如何解决多线程高并发场景下的 Java 缓存问题?


作者 | LLLSQ
责编 | 郭芮
互联网软件神速发展,用户的体验度是判断一个软件好坏的重要原因,所以缓存就是必不可少的一个神器。在多线程高并发场景中往往是离不开cache的,需要根据不同的应用场景来需要选择不同的cache,比如分布式缓存如redis、memcached,还有本地(进程内)缓存如ehcache、GuavaCache、Caffeine。
说起Guava Cache,很多人都不会陌生,它是Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略。由于Guava的大量使用,Guava Cache也得到了大量的应用。但是,Guava Cache的性能一定是最好的吗?也许,曾经,它的性能是非常不错的。但所谓长江后浪推前浪,总会有更加优秀的技术出现。今天,我就来介绍一个比Guava Cache性能更高的缓存框架:Caffeine。
![]()
官方性能比较
Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略。
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。
Caffeine是使用Java8对Guava缓存的重写版本,在Spring Boot 2.0中将取代,基于LRU算法实现,支持多种缓存过期策略。
场景1:8个线程读,100%的读操作。
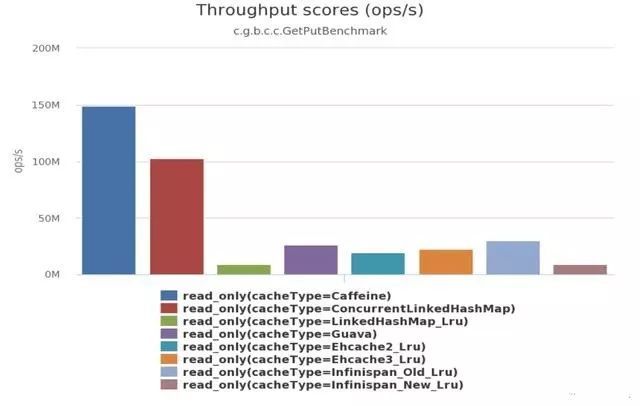
场景二:6个线程读,2个线程写,也就是75%的读操作,25%的写操作。

场景三:8个线程写,100%的写操作。

可以清楚地看到Caffeine效率明显高于其他缓存。
![]()
如何使用?
1 public static void main(String[] args) {
2 LoadingCache<String, String> build = CacheBuilder.newBuilder().initialCapacity(1).maximumSize(100).expireAfterWrite(1, TimeUnit.DAYS)
3 .build(new CacheLoader<String, String>() {
4 //默认的数据加载实现,当调用get取值的时候,如果key没有对应的值,就调用这个方法进行加载
5 @Override
6 public String load(String key) {
7 return "";
8 }
9 });
10 }
11 }
参数方法:
initialCapacity(1) 初始缓存长度为1;
maximumSize(100) 最大长度为100;
expireAfterWrite(1, TimeUnit.DAYS) 设置缓存策略在1天未写入过期缓存(后面讲缓存策略)。
![]()
过期策略
在Caffeine中分为两种缓存,一个是有界缓存,一个是无界缓存,无界缓存不需要过期并且没有界限。
在有界缓存中提供了三个过期API:
expireAfterWrite:代表着写了之后多久过期。(上面列子就是这种方式)
expireAfterAccess:代表着最后一次访问了之后多久过期。
expireAfter:在expireAfter中需要自己实现Expiry接口,这个接口支持create、update、以及access了之后多久过期。注意这个API和前面两个API是互斥的。这里和前面两个API不同的是,需要你告诉缓存框架,它应该在具体的某个时间过期,也就是通过前面的重写create、update、以及access的方法,获取具体的过期时间。
![]()
更新策略
何为更新策略?就是在设定多长时间后会自动刷新缓存。
Caffeine提供了refreshAfterWrite()方法来让我们进行写后多久更新策略:
1 LoadingCache<String, String> build = CacheBuilder.newBuilder().refreshAfterWrite(1, TimeUnit.DAYS)
2 .build(new CacheLoader<String, String>() {
3 @Override
4 public String load(String key) {
5 return "";
6 }
7 });
8 }上面的代码我们需要建立一个CacheLodaer来进行刷新,这里是同步进行的,可以通过buildAsync方法进行异步构建。在实际业务中这里可以把我们代码中的mapper传入进去,进行数据源的刷新。
但是实际使用中,你设置了一天刷新,但是一天后你发现缓存并没有刷新。这是因为只有在1天后这个缓存再次访问后才能刷新,如果没人访问,那么永远也不会刷新。
我们来看看自动刷新是怎么做的呢?自动刷新只存在读操作之后,也就是我们的afterRead()这个方法,其中有个方法叫refreshIfNeeded,它会根据你是同步还是异步然后进行刷新处理。
![]()
填充策略(Population)
Caffeine 为我们提供了三种填充策略:手动、同步和异步。
手动加载(Manual)
1Cache<String, Object> manualCache = Caffeine.newBuilder()
2 .expireAfterWrite(10, TimeUnit.MINUTES)
3 .maximumSize(10_000)
4 .build();
5
6String key = "name1";
7// 根据key查询一个缓存,如果没有返回NULL
8graph = manualCache.getIfPresent(key);
9// 根据Key查询一个缓存,如果没有调用createExpensiveGraph方法,并将返回值保存到缓存。
10// 如果该方法返回Null则manualCache.get返回null,如果该方法抛出异常则manualCache.get抛出异常
11graph = manualCache.get(key, k -> createExpensiveGraph(k));
12// 将一个值放入缓存,如果以前有值就覆盖以前的值
13manualCache.put(key, graph);
14// 删除一个缓存
15manualCache.invalidate(key);
16
17ConcurrentMap<String, Object> map = manualCache.asMap();
18cache.invalidate(key);Cache接口允许显式的去控制缓存的检索、更新和删除。我们可以通过cache.getIfPresent(key) 方法来获取一个key的值,通过cache.put(key, value)方法显示的将数控放入缓存,但是这样子会覆盖缓原来key的数据。更加建议使用cache.get(key,k - > value) 的方式,get 方法将一个参数为 key 的 Function (createExpensiveGraph) 作为参数传入。
如果缓存中不存在该键,则调用这个 Function 函数,并将返回值作为该缓存的值插入缓存中。get 方法是以阻塞方式执行调用,即使多个线程同时请求该值也只会调用一次Function方法。这样可以避免与其他线程的写入竞争,这也是为什么使用 get 优于 getIfPresent 的原因。
注意:如果调用该方法返回NULL(如上面的 createExpensiveGraph 方法),则cache.get返回null。如果调用该方法抛出异常,则get方法也会抛出异常。
可以使用Cache.asMap() 方法获取ConcurrentMap进而对缓存进行一些更改。
同步加载(Loading)
1LoadingCache<String, Object> loadingCache = Caffeine.newBuilder()
2 .maximumSize(10_000)
3 .expireAfterWrite(10, TimeUnit.MINUTES)
4 .build(key -> createExpensiveGraph(key));
5
6String key = "name1";
7// 采用同步方式去获取一个缓存和上面的手动方式是一个原理。在build Cache的时候会提供一个createExpensiveGraph函数。
8// 查询并在缺失的情况下使用同步的方式来构建一个缓存
9Object graph = loadingCache.get(key);
10
11// 获取组key的值返回一个Map
12List<String> keys = new ArrayList<>();
13keys.add(key);
14Map<String, Object> graphs = loadingCache.getAll(keys);LoadingCache是使用CacheLoader来构建的缓存的值。批量查找可以使用getAll方法。默认情况下,getAll将会对缓存中没有值的key分别调用CacheLoader.load方法来构建缓存的值。我们可以重写CacheLoader.loadAll方法来提高getAll的效率。
注意:可以编写一个CacheLoader.loadAll来实现为特别请求的key加载值。例如,如果计算某个组中的任何键的值将为该组中的所有键提供值,则loadAll可能会同时加载该组的其余部分。
异步加载(Asynchronously Loading)
1AsyncLoadingCache<String, Object> asyncLoadingCache = Caffeine.newBuilder()
2 .maximumSize(10_000)
3 .expireAfterWrite(10, TimeUnit.MINUTES)
4 // Either: Build with a synchronous computation that is wrapped as asynchronous
5 .buildAsync(key -> createExpensiveGraph(key));
6 // Or: Build with a asynchronous computation that returns a future
7 // .buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));
8
9 String key = "name1";
10
11// 查询并在缺失的情况下使用异步的方式来构建缓存
12CompletableFuture<Object> graph = asyncLoadingCache.get(key);
13// 查询一组缓存并在缺失的情况下使用异步的方式来构建缓存
14List<String> keys = new ArrayList<>();
15keys.add(key);
16CompletableFuture<Map<String, Object>> graphs = asyncLoadingCache.getAll(keys);
17// 异步转同步
18loadingCache = asyncLoadingCache.synchronous();AsyncLoadingCache是继承自LoadingCache类的,异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
如果要以同步方式调用时,应提供CacheLoader。要以异步表示时,应该提供一个AsyncCacheLoader,并返回一个CompletableFuture。
synchronous()这个方法返回了一个LoadingCacheView视图,LoadingCacheView也继承自LoadingCache。调用该方法后就相当于你将一个异步加载的缓存AsyncLoadingCache转换成了一个同步加载的缓存LoadingCache。
默认使用ForkJoinPool.commonPool()来执行异步线程,但是我们可以通过Caffeine.executor(Executor) 方法来替换线程池。
![]()
驱逐策略(eviction)
Caffeine提供三类驱逐策略:基于大小(size-based),基于时间(time-based)和基于引用(reference-based)。
基于大小(size-based)
基于大小驱逐,有两种方式:一种是基于缓存大小,一种是基于权重。
1// Evict based on the number of entries in the cache
2// 根据缓存的计数进行驱逐
3LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
4 .maximumSize(10_000)
5 .build(key -> createExpensiveGraph(key));
6
7// Evict based on the number of vertices in the cache
8// 根据缓存的权重来进行驱逐(权重只是用于确定缓存大小,不会用于决定该缓存是否被驱逐)
9LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
10 .maximumWeight(10_000)
11 .weigher((Key key, Graph graph) -> graph.vertices().size())
12 .build(key -> createExpensiveGraph(key));我们可以使用Caffeine.maximumSize(long)方法来指定缓存的最大容量。当缓存超出这个容量的时候,会使用Window TinyLfu策略来删除缓存。我们也可以使用权重的策略来进行驱逐,可以使用Caffeine.weigher(Weigher) 函数来指定权重,使用Caffeine.maximumWeight(long) 函数来指定缓存最大权重值。
注意:maximumWeight与maximumSize不可以同时使用。
基于时间(Time-based)
1// Evict based on a fixed expiration policy
2// 基于固定的到期策略进行退出
3LoadingCache graphs = Caffeine.newBuilder()
4 .expireAfterAccess(5, TimeUnit.MINUTES)
5 .build(key -> createExpensiveGraph(key));
6LoadingCache graphs = Caffeine.newBuilder()
7 .expireAfterWrite(10, TimeUnit.MINUTES)
8 .build(key -> createExpensiveGraph(key));
9
10// Evict based on a varying expiration policy
11// 基于不同的到期策略进行退出
12LoadingCache graphs = Caffeine.newBuilder()
13 .expireAfter(new Expiry() {
14 @Override
15 public long expireAfterCreate(Key key, Graph graph, long currentTime) {
16 // Use wall clock time, rather than nanotime, if from an external resource
17 long seconds = graph.creationDate().plusHours(5)
18 .minus(System.currentTimeMillis(), MILLIS)
19 .toEpochSecond();
20 return TimeUnit.SECONDS.toNanos(seconds);
21 }
22
23 @Override
24 public long expireAfterUpdate(Key key, Graph graph,
25 long currentTime, long currentDuration) {
26 return currentDuration;
27 }
28
29 @Override
30 public long expireAfterRead(Key key, Graph graph,
31 long currentTime, long currentDuration) {
32 return currentDuration;
33 }
34 })
35 .build(key -> createExpensiveGraph(key)); 基于引用(reference-based)
Java 4种引用的级别由高到低依次为:强引用 > 软引用 > 弱引用 > 虚引用。

1// Evict when neither the key nor value are strongly reachable
2// 当key和value都没有引用时驱逐缓存
3LoadingCache graphs = Caffeine.newBuilder()
4 .weakKeys()
5 .weakValues()
6 .build(key -> createExpensiveGraph(key));
7
8// Evict when the garbage collector needs to free memory
9// 当垃圾收集器需要释放内存时驱逐
10LoadingCache graphs = Caffeine.newBuilder()
11 .softValues()
12 .build(key -> createExpensiveGraph(key)); 我们可以将缓存的驱逐配置成基于垃圾回收器。为此,我们可以将key和 value配置为弱引用或只将值配置成软引用。
注意:AsyncLoadingCache不支持弱引用和软引用。
![]()
移除监听器(Removal)
驱逐(eviction):由于满足了某种驱逐策略,后台自动进行的删除操作;
无效(invalidation):表示由调用方手动删除缓存;
移除(removal):监听驱逐或无效操作的监听器。
手动删除缓存:
在任何时候,都可能明确地使缓存无效,而不用等待缓存被驱逐。
1// individual key
2cache.invalidate(key)
3// bulk keys
4cache.invalidateAll(keys)
5// all keys
6cache.invalidateAll()Removal 监听器:
可以通过Caffeine.removalListener(RemovalListener) 为缓存指定一个删除侦听器,以便在删除数据时执行某些操作。 RemovalListener可以获取到key、value和RemovalCause(删除的原因)。
删除侦听器的里面的操作是使用Executor来异步执行的。默认执行程序是ForkJoinPool.commonPool(),可以通过Caffeine.executor(Executor)覆盖。当操作必须与删除同步执行时,请改为使用CacheWrite,CacheWrite将在下面说明。
注意:由RemovalListener抛出的任何异常都会被记录(使用Logger)并不会抛出。
![]()
统计(Statistics)
Cache<Key, Graph> graphs = Caffeine.newBuilder()
2 .maximumSize(10_000)
3 .recordStats()
4 .build();使用Caffeine.recordStats(),可以打开统计信息收集。Cache.stats() 方法返回提供统计信息的CacheStats,如:
hitRate():返回命中与请求的比率;
hitCount(): 返回命中缓存的总数;
evictionCount():缓存逐出的数量;
averageLoadPenalty():加载新值所花费的平均时间。
![]()
总结
Caffeine的调整不只有算法上面的调整,内存方面的优化也有很大进步,Caffeine的API的操作功能和Guava是基本保持一致的,并且Caffeine为了兼容之前是Guava的用户,所以使用或者重写缓存到Caffeine应该没什么问题,但是也要看项目情况,不要盲目使用。
作者:LLLSQ,一只有着悲惨故事的北漂程序员,为读者提供热点技术文章和IT实时热点新闻、架构、面试信息等最新讯息。
声明:本文为作者投稿,版权归对方所有。

![]()