CNN网络结构进化概述
网络工程问题是深度学习中比较基础的问题,网络工程的难点在于,缺乏对深度神经网络的理论理解(即常说的黑盒模型),无法根据理论来设计网络结构,实际中更多的是不断的尝试,根据实验反馈出来的结果确定某一结构是不是好的结构。在这些尝试中,CNN是一种非常成功的网络形式,CNN的网络结构迭代速度也非常快,诸如大家所熟知的AlexNet,VGGnet,GoogleNet,ResNet,ResNext,DenseNet等等井喷式地出现,这些网络并不是凭空遐想,其设计背后有着一定的逻辑,在演进过程中有创新也有传承。
本文试图简单梳理CNN网络发展脉络,探究网络结构演进背后的逻辑。

上图是CNN网络主要发展脉络的一种描述(但绝不是全部)。网络工程主要可以包括两个方面:连接结构设计和运算操作符设计(structure space和operator space)。
连接结构设计:网络层次设计与层次之间的连接方式,如网络深度和宽度,bottleneck,shortcut,branches,RoI pooling layer等;
运算操作符设计:网络运算符设计,如激活函数(ReLU等),数据处理(Xavier、Batch Normarlization等),特殊卷积(Holed Convolution、group convolution等),特殊池化,损失函数(Focal loss等)。
- LeNet(1998 )
上世纪九十年代末,Yann LeCun将BP算法应用到CNN网络中用于手写字符,LeNet成为第一个具有实用价值的CNN神经网络。LeNet结构为conv1+pooling1+conv2+pooling2+fc,五层结构。LeNet奠定了CNN的三大核心思想:局部感受野,权值共享,下采样。使得神经网络能够在图像领域得到应用。但由于当时计算力和数据限制,加上缺乏理论支持,LeNet火了一把之后就沉寂了,直到2012年AlexNet横空出世。
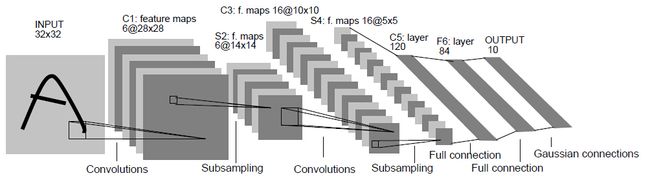
- AlexNet(12年ImageNet Challenge冠军,2012 NIPS)
AlexNet的成功不是因为理论的巨大创新,而是计算力和数据限制得以突破(GPU和ImageNet),同时,在LeNet的基础上网络结构也做了一些优化(主要就是加深了)。在连接设计方面:卷积层数量增加到5层,卷积层尺度有11x11、5x5、3x3多种,全连接层增加到3层;在运算符操作符方面:使用ReLU替代sigmoid作为激活函数来加速训练,使用Dropout为网络引入ensembling减少过拟合,使用LRN做数据的归一化(后来证明作用不大)。至于论文中提到的创新点之一Data Arguemetation属于数据预处理,不在网络结构讨论范畴。

- VGGNet(2014 ImageNet Challenge, 2015 ICLR)
可以看成是加深版的AlexNet,整体框架还是和LeNet和AlexNet类似,都是conv layer+FC layer。创新在于,因为一个5x5的卷积可以由两层3x3的卷积等效,同时参数数量减少(25 vs 18),所以VGG卷积模板尺寸全部为3x3,使得网络单元模块化,可以象拼积木一样进行组合,架起一个网络就像火车车厢拼接一样简单。VGG有多个版本,取决于用了多少个基本单元,但都有与AlexNet一致的3个FC layer,意味着参数还是很多。容易拼接并不等于可以无限加深网络,过深的网络非常难训练,需要stage-wise training,即训练了11层的VGG的基础上再训练13层的,在13层训练好的基础上再训练16层的。同时,深层网络往往有梯度消失或梯度爆炸的问题,需要非常好地初始化参数(常用Xavier或MSRA,它们都是逐层初始化,而不是像传统的Recap只对输入做初始化)。这些掣肘的问题意味着VGG网络很难实用。

- NIN(2014 CVPR)
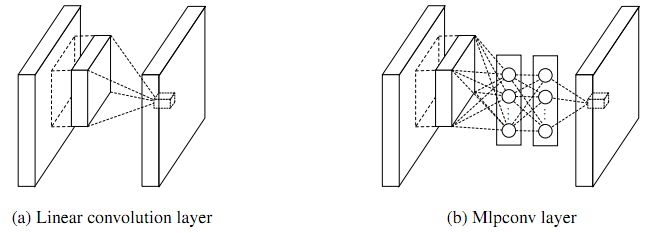
NIN-Network in Network对CNN的卷积层做了一个较大的革新,经典CNN中的卷积层其实就是用线性滤波器对图像进行内积运算,这种卷积滤波器是一种广义线性模型(GLM),类似于单层神经网络,GLM的抽象能力是比较低水平的。NIN采用了MLP即多层感知器作为卷积层模型提高了非线性,实际操作起来也很简单,只需要在经典卷积层后嵌套两组1x1的卷积层就可以实现。NIN的另一个改进是用全局均值池化的方法替代传统CNN中的全连接层,对每个特征图一整张图片进行全局均值池化,这样每张特征图都可以得到一个输出,对应着一个类别,可以理解为由于采用了mlpconv,网络在前面卷积阶段特征提取得足够好,后面就不需要再用FC layer来增加非线性了,极大地减少了参数和overfitting风险。
- GoogLeNet(2014 ImageNet Challenge, 2015 CVPR)
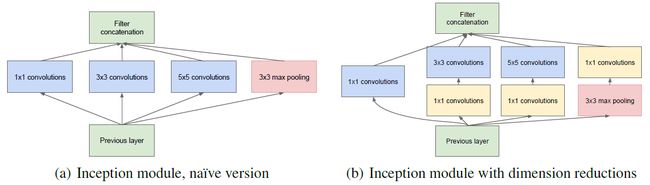
GoogleNet和NIN一脉相承,主要是在卷积层上做了较大的改进,在网络加深的同时,将卷积层的网络拓宽(这里拓宽的意思与传统神经网络增加单层网络节点是不一样的,后者对应到CNN中应该是增加filter数目即增加通道数,而这里的拓宽可以简单认为是结构图看起来更宽),其主要特征是用了Inception结构。Inception结构前后有4个版本,Inception V1版本逻辑很简单,不同于一般把网络加深的方法,Inception V1索性把不同尺度的卷积和pooling同时平行地进行然后把结果拼起来组成一个block,把加深变成加厚,在同一层就能提取不同尺度信息,同时获得非线性属性,而不需要再依赖ReLU或者pooling增加非线性,如下图(a)所示。但是出于控制参数量的考虑,单纯加厚显然不合适,于是参考NIN,在3x3,5x5,pooling上加分支上加1x1的卷积,如图(b)。
Inception V2 和V3讨论集成了Inception中的许多Tricks,包括在Inception block中,与其用7×7 尺寸的卷积,不如用一对 1×7 和 7×1 卷积更高效(熟悉SIFT特征的同学应该不陌生)。另外值得一提的是引入Batch Normalize做初始化,为什么不用Xavier或MSRA呢?因为它们不适用于多分支网络,BN不仅逐层初始化,而且是对每个mini-batch做。Inception V4更是将Inception标准化模块化,什么样的输出应该用什么样Inception Block都定好了,直接像积木一样堆就行。将模块拼到ResNet上就成了Inception-ResNet。
何凯明在17年CVPR的报告中总结GoogLeNet时,总结Inception系列三大基本结构:Mutiple branches(1x1,3x3,5x5,pool),Shortcut(stand-alone 1x1 , merged by concat),Bottleneck(reduce dimension by 1x1 before 3x3/5x5 conv )。
- ResNet(2016 CVPR Best Paper,深度达到152层)
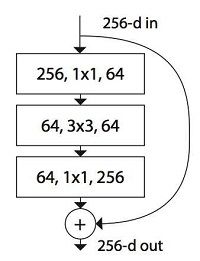
ResNet的出现是解决普通网络随着深度增加,性能反而下降的问题,这个问题是由实验印证得到的,造成这个问题的原因是梯度消失而非过拟合。ResNet通过引入一条shortcut使得信息跨层流动,缓解了梯度消失的问题。作者认为,优化残差映射比优化原始的映射更容易,在极端情况下,如果一个标识映射是最优的,那么将残差值推到零将比通过一堆非线性层来匹配一个恒等映射更容易。网络加深后参数过多,所以引入了Bottleneck即1x1的卷积来减少参数(也可以控制维度)。ResNet与GoogLeNet类似的结构是:Shortcut和Bottleneck,但没有用到Mutiple branches(恒等映射通常不能算是branch),何凯明在2017CVPR推出的新作ResNeXt就是在ResNet基础上引入Mutiple branches。

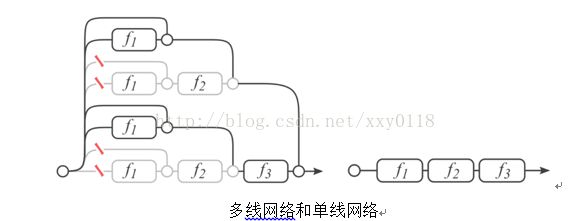
Cornell University的几个人研究了ResNet,发现它所谓的“超深网络”只是个噱头,它本质上是一堆浅层网络的集合——《Residual Networks are Exponential Ensembles of Relatively ShallowNetworks》,一个拥有三个block的ResNet可以展开为下图的形式,类似于多个网络的ensemble形态,所以精度很高。这种看法有一定争议,但可以为我们剖析网络结构提供一种思路。

少个block情况下,对ResNet影响甚微,而VGGNet就惨不忍睹了。因为,多线网络少个block,网络仍然是通的,单线网络少个block,网络断开。我个人认为,这里网络断开可以理解为梯度消失,所以ResNet对梯度消失不敏感。
- Xception(v4 2017 arxiv by Google) 和 ResNext(2017 CVPR by FAIR)
之所以把这两个放到一起说,是因为它们分别在Inception和ResNet的基础上,都做了比较类似的改进——稀疏连接(sparse connection)。卷积神经网络爆发前,都是全连接网络,即上一层图像W*H*C都对下一层有贡献,卷积神经网络是将W和H局部感知了,但对通道C还是全部使用了。ResNext模型中,作者提出了Cardinality这个概念,可以理解为通道的分组数。首先使用逐点卷积减少输入特征的通道数,再利用计算量较小的分组卷积(group convolution)结构取代原有的卷积运算,减少整体的计算复杂度。下图左边是ResNet的一个单元,右边是ResNext的单元,左边可以看作Cardinality=1,右边是Cardinality=32。

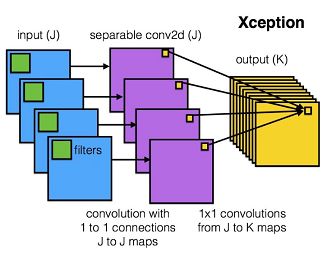
Xception模型中,将普通的卷积运算拆分成逐通道卷积(depthwise convolution)和逐点卷积(pointwise convolution)两部进行,有效地减少了计算量和参数量,在做卷积计算的时候,每一个通道内的数据做单独计算,如果有N维通道则有N维输出,那么相当于Cardinality等于N。
- ShuffleNet( Jul 2017 arXiv by Face++ )
ShuffleNet网络结构同样沿袭了稀疏连接的设计理念。作者通过分析Xception和ResNeXt模型,发现这两种结构通过卷积核拆分虽然计算复杂度均较原始卷积运算有所下降,然而拆分所产生的逐点卷积计算量却相当可观,成为了新的瓶颈。受ResNeXt的启发,作者提出使用分组逐点卷积(group pointwise convolution)来代替原来的结构。通过将卷积运算的输入限制在每个组内,模型的计算量取得了显著的下降。然而这样做也带来了明显的问题:在多层逐点卷积堆叠时,模型的信息流被分割在各个组内,组与组之间没有信息交换(如下图 (a)所示)。需要打乱各组的信息(如下图(b)所示),所以引入了一种方便的方法——通道重排(channel shuffle)(如下图(c)所示)。结果是参数大大减少,可以在arm这样的硬件上实现。关于卷积的各种形式可以参考CNN中千奇百怪的卷积方式大汇总。

- DenseNet(2017 CVPR best paper)
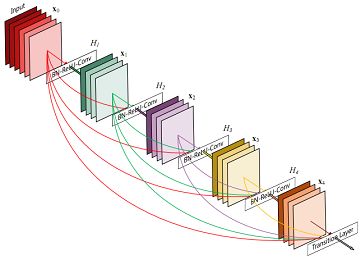
DenseNet与ResNet和Highway Network有相似之处,核心是在网络结构中加入shortcut,使得信息不仅能从上一层流入相邻的下一层,还能跨层建立连接,相比于ResNet的跨一层,DenseNet更是将shortcut思想更极端地展现出来。优势:有效解决梯度消失问题;强化特征传播 ;支持特征重用;大幅度减少参数数量。为了减少模型参数,在dense block里面采用bottleneck layers。同时compression的操作减少Feature Map数量。但代价是内存占用很厉害。

参考文献:
论文就不列举了,主要列一下比较好的博客,方便大家理解。
大牛讲堂|Batch Normalization的分析与展望:http://qingmang.me/articles/-3789820675106857200/
NIN-Network In Network阅读笔记:http://blog.csdn.net/hiterdu/article/details/45418545
Network in Network-读后笔记:https://www.jianshu.com/p/96791a306ea5
Network in Network网络分析: http://blog.csdn.net/mounty_fsc/article/details/51746111
Inception深度网络家族盘点:http://nooverfit.com/wp/inception%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%AE%B6%E6%97%8F%E7%9B%98%E7%82%B9-inception-v4-%E5%92%8Cinception-resnet%E6%9C%AA%E6%9D%A5%E8%B5%B0%E5%90%91%E4%BD%95%E6%96%B9/#more-3865
GoogLeNet学习心得:http://www.cnblogs.com/Allen-rg/p/5833919.html
Inception in CNN:http://blog.csdn.net/stdcoutzyx/article/details/51052847
Deep Residual Networks学习: https://zhuanlan.zhihu.com/p/22071346
ResNet学习: http://blog.csdn.net/xxy0118/article/details/78324256
Google Xception Network:http://blog.csdn.net/shuzfan/article/details/77129716
[DL-架构-ResNet系] 003 ResNeXt: https://zhuanlan.zhihu.com/p/29679851
无需数学背景,读懂 ResNet、Inception 和 Xception 三大变革性架构:https://www.jiqizhixin.com/articles/2017-08-19-4
ResNext与Xception——对模型的新思考: https://zhuanlan.zhihu.com/p/28839889
ShuffleNet和MobileNet对比:https://xueqiu.com/3426965578/88678286
CNN中千奇百怪的卷积方式大汇总: https://zhuanlan.zhihu.com/p/29367273