Hive自定义函数
0、自定义函数类型
(1)UDF:user define function,输入单行,输出单行,类似于 format_number(age,'000')
(2)UDTF:user define table-gen function,输入单行,输出多行,类似于 explode(array);
(3)UDAF:user define aggr function,输入多行,输出单行,类似于 sum(xxx)
1、自定义UDF函数
(1)继承UDF类
(2)编写evaluate方法,方法名必须是"evaluate",返回值类型不固定,即方法最后返回值的类型
(3)必须添加Description描述,包括name(函数名)、value(desc方法时出现的提示)和extended(方法的扩展信息)
(4)将方法打包并发送到"/soft/hive/lib"目录下,重启hive
(5)注册函数:永久注册或临时注册
create function myudf as 'com.oldboy.hive.udf.MyUDF' //永久
create temporary function myudf as 'com.oldboy.hive.udf.MyUDF' //临时(6)eg:使用自定义函数统计每个商家每个标签的总数
(6-0)虚列(lateral view):将一列炸开后,使其他字段能够自动补全
(6-1)数据格式如下
77287793 {"reviewPics":null,"extInfoList":[{"title":"contentTags","values":["服务热情","音响效果好"],"desc":"","defineType":0},{"title":"tagIds","values":["22","173"],"desc":"","defineType":0}],"expenseList":null,"reviewIndexes":[2],"scoreList":null}(6-2)自定义函数代码
public class ParseJSON extends UDF {
public List evaluate(String json) {
List list = new ArrayList();
//将JSON串变成JSONObject格式
JSONObject jo = JSON.parseObject(json);
//解析extInfoList
JSONArray jArray = jo.getJSONArray("extInfoList");
if(jArray != null && jArray.size() != 0){
for(Object obj : jArray){
JSONObject jo2 = (JSONObject) obj;
if(jo2.get("title").toString().equals("contentTags")){
JSONArray jArray2 = jo2.getJSONArray("values");
if(jArray2 != null && jArray2.size() != 0){
for(Object obj2 : jArray2){
list.add(obj2.toString());
}
}
}
}
}
return list;
}
}
(6-3)打包,发送,注册
(6-4)将标签字段炸开,查看id和tags
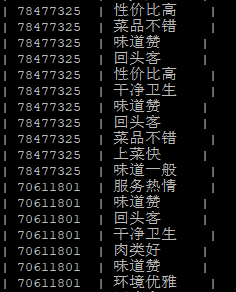
select id, tag from temptags lateral view explode(parsejson(json)) a as tag;
注解:
explode(parsejson(json))相当于一个中间表,起名为a,作为一个字段使用运行结果的部分截图:
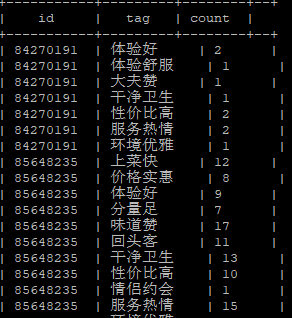
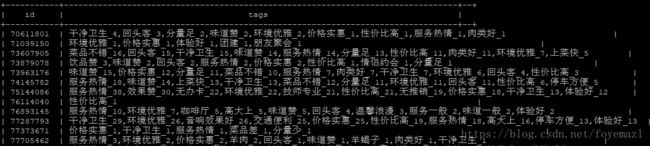
(6-5)统计每个商家每个标签的总数:hive中前边select几个字段group by后就得写几个字段
select id, tag, count(*) as count from (select id, tag from temptags lateral view explode(parsejson(json)) x as tag) a group by id, tag;问题:Caused by: java.lang.ClassNotFoundException: com.oldboy.hive.udf.ParseJson
解决:将两个jar包放在"/soft/hadoop/share/hadoop/common/lib/"目录,并同步到其他节点,重启hive和hadoop
(1)cp /soft/hive/lib/myhive-1.0-SNAPSHOT.jar /soft/hadoop/share/hadoop/common/lib/ (fastjson-1.2.47.jar)
(2)xsync.sh /soft/hadoop/share/hadoop/common/lib/myhive-1.0-SNAPSHOT.jar (fastjson-1.2.47.jar)
运行结果的部分截图:
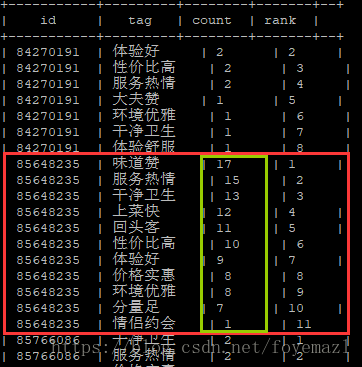
(6-6)对每个商家的所有标签排序
select id, tag, count, row_number()over(partition by id order by count desc) as rank from (select id, tag, count(*) as count from (select id, tag from temptags lateral view explode(parsejson(json)) x as tag) a group by id, tag) b;运行结果部分截图:
(6-7)对每个商家的所有标签排序,然后将标签和总数拼串,查看标签数最多的10个标签
select id, concat(tag, '_', count) from (select id, tag, count, row_number()over(partition by id order by count desc) as rank from (select id, tag, count(*) as count from (select id, tag from temptags lateral view explode(parsejson(json)) x as tag) a group by id, tag) b) c where rank <= 10;运行结果部分截图:

(6-8)将标签聚合,查看id和聚合后的标签及总数
select id, concat_ws(',', collect_set(concat(tag, '_', count))) as tags from (select id, tag, count, row_number()over(partition by id order by count desc) as rank from (select id, tag, count(*) as count from (select id, tag from temptags lateral view explode(parsejson(json)) x as tag) a group by id, tag) b) c where rank <= 10 group by id;
注解:
concat_ws(',', List<>) 拼串,第一个参数是分隔符,第二个是数组或集合
collect_set(name) 将'name'字段变为数组,去重
collect_list(name) 将'name'字段变为数组,不去重运行结果部分截图:
2、自定义UDTF函数
(1)继承Generic类,重写initialize(),process()和close()方法
public class MyUDTF extends GenericUDTF {
PrimitiveObjectInspector poi;
/**
* @param argOIs 输入字段的字段类型
* @return 返回值是表结构,例如输入map,输出的是key和value的类型
* @throws UDFArgumentException
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//参数个数不是1时抛出异常
if(argOIs.getAllStructFieldRefs().size() != 1){
throw new UDFArgumentException("参数个数必须为1");
}
//如果输入字段类型非基本数据类型,则抛异常
ObjectInspector oi = argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector();
if(oi.getCategory() != ObjectInspector.Category.PRIMITIVE){
throw new UDFArgumentException("参数必须为基本数据类型");
}
//强转为基本类型对象检查器,若不是String类型,则抛出异常
poi = (PrimitiveObjectInspector) oi;
if(poi.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentException("参数必须是string类型");
}
//构造字段名
List fieldNames = new ArrayList();
fieldNames.add("word");
//构造字段类型
List fieldOIs = new ArrayList();
//通过基本数据类型工厂获取java基本类型oi
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
//生成数据阶段
@Override
public void process(Object[] args) throws HiveException {
//得到一行数据
String line = (String) poi.getPrimitiveJavaObject(args[0]);
String[] arr = line.split(" ");
for(String word : arr){
Object[] objs = new Object[1];
objs[0] = word;
forward(objs);
}
}
//do nothing
@Override
public void close() throws HiveException {
}
} (2)打包,发送,注册
(3)测试方法:
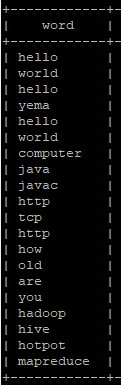
select * from wcs;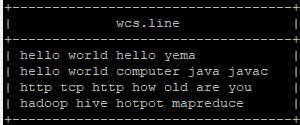
select myudtf(line) from wcs;