
output = slim.layers.softmax(slim.layers.flatten(top))
return output
5、训练网络
import tensorflow as tf
import tensorflow.contrib.slim as slim
from scrips import config
from scrips import resUnit
from scrips import read_tfrecord
from scrips import convert2onehot
import numpy as np
log_dir = config.log_dir
model_dir = config.model_dir
IMG_W = config.IMG_W
IMG_H = config.IMG_H
IMG_CHANNELS = config.IMG_CHANNELS
NUM_CLASSES = config.NUM_CLASSES
BATCH_SIZE = config.BATCH_SIZE
tf.reset_default_graph()
X_input = tf.placeholder(shape=[None,IMG_W,IMG_H,IMG_CHANNELS],dtype=tf.float32,name='input')
y_label = tf.placeholder(shape=[None,NUM_CLASSES],dtype=tf.int32)
#*****************************************************************************************************
output = resUnit.resnet(X_input,3,64,NUM_CLASSES,5)
#*****************************************************************************************************
#loss and accuracy
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=output))
train_step = tf.train.AdamOptimizer(config.lr).minimize(loss)
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y_label, 1), tf.argmax(output, 1)), tf.float32))
#tensor board
tf.summary.scalar('loss',loss)
tf.summary.scalar('accuracy',accuracy)
#从tfrecord中读取数据及对应的标签
image, label = read_tfrecord.read_and_decode(config.tfrecord_dir,IMG_W,IMG_H,IMG_CHANNELS)
image_batches, label_batches = tf.train.shuffle_batch([image, label], batch_size=BATCH_SIZE, capacity=2000,min_after_dequeue=1000)
#训练网络
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(model_dir)#从中间模型加载权重
if ckpt and ckpt.model_checkpoint_path:
print('Restore model from ',end='')
print(ckpt.model_checkpoint_path)
saver.restore(sess,ckpt.model_checkpoint_path)
if (ckpt.model_checkpoint_path.split('-')[-1]).isdigit():
global_step = int(ckpt.model_checkpoint_path.split('-')[-1])
print('Restore step at #',end='')
print(global_step)
else:
global_step = 0
else:
global_step = 0
sess.run(init)
tensor_board_writer = tf.summary.FileWriter(log_dir,tf.get_default_graph())
merged = tf.summary.merge_all()
#sess.graph.finalize()
threads = tf.train.start_queue_runners(sess=sess)
while True:
try:
global_step += 1
X_train, y_train = sess.run([image_batches, label_batches])
y_train_onehot = convert2onehot.one_hot(y_train,NUM_CLASSES)
feed_dict = {X_input: X_train, y_label: y_train_onehot}
[_, temp_loss, temp_accuracy,summary] = sess.run([train_step, loss, accuracy,merged], feed_dict=feed_dict)
tensor_board_writer.add_summary(summary,global_step)
if global_step % config.display == 0:
print('step at #{},'.format(global_step), end=' ')
print('train loss: {:.5f}'.format(temp_loss), end=' ')
print('train accuracy: {:.2f}%'.format(temp_accuracy * 100))
if global_step % config.snapshot== 0:
saver.save(sess,model_dir+'/model.ckpt',global_step)
except:
tensor_board_writer.close()
break;