【NLP】XLnet:GPT和BERT的合体,博采众长,所以更强
前面介绍过BERT,作为一种非常成功的预训练模型,取得了非常不错的成绩,那么,他还有改进的空间吗?
本文介绍BERT的改进版,XLnet。看看它用了什么方法,改进了BERT的哪些弱点。
作者&编辑 | 小Dream哥
1 为什么要有XLnet?
要理解XLnet,我们先回顾一下先于XLnet的两种表现最好的预训练模型BERT和GPT:
1) Generative Pre-Training(GPT),采用Transfomer作为特征抽取器,预训练阶段采用单向语言模型的模式。
2) Pre-training of Deep Bidirectional Transformers for Language Understanding(BERT),同样采用Transfomer作为特征抽取器,与GPT的主要差异在于,在训练阶段,其采用基于MLM的双向语言模型。
XLnet的提出者们,仔细研究了一下这两个模型,发现他们都有自己的缺点。
对GPT,它主要的缺点在于,采用的是单向语言模型。模型在预测当前词的时候,只能看到该词前面词的信息。而对于很多语言理解任务而言,例如阅读理解等,常常需要参考该词前后的语境,因此,单向语言模型往往是不够的。XLnet的研究者称GPT这一类结构为AR(AutoRegressive)语言模型。
对BERT,采用MLM,即在训练时遮住训练语料中15%的词(实际的MASK机制还有一些调整),用符号[MASK]代替,然后试图让网络重建该词。这个过程,在训练语料中引入了符号[MASK]。而在实际的Finetune及预测过程中,是没有这个符号的,这就在预训练和预测阶段之间产生了GAP。BERT在MLM中还隐含了一个独立性假设,即重建各个符号[MASK]的过程,是相互独立的。这个假设其实是未必成立的,会造成模型训练时部分信息的损失。XLnet的研究者称BERT这一类结构为AE(AutoEncoding)语言模型。
由此可见,BERT和GPT都有待改进的地方,XLnet的研究者们的想法是将两个模型结合起来,并改进一些点。下面我们来看看XLnet是如何基于GPT和BERT来做改进的。
2 XLnet的改进
1) 预训练模式的优化:Permutation Language Modeling(PLM)
XLnet想要实现BERT的双向语言模型,但是又不想引入BERT MLM中的独立性假设和符号[MASK],进而提出了PLM。
XLnet中,沿用GPT的语言模型的办法,即基于序列中前面部分的内容,预测该词。但是,为了在预测该词的时候,为了能够看到该词后面部分的内容,对序列进行排列组合。这样的话,该词的前面也包含该词后面词的信息,用另外一种方式,实现了双向语言模型。

如上图所示,假定输入序列的长度为4,则除了原语序,这4个词总共有24种排列方式,上图中用各词在原序列中的位置来表示各词,列出了其中4种,[3,2,4,1],[2,4,3,1],[1,4,2,3],[4,3,1,2]。
有同学会疑问,对于Transformer这种特征抽取器来说,在不加掩码的情况下,不管输入序列按照哪种顺序输入,效果应该都是一样的才对。
没错,因此XLnet还引入了Two-Stream Self-Attention,双流自注意力模型。
所谓双流就是输入包括了两种,训练句子和相应的位置信息,下面看看具体是怎么组织起来的。

如上图所示,输入包括两种类型,query stream和content stream。
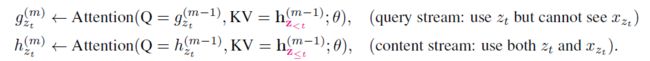
1.query stream仅仅包含输入序列中预测位置前面的词x_(z 2.content stream跟普通的transformer输入一致,包括x_(z_t)及x_(z 通过双流注意力机制,可以有效的学习到双向模型的表征。 2)特征抽取器的优化 在结构上,XLnet采用改进后的transofmerXL作为特征抽取器。前面讲过TransformerXL,他主要有两个优化,一个引入了序列循环机制;一个是引入了相对位置编码。 对于相对位置编码,在XLnet中的应用与之前在transformer的应用别无二致;对于序列循环机制,这里介绍一下在XLnet中是如何应用的。 如上面的公式所示,其实在XLnet中,attention计算与TransformerXL中类似,也是将前一个序列中上一层的隐藏状态,与本序列中上一层隐藏层状态拼接起来。 3 总结 XLnet是一个集合了目前两大预训练模型的优点,其效果自然不会差,目前其在各个任务中的表现都要优于BERT。 XLnet接过BERT的棒,把预训练模型再往前提升了一步。可以遇见,后续NLP预训练还会不断有新的模型出来。 总结 XLnet是BERT一种非常重要的改进,思想值得我们好好学习和研究,希望对你有所帮助。 读者们可以留言,或者加入我们的NLP群进行讨论。感兴趣的同学可以微信搜索jen104,备注"加入有三AI NLP群"。 知识星球推荐 扫描上面的二维码,就可以加入我们的星球,助你成长为一名合格的自然语言处理算法工程师。 知识星球主要有以下内容: (1) 聊天机器人。考虑到聊天机器人是一个非常复杂的NLP应用场景,几乎涵盖了所有的NLP任务及应用。所以小Dream哥计划以聊天机器人作为切入点,通过介绍聊天机器人的原理和实践,逐步系统的更新到大部分NLP的知识,会包括语义匹配,文本分类,意图识别,语义匹配命名实体识别、对话管理以及分词等。 (2) 知识图谱。知识图谱对于NLP各项任务效果好坏的重要性,就好比基础知识对于一个学生成绩好坏的重要性。他是NLP最重要的基础设施,目前各大公司都在着力打造知识图谱,作为一个NLP工程师,必须要熟悉和了解他。 (3) NLP预训练模型。基于海量数据,进行超大规模网络的无监督预训练。具体的任务再通过少量的样本进行Fine-Tune。这样模式是目前NLP领域最火热的模式,很有可能引领NLP进入一个全新发展高度。你怎么不深入的了解? 转载文章请后台联系 侵权必究 往期精选 【NLP】自然语言处理专栏上线,带你一步一步走进“人工智能技术皇冠上的明珠”。 【NLP】用于语音识别、分词的隐马尔科夫模型HMM 【NLP】用于序列标注问题的条件随机场(Conditional Random Field, CRF) 【NLP】经典分类模型朴素贝叶斯解读 【NLP】 NLP专栏栏主自述,说不出口的话就交给AI说吧 【NLP】 深度学习NLP开篇-循环神经网络(RNN) 【NLP】 NLP中应用最广泛的特征抽取模型-LSTM 【NLP】 聊聊NLP中的attention机制 【NLP】 理解NLP中网红特征抽取器Tranformer 【NLP】TransformerXL:因为XL,所以更牛 【NLP】 深入浅出解析BERT原理及其表征的内容 【每周NLP论文推荐】从预训练模型掌握NLP的基本发展脉络 【每周NLP论文推荐】 NLP中命名实体识别从机器学习到深度学习的代表性研究 【每周NLP论文推荐】 介绍语义匹配中的经典文章 【技术综述】深度学习在自然语言处理中的应用


