使用TensorFlow识别交通标志
这篇博客是翻译Waleed Abdulla写的使用TensorFlow识别交通标志,作者已经授权翻译,这是原文。
这是使用深度学习模型去识别交通标志的第一部分。本系列的目的是学习如何使用深度模型去构建一个系统,如何你也有兴趣可以和我一起学习。在网上,你能找到很多的讲解神经网络数学理论的资源,因此我将专注于应用实践方面的分享。接下来,我将介绍一下我构建这个模型时的一些经验,并且分享源代码和相关材料。如果你已经掌握了基本的Python语法和简单的机器学习技术,那么这个系列将会很适合你。但是,如果你想要正真的了解机器学习,那么自己动手构建一个真实的系统将是很好的途径。
在这部分中,我将讨论图像分类,并且我将尽可能的简化我的模型。在之后的系列文章中,我还将介绍卷积神经网络,数据集扩充和目标检测。
运行代码
源代码在这个 Jupyter 笔记本中。我使用Python版本是 3.5 ,TensorFlow版本是 0.12 。如果你想在Docker中运行这个代码,那么你可以使用我的Docker工具。使用以下命令行运行:
docker run -it -p 8888:8888 -p 6006:6006 -v ~/traffic:/traffic waleedka/modern-deep-learning从源码中,你会发现我的项目目录是在 ~/traffic 下面,我将它映射到了Docker容器的 /traffic 目录下面。如果你使用不同的项目目录,那么你可以修改它。
寻找训练数据
我的第一个挑战就是去找到一个优秀的训练数据集。交通标志识别是一个很好的研究课题,所以我们可以在网上找到很多的东西。
我开始在Google上面搜索“交通标志数据集”,并且发现了几个不错的数据集。最后,我选择了比利时交通标志数据集,因为这个数据集的训练数据足够多,但是测试数据集又很小,可以非常方便的展开研究。

你可以点击这里下载数据集。在下载页面上面有很多的数据集,但是你只需要下载 BelgiumTS for Classification (cropped images) 目录下面的两个文件:
- BelgiumTSC_Training (171.3MBytes)
- BelgiumTSC_Testing (76.5MBytes)
将文件解压之后,下面就是我的目录结构了。我建议你也将文件目录设置的和我一样,那么在运行源代码的时候就不用去修改文件目录地址了。
/traffic/datasets/BelgiumTS/Training/
/traffic/datasets/BelgiumTS/Testing/这两个文件夹下面都有62个子文件夹,编号从 00000 到 00061 。子文件夹的名字标识了里面图像的标签。
探索数据集
如果你想要这部分的名字更加正式一点,那么可以称为探索性数据分析。可能你会觉得这部分并不是很有用,但是我发现我写的这些用来检查数据的代码在整个项目中都被使用了很多次。我经常在 Jupyter 中这样做,并且将这些笔记分享给团队。从一开始就很好的了解你的数据集,这将在以后的工作中为你节省很多的时间。
这个数据集中的图像采用一种 .ppm 的格式保存。事实上,这是一种很老的图片保存格式,很多的工具都已经不支持它了。这也就意味着,我不能很方便的查看这些文件夹里面的图片。幸运的是,Scikit Image library可以识别这种形式的图片。下面的代码就是用来加载数据,并且返回两个列表:图片和标签。
def load_data(data_dir):
# Get all subdirectories of data_dir. Each represents a label.
directories = [d for d in os.listdir(data_dir)
if os.path.isdir(os.path.join(data_dir, d))]
# Loop through the label directories and collect the data in
# two lists, labels and images.
labels = []
images = []
for d in directories:
label_dir = os.path.join(data_dir, d)
file_names = [os.path.join(label_dir, f)
for f in os.listdir(label_dir)
if f.endswith(".ppm")]
for f in file_names:
images.append(skimage.data.imread(f))
labels.append(int(d))
return images, labels
images, labels = load_data(train_data_dir)这是一个小的数据集,所以我把所有的数据都加载到了RAM里面。但是对于较大的数据集,那么你必须批量的读取数据。
加载完数据之后,并且把它转化成 Numpy 格式。我写了一个展示的程序,用来显示每个标签的样本图像。代码在这里,以下是我们的数据集:

数据集看起来就是一个优秀的数据集。图片的质量非常好,并且有各种各样的角度和光线条件。更重要的是,交通标志占据了图片的大部分区域,这带来的好处是,可以让我专心集中于图片的分类,而不必担心图像中交通标志的位置(目标检测)。但我会在以后的文章中介绍目标检测技术的应用。
那么接下来的第一件事是什么呢?从上面的图片中,我注意到图片虽然是方形的,但是每一种图片的长宽比都不一样。但是,我的神经网络的输入大小是固定的,所以我需要做一些处理工作。但是首先,我先拿一个标签图片出来,多看几张该标签下的图片,比如标签32,如下:

从上述图片中,我们可以发现虽然限速大小不同,但是都被归纳到同一类了。这非常好,后续的程序中,我们就可以忽略数字这个概念了。这就是为什么事先理解你的数据集是如此重要,可以在后续工作中为你节省很多的痛苦和混乱。
对于剩下的标签,你可以自己探索。标签26和27是非常有意思的。他们都有红色的圈圈和圈圈内都有数字,所以模型必须很好的识别他们。
处理不同尺寸的图片
大多数图片分类的神经网络需要固定输入的大小,我们的第一个模型也会做到这一点。所以,我们需要将所有图片调整为相同的大小。
但是由于图片具有不同的长宽比,因此其中一些图片将会被水平拉伸,其中一些将会被垂直拉伸。那么,这种处理方式会造成问题吗?我认为在这个数据集中是不会有问题的,因为图片的拉伸比例不是很大。我自己的数据标准是,如果一个人可以识别一张图片,当这张图片被小范围拉伸时,那么模型也应该能够识别。

那么原始图片的大小到底是什么呢?让我们先来打印一些看看:
for image in images[:5]:
print("shape: {0}, min: {1}, max: {2}".format(
image.shape, image.min(), image.max()))
Output:
shape: (141, 142, 3), min: 0, max: 255
shape: (120, 123, 3), min: 0, max: 255
shape: (105, 107, 3), min: 0, max: 255
shape: (94, 105, 3), min: 7, max: 255
shape: (128, 139, 3), min: 0, max: 255图片的尺寸大约在 128 * 128 左右,那么我们可以使用这个尺寸来保存图片,这样可以保存尽可能多的信息。但是,在早期的开发中,我更喜欢使用更小的尺寸,因为这样训练模型将很快,这使我能够更快的迭代。我试验了 16 * 16 和 20 * 20 的尺寸,但是他们都太小了。最终,我选择了 32 * 32 的尺寸,这在肉眼下很容易识别图片(见下图),并且我们是要保证缩小的比例是 128 * 128 的倍数。
我还有一个习惯,就是喜欢打印出数据中的最小值和最大值。这是一种验证数据范围和提前捕获程序错误的简单方法。在这个数据集中,它告诉我图片的颜色是在标准范围 0~255 。

最小可行模型
终于我们到了最有趣的部分,继续延续我们简单的风格。我们从一个最简单的可行模型开始讲解:一层网络,每个神经元表示一个标签。
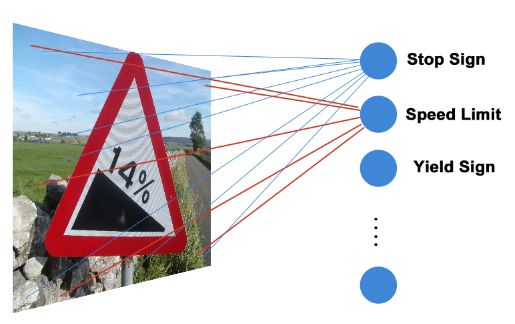
该网络具有62个神经元,每个神经元将图片所有像素的RGB值作为输入。实际上,每个神经元接受 32 * 32 * 3 = 3072 个输入。这个一个完全连接层,因为每个神经元都链接到输入层。你可能已经熟悉了下面的等式:
y = xW + b我之所以从这个简单的模型开始,是因为这是一个很容易解释的模型,易于调试,并且可以快速训练。一旦这个工作结束,那么我们可以在这个工程的基础上进行更加复杂的事情。
构建 TensorFlow 图
TensorFlow 在执行图中封装了神经网络的架构。构建的图包含了操作(简称为 Ops),比如 Add,Multiply,Reshape,..... 等等。这些操作在张量(多维数组)中对数据执行操作。
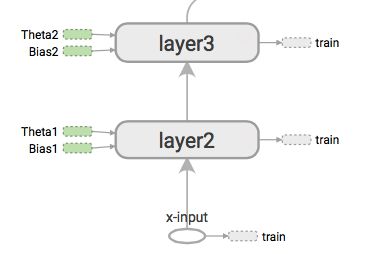
我将通过代码一步一步来构建这个图,但我还是先给出完整的代码,如果你喜欢它可以先了解一下:
# Create a graph to hold the model.
graph = tf.Graph()
# Create model in the graph.
with graph.as_default():
# Placeholders for inputs and labels.
images_ph = tf.placeholder(tf.float32, [None, 32, 32, 3])
labels_ph = tf.placeholder(tf.int32, [None])
# Flatten input from: [None, height, width, channels]
# To: [None, height * width * channels] == [None, 3072]
images_flat = tf.contrib.layers.flatten(images_ph)
# Fully connected layer.
# Generates logits of size [None, 62]
logits = tf.contrib.layers.fully_connected(images_flat, 62, tf.nn.relu)
# Convert logits to label indexes (int).
# Shape [None], which is a 1D vector of length == batch_size.
predicted_labels = tf.argmax(logits, 1)
# Define the loss function.
# Cross-entropy is a good choice for classification.
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, labels_ph))
# Create training op.
train = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# And, finally, an initialization op to execute before training.
# TODO: rename to tf.global_variables_initializer() on TF 0.12.
init = tf.initialize_all_variables()首先,我先创建一个Graph对象。TensorFlow有一个默认的全局图,但是我不建议使用它。设置全局变量通常是一个很坏的习惯,因为它太容易引入错误了。我更倾向于自己明确地创建一个图。
graph = tf.Graph()然后,我设置了占位符(Placeholder)用来放置图片和标签。占位符是TensorFlow从主程序中接收输入的方式。注意,我是在 graph.as_default() 中创建的占位符(和所有其它的操作)。这样做的好处是他们成为了我创建的图的一部分,而不是在全局图中。
with graph.as_default():
images_ph = tf.placeholder(tf.float32, [None, 32, 32, 3])
labels_ph = tf.placeholder(tf.int32, [None])参数 images_ph 的维度是 [None, 32, 32, 3],这四个参数分别表示 [批量大小,高度,宽度,通道] (通常缩写为 NHWC)。批处理大小用 None 表示,意味着批处理大小是灵活的,也就是说,我们可以向模型中导入任意批量大小的数据,而不用去修改代码。注意你输入数据的顺序,因为在一些模型和框架下面可以使用不同的排序,比如 NCHW。
接下来,我定义一个全连接层,而不是实现原始方程 y = xW + b。在这一行中,我使用一个方便的函数,并且使用激活函数。模型的输入时一个一维向量,所以我先要压平图片。
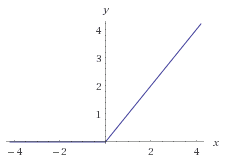
在这里,我使用 ReLU函数作为激活函数,如下:
f(x) = max(0, x)这个激活函数可以很方便的将负数转化成零。这种处理方式在分类任务上面可以取得很好的效果,并且训练速度比 sigmoid 或者 tanh 都快很多。如果你还想了解更多,可以查看这里和这里。
# Flatten input from: [None, height, width, channels]
# To: [None, height * width * channels] == [None, 3072]
images_flat = tf.contrib.layers.flatten(images_ph)
# Fully connected layer.
# Generates logits of size [None, 62]
logits = tf.contrib.layers.fully_connected(images_flat, 62,
tf.nn.relu)全连接层的输出是一个长度是62的对数矢量(从技术上分析,它的输出维度应该是 [None, 62],因为我们是一批一批处理的)。
输出的数据可能看起来是这样的:[0.3, 0, 0, 1.2, 2.1, 0.01, 0.4, ... ..., 0, 0]。值越高,图片越可能表示该标签。输出的不是一个概率,他们可以是任意的值,并且相加的结果不等于1。输出神经元的实际值大小并不重要,因为这只是一个相对值,相对62个神经元而言。如果需要,我们可以很容易的使用 softmax 函数或者其他的函数转换成概率(这里不需要)。
在这个项目中,我们只需要知道最大值所对应的索引就行了,因为这个索引代表着图片的分类标签,这个求解最大操作可以如下表示:
# Convert logits to label indexes.
# Shape [None], which is a 1D vector of length == batch_size.
predicted_labels = tf.argmax(logits, 1)argmax 函数的输出结果将是一个整数,范围是 [0, 61]。
损失函数和梯度下降
选择正确的损失函数本身就是一个研究领域,在这里我不会深入研究,我们使用交叉熵来作为损失函数,因为这是一个在分类任务中最常见的函数。如果你不熟悉它,这里和这里都有很好的解释。
交叉熵是两个概率向量之间的差的度量。因此,我们需要将标签和神经网络的输出转换成概率向量。TensorFlow中有一个 sparse_softmax_cross_entropy_with_logits 函数可以实现这个操作。这个函数将标签和神经网络的输出作为输入参数,并且做三件事:第一,将标签的维度转换为 [None, 62](这是一个0-1向量);第二,利用softmax函数将标签数据和神经网络输出结果转换成概率值;第三,计算两者之间的交叉熵。这个函数将会返回一个维度是 [None] 的向量(向量长度是批处理大小),然后我们通过 reduce_mean 函数来获得一个值,表示最终的损失值。
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, labels_ph))下一个需要处理的就是选择一个合适的优化算法。我一般都是使用 ADAM 优化算法,因为它的收敛速度比一般的梯度下降法更快。如果你想知道不同优化器之间的比较结果,那么可以查看这篇博客。
train = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)图中的最后一个节点是初始化所有的操作,它简单的将所有变量的值设置为零(或随机值)。
init = tf.initialize_all_variables()请注意,上面的代码还没有执行任何操作。它只是构建图,并且描述了输入。在上面我们定义的变量,比如,init,loss和predicted_labels,它们都不包含具体的数值。它们是我们接下来要执行的操作的引用。
训练循环
这是我们迭代训练模型的地方。在我们开始训练之前,我们需要先创建一个会话(Session)对象。
还记得之前我们提到过的 Graph 对象,以及它如何保存模型中所有的操作(Ops)。另一方面,会话(Session)也保存所有变量的值。如果图保存的是方程 y = xW + b ,那么会话保存的是这些变量的实际值。
session = tf.Session(graph=graph)通常,在启动会话之后,第一件事就是进行初始化操作,如下所示:
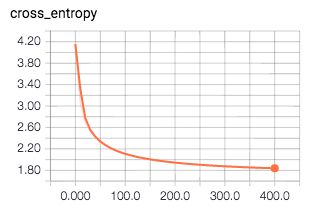
session.run(init)然后,我们开始循环训练模型,直到得到我们需要的收敛结果。在训练过程中,我们记录并且打印出损失函数的值是非常有用的,它可以帮助我们监控训练的进度。
for i in range(201):
_, loss_value = session.run(
[train, loss],
feed_dict={images_ph: images_a, labels_ph: labels_a})
if i % 10 == 0:
print("Loss: ", loss_value)正如你所看到的,我将循环次数设置成了201,并且当循环次数满足10的倍数时,打印出损失值。最终的输出结果看起来像这样:
Loss: 4.2588
Loss: 2.88972
Loss: 2.42234
Loss: 2.20074
Loss: 2.06985
Loss: 1.98126
Loss: 1.91674
Loss: 1.86652
Loss: 1.82595
...模型使用
现在我们在Session对象中有一个保存在内存中训练好的模型了。如果想使用它,我们可以调用 session.run() 函数来使用它。predicted_labels 操作返回 argmax 函数的结果,而这就是我们需要得到的结果。下面,我随机取了10个图片进行分类,并且同时打印了标签结果和预测结果。
# Pick 10 random images
sample_indexes = random.sample(range(len(images32)), 10)
sample_images = [images32[i] for i in sample_indexes]
sample_labels = [labels[i] for i in sample_indexes]
# Run the "predicted_labels" op.
predicted = session.run(predicted_labels,
{images_ph: sample_images})
print(sample_labels)
print(predicted)
Output:
[15, 22, 61, 44, 32, 22, 57, 38, 56, 38]
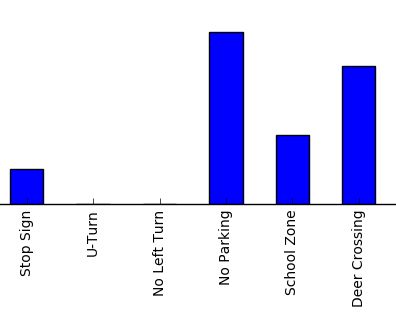
[14 22 61 44 32 22 56 38 56 38]在我们的源代码中,我还编写了一个可视化函数用来展示对比结果,展示效果如下:

从图中我们可以发现,我们的模型是可以正确运行的,但是从图中不能量化它的准确性。你可能已经注意到了我们分类的还是训练的图片,所以我们还不知道,模型在未知数据集上面的效果如何。接下来,我们在测试集上面进行更好地评测。
评估
为了正确的评估模型,我们需要在测试集上面进行测试。BelgiumTS 数据集恰好提供了两个数据集合,一个用于训练,另一个用于测试。所以,我们可以很容易的使用测试集来评估我们的训练模型。
在源代码中,我加载了测试集,并且将图片的尺寸转化成 32 * 32 ,然后计算预测正确性。这是评估部分的相关代码:
# Run predictions against the full test set.
predicted = session.run(predicted_labels,
feed_dict={images_ph: test_images32})
# Calculate how many matches we got.
match_count = sum([int(y == y_)
for y, y_ in zip(test_labels, predicted)])
accuracy = match_count / len(test_labels)
print("Accuracy: {:.3f}".format(accuracy))在每次的运行中,我们获得的正确率在 0.40~0.70 之间,造成这个原因是模型是否落在局部最小值还是全局最小值。这也是运行这样一个简单的模型无法避免的问题。在以后的文章中,我将讨论如何提高结果的一致性。
关闭会话
恭喜!至此,你已经学会了如何去书写一个简单的神经网络。考虑到这个神经网络是如此的简单,在我的笔记本电脑上训练这个模型只需要一分钟,所以我没有保存训练的模型。在下一部分中,我将添加模型保存和加载的部分,并扩展到使用多层网络,卷积神经网络和数据集扩充等部分。敬请期待!
# Close the session. This will destroy the trained model.
session.close()作者:chen_h
链接:http://www.jianshu.com/p/3c7f329b29ee
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。