使用GIZA++进行词对齐
准备双语语料
zh.txt:源语言
海洋 是 一个 非常 复杂 的 事物 。
人类 的 健康 也 是 一 件 非常 复杂 的 事情 。
将 两者 统一 起来 看 起来 是 一 件 艰巨 的 任务 。 但 我 想 要 试图 去 说明 的 是 即使 是 如此 复杂 的 情况 , 也 存在 一些 我 认为 简单 的 话题 , 一些 如果 我们 能 理解 , 就 很 容易 向前 发展 的 话题 。
这些 简单 的 话题 确实 不 是 有关 那 复杂 的 科学 有 了 怎样 的 发展 , 而是 一些 我们 都 恰好 知道 的 事情 。
接下来 我 就 来说 一个 。 如果 老 妈 不 高兴 了 , 大家 都 别 想 开心 。en.txt:目标语言
It can be a very complicated thing , the ocean .
And it can be a very complicated thing , what human health is .
And bringing those two together might seem a very daunting task , but what I 'm going to try to say is that even in that complexity , there 's some simple themes that I think , if we understand , we can really move forward .
And those simple themes aren 't really themes about the complex science of what 's going on , but things that we all pretty well know .
And I 'm going to start with this one : If momma ain 't happy , ain 't nobody happy .注意UTF-8编码。
下载编译GIZA++
$ git clone https://github.com/moses-smt/giza-pp.git
$ cd giza-pp
$ make编译完会在GIZA++-v2/和mkcls-v2/目录下生成以下可执行文件:
plain2snt.out、snt2cooc.out、GIZA++、
mkcls
将这四个程序移动到工作目录workspace下:
运行命令进行词对齐
文本单词编号
./plain2snt.out zh.txt en.txt
得到en.vcb、zh.vcb、en_zh.snt、zh_en.snt四个文件
en.vcb / zh.vcb:字典文件,id : token : count
2 海洋 1
3 是 6
4 一个 2
5 非常 2
6 复杂 4
7 的 12
8 事物 1
9 。 7
10 人类 1
...en_zh.snt / zh_en.snt:编号表示句对,第一行表示句对出现次数
1
2 3 4 5 6 7 8 9
2 3 4 5 6 7 8 9 10 11 12 13
1
10 7 11 12 3 13 14 5 6 7 15 9
14 15 4 5 6 7 8 9 10 16 17 18 19 13
...生成共现文件
./snt2cooc.out zh.vcb en.vcb zh_en.snt > zh_en.cooc
./snt2cooc.out en.vcb zh.vcb en_zh.snt > en_zh.cooc
zh_en.cooc / en_zh.cooc
0 33
0 34
0 35
0 36
0 37
0 38
0 39
0 40
...生成词类
./mkcls -pzh.txt -Vzh.vcb.classes opt
./mkcls -pen.txt -Ven.vcb.classes opt
***** 1 runs. (algorithm:TA)*****
;KategProblem:cats: 100 words: 68
start-costs: MEAN: 262.907 (262.907-262.907) SIGMA:0
end-costs: MEAN: 190.591 (190.591-190.591) SIGMA:0
start-pp: MEAN: 3.52623 (3.52623-3.52623) SIGMA:0
end-pp: MEAN: 1.95873 (1.95873-1.95873) SIGMA:0
iterations: MEAN: 50117 (50117-50117) SIGMA:0
time: MEAN: 1.468 (1.468-1.468) SIGMA:0参数:
-c 词类数目
-n 优化次数,默认是1,越大越好
-p 输入文件
-V 输出文件
opt 优化输出
en.vcb.classes / zh.vcb.classes:单词所属类别编号
, 26
. 28
: 64
And 29
I 13
If 52
It 49
a 34
about 22
...en.vcb.classes.cats / zh.vcb.classes.cats:类别所拥有的一组单词
0:$,
1:
2:science,
3:seem,
4:things,
5:some,
6:start,
7:task,
...GIZA++
先在当前目录新建两个输出文件夹z2e、e2z,否则下面的程序会出错,没有输出。
$ ./GIZA++ -S zh.vcb -T en.vcb -C zh_en.snt -CoocurrenceFile zh_en.cooc -o z2e -OutputPath z2e
$ ./GIZA++ -S en.vcb -T zh.vcb -C en_zh.snt -CoocurrenceFile en_zh.cooc -o e2z -OutputPath e2z
参数:
-o 文件前缀
-OutputPath 输出所有文件到文件夹
输出文件详解(以z2e为例):
z2e.perp 困惑度
#trnsz tstsz iter model trn-pp test-pp trn-vit-pp tst-vit-pp
5 0 0 Model1 80.5872 N/A 2250.77 N/A
5 0 1 Model1 36.0705 N/A 648.066 N/A
5 0 2 Model1 34.0664 N/A 523.575 N/A
5 0 3 Model1 32.628 N/A 423.928 N/A
5 0 4 Model1 31.5709 N/A 359.343 N/A
5 0 5 HMM 30.7896 N/A 314.58 N/A
5 0 6 HMM 31.1412 N/A 172.128 N/A
5 0 7 HMM 26.1343 N/A 111.444 N/A
5 0 8 HMM 22.177 N/A 79.3055 N/A
5 0 9 HMM 19.0506 N/A 58.4415 N/A
5 0 10 THTo3 32.6538 N/A 37.8575 N/A
5 0 11 Model3 11.1194 N/A 11.944 N/A
5 0 12 Model3 8.93033 N/A 9.50349 N/A
5 0 13 Model3 7.68766 N/A 8.19622 N/A
5 0 14 Model3 6.64154 N/A 7.04977 N/A
5 0 15 T3To4 6.17993 N/A 6.55567 N/A
5 0 16 Model4 6.16858 N/A 6.4715 N/A
5 0 17 Model4 6.0819 N/A 6.39317 N/A
5 0 18 Model4 6.04302 N/A 6.34387 N/A
5 0 19 Model4 5.95066 N/A 6.2234 N/Az2e.a3.final:i j l m p(i/j, l, m):i代表源语言Token位置;j代表目标语言Token位置;l代表源语言句子长度;m代表目标语言句子长度;p(i/j, l, m)代表the probability that a source word in position i is moved to position j in a pair of sentences of length l and m。
1 1 8 100 1
5 2 8 100 1
4 3 8 100 1
2 4 8 100 1
5 5 8 100 1
4 6 8 100 1
4 7 8 100 1
0 8 8 100 1
...z2e.d3.final:类似于z2e.a3.final文件,只是交换了i 和 j 的位置。
2 0 100 8 0.0491948
6 0 100 8 0.950805
3 1 100 8 1
5 2 100 8 1
4 3 100 8 1
2 4 100 8 0.175424
5 4 100 8 0.824576
2 5 100 8 1
4 6 100 8 1
4 7 100 8 1
...z2e.n3.final:source_id p0 p1 p2 … pn;源语言Token的Fertility分别为0,1,…,n时的概率表,比如p0是Fertility为0时的概率。
2 1.22234e-05 0.781188 0.218799 0 0 0 0 0 0 0
3 0.723068 0.223864 0 0.053068 0 0 0 0 0 0
4 0.349668 0.439519 0.0423205 0.168493 0 0 0 0 0 0
5 0.457435 0.447043 0.0955223 0 0 0 0 0 0 0
6 0.214326 0.737912 0 0.0477612 0 0 0 0 0 0
7 1 0 0 0 0 0 0 0 0 0
8 1.48673e-05 0.784501 0.215484 0 0 0 0 0 0 0
...z2e.t3.final:s_id t_id p(t_id/s_id); IBM Model 3训练后的翻译表;p(t_id/s_id)表示源语言Token翻译为目标语言Token的概率
0 3 0.196945
0 7 0.74039
0 33 0.0626657
2 4 1
3 6 1
4 5 1
5 3 0.822024
5 6 0.177976
6 3 0.593075
...z2e.A3.final 单向对齐文件,数字代表Token所在句子位置(1为起点)
# Sentence pair (1) source length 8 target length 11 alignment score : 8.99868e-08
It can be a very complicated thing , the ocean .
NULL ({ 8 }) 海洋 ({ 1 }) 是 ({ 4 }) 一个 ({ 9 }) 非常 ({ 3 6 7 }) 复杂 ({ 2 5 }) 的 ({ }) 事物 ({ 10 }) 。 ({ 11 })
# Sentence pair (2) source length 12 target length 14 alignment score : 9.55938e-12
And it can be a very complicated thing , what human health is .
NULL ({ 9 }) 人类 ({ 2 11 }) 的 ({ }) 健康 ({ 12 }) 也 ({ }) 是 ({ 5 }) 一 ({ }) 件 ({ 13 }) 非常 ({ 4 7 8 }) 复杂 ({ 3 6 }) 的 ({ }) 事情 ({ 1 10 }) 。 ({ 14 })
...z2e.d4.final:IBM Model 4 翻译表
# Translation tables for Model 4 .
# Table for head of cept.
F: 20 E: 26
SUM: 0.125337
9 0.125337
F: 20 E: 15
SUM: 0.0387214
-2 0.0387214
F: 20 E: 24
SUM: 0.0387214
21 0.0387214
...z2e.D4.final:IBM Model 4的Distortion表
26 20 9 1
15 20 -2 1
24 20 21 1
2 20 -2 1
40 20 -4 1
22 20 -3 0.0841064
22 20 9 0.915894
32 20 28 1
21 20 24 1
29 2 -3 0.472234
29 2 1 0.527766
5 2 1 0.475592
...z2e.gizacfg:GIZA++配置文件,超参数
adbackoff 0
c zh_en.snt
compactadtable 1
compactalignmentformat 0
coocurrencefile zh_en.cooc
corpusfile zh_en.snt
countcutoff 1e-06
countcutoffal 1e-05
countincreasecutoff 1e-06
countincreasecutoffal 1e-05
d
deficientdistortionforemptyword 0
depm4 76
depm5 68
dictionary
dopeggingyn 0
emalignmentdependencies 2
emalsmooth 0.2
emprobforempty 0.4
emsmoothhmm 2
hmmdumpfrequency 0
hmmiterations 5
l z2e/118-03-20.215009.gld.log
log 0
logfile z2e/118-03-20.215009.gld.log
m1 5
m2 0
m3 5
m4 5
m5 0
m5p0 -1
m6 0
manlexfactor1 0
manlexfactor2 0
manlexmaxmultiplicity 20
maxfertility 10
maxsentencelength 101
mh 5
mincountincrease 1e-07
ml 101
model1dumpfrequency 0
model1iterations 5
model23smoothfactor 0
model2dumpfrequency 0
model2iterations 0
model345dumpfrequency 0
model3dumpfrequency 0
model3iterations 5
model4iterations 5
model4smoothfactor 0.2
model5iterations 0
model5smoothfactor 0.1
model6iterations 0
nbestalignments 0
nodumps 0
nofiledumpsyn 0
noiterationsmodel1 5
noiterationsmodel2 0
noiterationsmodel3 5
noiterationsmodel4 5
noiterationsmodel5 0
noiterationsmodel6 0
nsmooth 64
nsmoothgeneral 0
numberofiterationsforhmmalignmentmodel 5
o z2e/z2e
onlyaldumps 0
outputfileprefix z2e/z2e
outputpath z2e/
p 0
p0 -1
peggedcutoff 0.03
pegging 0
probcutoff 1e-07
probsmooth 1e-07
readtableprefix
s zh.vcb
sourcevocabularyfile zh.vcb
t en.vcb
t1 0
t2 0
t2to3 0
t3 0
t345 0
targetvocabularyfile en.vcb
tc
testcorpusfile
th 0
transferdumpfrequency 0
v 0
verbose 0
verbosesentence -10z2e.Decoder.config:用于ISI Rewrite Decoder解码器
# Template for Configuration File for the Rewrite Decoder
# Syntax:
# =
# '#' is the comment character
#================================================================
#================================================================
# LANGUAGE MODEL FILE
# The full path and file name of the language model file:
LanguageModelFile =
#================================================================
#================================================================
# TRANSLATION MODEL FILES
# The directory where the translation model tables as created
# by Giza are located:
#
# Notes: - All translation model "source" files are assumed to be in
# TM_RawDataDir, the binaries will be put in TM_BinDataDir
#
# - Attention: RELATIVE PATH NAMES DO NOT WORK!!!
#
# - Absolute paths (file name starts with /) will override
# the default directory.
TM_RawDataDir = z2e/
TM_BinDataDir = z2e/
# file names of the TM tables
# Notes:
# 1. TTable and InversTTable are expected to use word IDs not
# strings (Giza produces both, whereby the *.actual.* files
# use strings and are THE WRONG CHOICE.
# 2. FZeroWords, on the other hand, is a simple list of strings
# with one word per line. This file is typically edited
# manually. Hoeever, this one listed here is generated by GIZA
TTable = z2e.t3.final
InverseTTable = z2e.ti.final
NTable = z2e.n3.final
D3Table = z2e.d3.final
D4Table = z2e.D4.final
PZero = z2e.p0_3.final
Source.vcb = zh.vcb
Target.vcb = en.vcb
Source.classes = zh.vcb.classes
Target.classes = en.vcb.classes
FZeroWords = z2e.fe0_3.final
下面两个Python文件地址:GitHub
词对齐对称化
上面的得到的*.A3.final文件是单向对齐的,我们这里需要对称化,对称化方法有很多,我们这里使用最流行的“grow-diag-final-and”方法
python align_sym.py e2z.A3.final z2e.A3.final > aligned.grow-diag-final-and
1-1 2-4 3-1 3-9 4-3 4-6 4-7 5-2 5-5 7-10 8-11
1-2 1-11 1-12 3-2 4-13 5-5 6-13 7-13 8-4 8-7 8-8 9-3 9-6 9-10 11-1 12-14
1-2 2-2 2-25 3-2 3-26 4-2 4-11 5-36 6-6 6-29 7-8 8-22 9-22 10-2 12-7 12-21 12-42 12-46 13-1 14-23 15-15 15-19 16-16 16-20 17-25 18-29 19-24 19-31 20-6 23-5 23-30 24-8 25-5 25-10 26-9 26-14 28-4 29-3 30-9 31-5 31-43 32-3 33-35 34-36 34-45 35-33 37-13 37-44 38-17 39-3 40-16 40-18 41-30 41-34 42-41 43-5 44-17 45-15 45-16 45-17 46-24 47-29 47-38 48-27 48-39 48-40 49-32 51-31 52-47
1-5 1-23 1-25 2-4 2-8 4-7 4-19 4-22 5-9 6-6 8-5 9-26 10-14 12-9 13-13 14-6 14-20 15-5 15-17 16-15 17-3 18-2 18-16 19-10 20-2 21-15 21-21 22-6 23-10 24-11 24-12 24-13 24-24 26-1 27-27
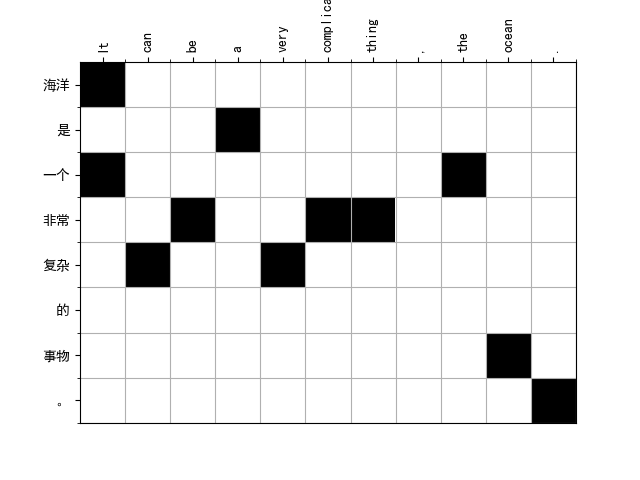
1-15 2-2 3-2 3-3 3-4 3-5 4-12 5-7 6-1 6-21 7-20 8-19 8-20 9-8 10-14 10-18 11-7 11-9 11-10 11-11 12-14 13-4 14-13 15-14 16-6 16-13 17-3 18-6 18-17 19-21词对齐可视化
将第一句词对齐结果进行可视化
python align_plot.py en.txt zh.txt aligned.grow-diag-final-and 0