基于Apache Curator改进的主从组件的开发
一, 问题背景
以前曾基于ZooKeeper的原生Java API 实现的一个分布式主从组件,其基本原理是:
各个节点服务启动时争抢在zookeeper注册临时节点的操作,谁注册了约定的临时节点,谁就是master
详情见:https://blog.csdn.net/hikeboy/article/details/80086379
有一天QA突然发现有个基于该组件的worker服务处于不可用状态,检查2台服务器发现两台服务器上的worker进程都live,但是却2台主备都处于从机状态。
后来追查到根本原因是ZooKeeper的原生Client是不能断网自动重连的
这个实现方式,https://blog.csdn.net/hikeboy/article/details/80086379 在网络环境稳定的时候,挂掉了一台,另外一台能够正常替补成为master,但是当机房出现网络抖动,2台都断网时,2台都会失主,即使网络恢复正常,主备2台都会成为从机。
要解决这个问题,就必须自己去实现ZooKeeper客户端的断网重连的逻辑。调研发现 Apache Curator 已经很好的解决了该问题。
Curator对原生的Zookeeper的API进行了更高级别的封装。通过它可以非常方便的实现基于ZooKeeper的Leader主备,分布式锁,栅栏等,用官方的比喻就是“Curator之于Zookeeper,就好比Guava 之于Java ”
二, 代码实现
Curator 提供的客户端CuratorFramework断网后能够自动重连, 采用Curator改进后的主从组件源码放在我的GitHub:
https://github.com/weimiantong/high-availability-leader-selector
使用demo与断网测试效果:
@Test
public void testDisconnectNetWork(){
try {
ZkConfig zkConfig = new ZkConfig("28.163.0.65:2181", 2000, 1000, "/stock_mot/myFirst");
LeaderSelector masterSelector = new LeaderSelector(zkConfig);
LeaderSelector slaveSelector = new LeaderSelector(zkConfig);
masterSelector.setListener(new LeaderSelectorListener() {
@Override
public void isLeader() {
System.out.println("masterSelector is leader");
}
@Override
public void notLeader() {
System.out.println("masterSelector is not leader");
}
});
slaveSelector.setListener(new LeaderSelectorListener() {
@Override
public void isLeader() {
System.out.println("slaveSelector is leader");
}
@Override
public void notLeader() {
System.out.println("slaveSelector is not leader");
}
});
System.out.println("******** start master ********");
masterSelector.start();
Thread.sleep(1000);
System.out.println("******** start slave ********");
slaveSelector.start();
Thread.sleep(5000);
System.out.println("******** now You can try to disconnect the network ********");
Thread.sleep(10000);
System.out.println("******** please reconnect the network ********");
Thread.sleep(10000);
System.out.println("******** stop master ********");
masterSelector.stop();
Thread.sleep(10000);
System.out.println("******** stop slave ********");
slaveSelector.stop();
} catch (Exception e) {
e.printStackTrace();
}
}
在本地运行此Demo时,masterSelector和slaveSelector 都启动完毕并完成第一轮抢主后,看到“******** now You can try to disconnect the network ”,我通过禁用网卡的方式模拟断网。
看到“ please reconnect the network ********” 重新联网。
输出如下:
******** start master ********
masterSelector is leader
******** start slave ********
******** now You can try to disconnect the network ********
masterSelector is not leader
******** please reconnect the network ********
masterSelector is leader
******** stop master ********
slaveSelector is leader
******** stop slave ********
多试几次,也有可能输出如下:
******** start master ********
masterSelector is leader
******** start slave ********
******** now You can try to disconnect the network ********
masterSelector is not leader
******** please reconnect the network ********
slaveSelector is leader
******** stop master ********
******** stop slave ********
可以看出,基于Curator的实现,能够实现断网自动重连,重连之后,重新抢主。
三,原理简析
Curator的抢主原理,比上一版的原理
“各个节点服务启动时争抢在zookeeper注册临时节点的操作,谁注册了约定的临时节点,谁就是master” 有很大不同。
Curator 的各个功能的基础都是一个分布式InterProcessReadWriteLock,谁获取到锁,谁就是主。
Curator的选主核心算法在源码
LockInternals.internalLockLoop 和StandardLockInternalsDriver.getsTheLock中实现
首先各个客户端启动时都能在指定的永久节点下成功创建一个自己的临时节点,
临时节点的名称 = “全局的UUID + 10位递增顺序序号”
节点内容=“写入该节点的客户端名称”
![]()
抢锁原理:
1,获取所有的顺序临时子节点序号
2,判断本节点的序号是否是最小的一个,是则获取锁成功
3,获取锁失败,说明不是最小的一个,则把比它小的前一个节点纳入监听
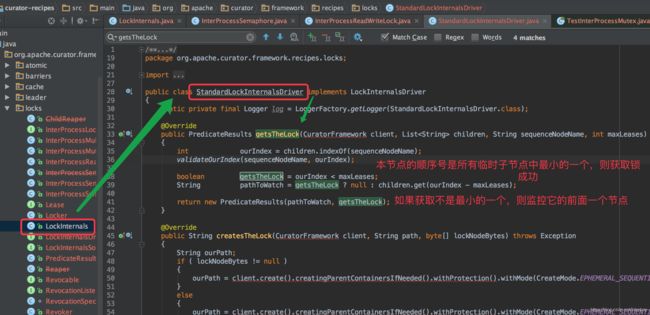
这样,Curator每次都是序号最小的一个获得锁,而其他没有获得的只需要监控排在它前面的一个节点的变化即可,无需监听所有节点的变化。
总结Curator 原理: 给每个节点按顺序编号,谁是存活节点中序号最小谁就是主