用Python构建NLP Pipeline,从思路到具体代码,这篇文章一次性都讲到了
面向用户:对NLP感兴趣,想学习处理问题思路并通过实例代码练手
阅读时长:全文大约 2000 字,读完可能需要下面这首歌的时间
授人以鱼不如授人以渔,今天的文章由作者Adam Geitgey授权在人工智能头条翻译发布。不仅给出了具体代码,还一步步详细解析了实现原理和思路。正所谓有了思路,无论是做英语、汉语的语言处理,才算的上有了指导意义。
Adam Geitgey毕业于佐治亚理工学院,曾在团购网站Groupon担任软件工程师总监。目前是软件工程和机器学习顾问,课程作者,Linkedin Learning的合作讲师。
计算机是如何理解人类语言的?

让机器理解人类语言,是一件非常困难的事情。计算机的专长在处理结构化数据,但人类语言是非常复杂的,碎片化,松散,甚至不合逻辑、心口不一。
既然直男不能明白为什么女朋友会生气,那计算机当然无法理解A叫B为孙子的时候,是在喊亲戚、骂街,或只是朋友间的玩笑。
面对人类,计算机相当于是金刚陨石直男。
正是由于人工智能技术的发展,不断让我们相信,计算机总有一天可以听懂人类表达,甚至像真人一样和人沟通。那么,就让我们开始这算美好的教程吧。
创建一个NLP Pipeline
London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.
伦敦,是英国的首都,人口居全国之首。位于大不列颠岛东南方泰晤士河流域,在此后两个世纪内为这一地区最重要的定居点之一。它于公元50年由罗马人建立,取名为伦蒂尼恩。
-- 维基百科
Step 1:断句(句子切分)
上面介绍伦敦的一段话,可以切分成3个句子:
伦敦是大不列颠的首都,人口居全国之首(London is the capital and most populous city of England and the United Kingdom)
位于泰晤士河流域(Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia)
它于公元50年由罗马人建立,取名为伦蒂尼恩(It was founded by the Romans, who named it Londinium)
Step 2:分词
由于中文的分词逻辑和英文有所不同,所以这里就直接使用原文了。接下来我们一句一句的处理。首先第一句:
“London”, “is”, “ the”, “capital”, “and”, “most”, “populous”, “city”, “of”, “England”, “and”, “the”, “United”, “Kingdom”, “.”
英文的分词相对简单一些,两个空格之间可以看做一个词(word),标点符号也有含义,所以把标点符号也看做一个词。
Step 3:区分单词的角色
我们需要区分出一个词在句子中的角色,是名词?动词?还是介词。我们使用一个预先经过几百万英文句子训练、被调教好的词性标注(POS: Part Of Speech)分类模型:

这里有一点一定要记住:模型只是基于统计结果给词打上标签,它并不了解一个词的真实含义,这一点和人类对词语的理解方式是完全不同的。
处理结果:

可以看到。我们等到的信息中,名词有两个,分别是伦敦和首都。伦敦是个独特的名称,首都是个通用的称谓,因此我们就可以判断,这句话很可能是在围绕伦敦这个词说事儿。
Step 4: 文本词形还原
很多基于字母拼写的语言,像英语、法语、德语等,都会有一些词形的变化,比如单复数变化、时态变化等。比如:
I had a pony(我有过一匹矮马)
I have two ponies (我有两匹矮马)
其实两个句子的关键点都是矮马pony。Ponies和pony、had和have只是同一个词的不同词形,计算机因为并不知道其中的含义,所以在它眼里都是完全不一样的东西,
让计算机明白这个道理的过程,就叫做词形还原。对之前有关伦敦介绍的第一句话进行词形还原后,得到下图

Step 5:识别停用词
停用词:在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的。
-- 维基百科
还是来看第一句话:

其中灰色的字,仅仅是起到衔接和辅助表述的作用。他们的存在,对计算机来说更多是噪音。所以我们需要把这些词识别出来。
正如维基所说,现在虽然停用词列表很多,但一定要根据实际情况进行配置。比如英语的the,通常情况是停用词,但很多乐队名字里有the这个词,The Doors, The Who,甚至有个乐队直接就叫The The!这个时候就不能看做是停用词了。
Step 6:解析依赖关系
解析句子中每个词之间的依赖关系,最终建立起一个关系依赖树。这个数的root是关键动词,从这个关键动词开始,把整个句子中的词都联系起来。

从这个关系树来看,主语是London,它和capital被be联系起来。然后计算机就知道,London is a capital。如此类推,我们的计算机就被训练的掌握越来越多的信息。
但因为人类语言的歧义性,这个模型依然无法适应所有场景。但是随着我们给他更多的训练,我们的NLP模型会不断提高准确性。Demo地址
https://explosion.ai/demos/displacy?utm_source=AiHl0
我们还可以选择把相关的词进行合并分组,例如把名词以及修饰它的形容词合并成一个词组短语。不过这一步工作不是必须要有的,视具体情况而定。

Step 7:命名实体识别
经过以上的工作,接下来我们就可以直接使用现有的命名实体识别(NER: Named Entity Recognition)系统,来给名词打标签。比如我们可以把第一句话当中的地理名称识别出来:

大家也可以通过下面的链接,在线体验一下。随便复制粘贴一段英文,他会自动识别出里面包含哪些类别的名词:
https://explosion.ai/demos/displacy-ent?utm_source=AiHl0

Step 8:共指消解
人类的语言很复杂,但在使用过程中却是倾向于简化和省略的。比如他,它,这个,那个,前者,后者…这种指代的词,再比如缩写简称,北京大学通常称为北大,中华人民共和国通常就叫中国。这种现象,被称为共指现象。
在特定语境下人类可以毫不费力的区别出它这个字,到底指的是牛,还是手机。但是计算机需要通过共指消解才能知道下面这句话
它于公元50年由罗马人建立,取名为伦蒂尼恩
中的它,指的是伦敦,而不是罗马,不是罗纹,更不是萝卜。

共指消解相对而言是我们此次创建NLP Pipeline所有环节中,最难的部分。
Coding
好了。思路终于讲完了。接下来就是Coding的部分。首先我们理一下思路

提示:上述步骤只是标准流程,实际工作中需要根据项目具体的需求和条件,合理安排顺序。
安装spaCy
我们默认你已经安装了Python 3。如果没有的话,你知道该怎么做。接下来是安装spaCy:

安装好以后,使用下面代码

结果如下

GPE:地理位置、地名
FAC:设施、建筑
DATE:日期
NORP:国家、地区
PERSON:人名
我们看到,因为Londinium这个地名不够常见,所以spaCy就做了一个大胆的猜测,猜这可能是个人名。
我们接下来进一步,构建一个数据清理器。假设你拿到了一份全国酒店入住人员登记表,你想把里面的人名找出来替换掉,而不改动酒店名、地名等名词,可以这样做:

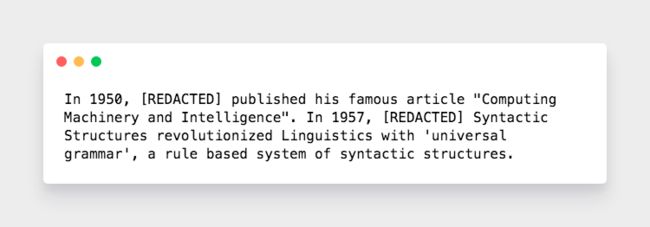
把所有标注为[PERSON]的词都替换成REDACTED。最终结果
提取详细信息
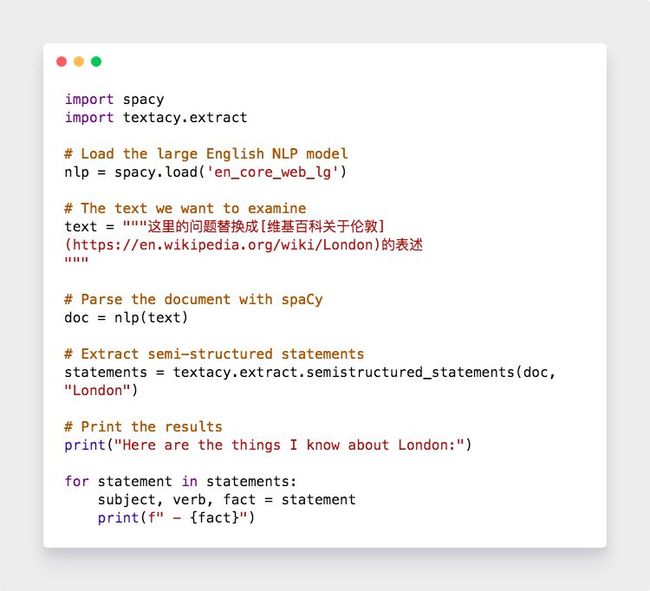
利用spaCy识别并定位的名词,然后利用textacy就可以把一整篇文章的信息都提取出来。我们在wiki上复制整篇介绍伦敦的内容到以下代码
你会得到如下结果

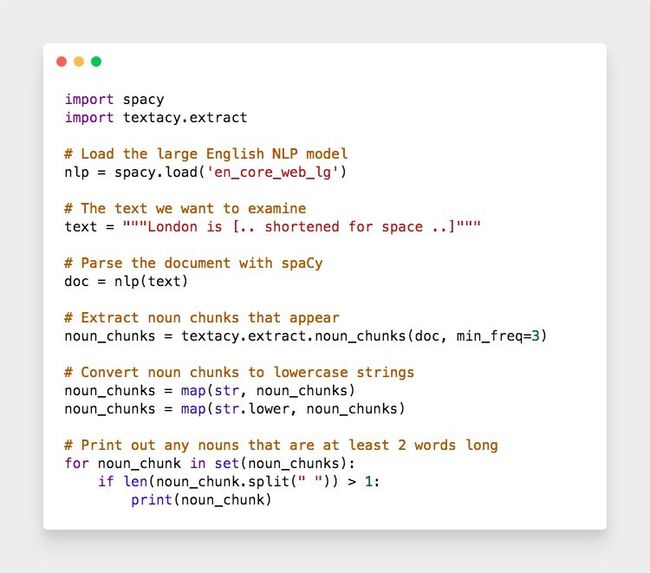
我们获得了这么多有用的信息,就可以应用在很多场景下。比如,搜索结果的相关推荐:

我们可以通过下面这种方法实现上图的效果
因为公众号的限制,我们把代码做成了图片。如果你想看纯文本的代码,复制下面链接到浏览器打开
http://t.cn/RgCITGj?utm_source=AiHl0
