【03】Flink 之 DataStream API(一):Data Source 和 自定义Source
1、Data Source
1.1、Data Source介绍
- source是程序的数据源输入,可以通过StreamExecutionEnvironment.addSource(sourceFunction)来为程序添加一个source。
- flink提供了大量的已经实现好的source方法,也可以自定义source
- 通过实现sourceFunction接口来自定义无并行度的source,
- 或者你也可以通过实现ParallelSourceFunction 接口 or 继承RichParallelSourceFunction 来自定义有并行度的source。
1.2、Data Source类型
-
基于文件
(1)、 readTextFile(path)
(2)、读取文本文件,文件遵循TextInputFormat 读取规则,逐行读取并返回。 -
基于socket
(1)、 socketTextStream;
(2)、从socker中读取数据,元素可以通过一个分隔符切开。
在WordCount中即是通过Socket实现数据读取
-
基于集合
(1)、fromCollection(Collection) ;
(2)、通过java 的collection集合创建一个数据流,集合中的所有元素必须是相同类型的。 -
自定义输入
(1)、addSource 可以实现读取第三方数据源的数据
(2)、系统内置提供了一批connectors,连接器会提供对应的source支持【kafka】
2、基于集合实现Source的实现
2.1、Java代码实现
package com.Streaming;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
/**
* @Author: Henry
* @Description: 把collection集合作为数据源
* @Date: Create in 2019/5/12 10:12
**/
public class StreamingFromCollection {
public static void main(String[] args) throws Exception{
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ArrayList data = new ArrayList<>();
data.add(10);
data.add(15);
data.add(20);
//指定数据源
DataStreamSource collectionData= env.fromCollection(data);
//通map对数据进行处理
DataStream num = collectionData
.map(new MapFunction() {
@Override
public Integer map(Integer value) throws Exception {
return value+1 ;
}
});
//直接打印
num.print().setParallelism(1);
env.execute("StreamingFromCollection");
}
}
2.2、Java代码运行结果
运行结果输出:
即实现对输入collection数据进行“加1”操作。

如果编译报错如下:

找不到主类依赖,则查看pom文件:
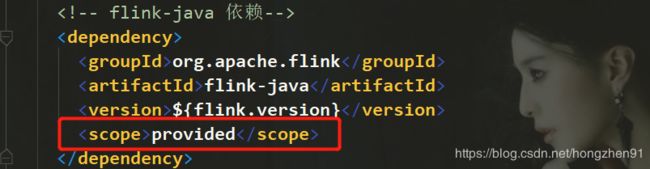
如有< scope>选项的依赖,则将其注释:
2.3、Scala代码实现
package cn.Streaming
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* @Author: Henry
* @Description:
* @Date: Create in 2019/5/13 22:47
**/
object StreamingFromCollection {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val data = List(10, 15 , 20)
val text = env.fromCollection(data)
//针对map接收到的数据执行加1的操作
val num = text.map(_ + 1)
num.print().setParallelism(1)
env.execute("StreamingFromCollectionScala")
}
}
2.4、Scala运行结果

3、自定义Source的实现
3.1、Source容错性保证
| Source | 语义保证 | 备注 |
|---|---|---|
| Kafka | exactly once(仅一次) | 建议使用 Kafka 0.10以上版本 |
| Collections | at least once | |
| Files | exactly once | |
| Sockets | at most once |
3.2、Flink内置Connctors
- A p a c h e K a f k a ( s o u r c e / s i n k ) \color{red}{Apache Kafka (source/sink)} ApacheKafka(source/sink)
- Apache Cassandra (sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache ActiveMQ (source/sink)
- Redis (sink)
3.3、实现无并行度的自定义Source
- implements实现SourceFunction接口;
- 重写run方法和cancel方法(cancel应用时,cancel方法会被调用)
; - 一般不需要实现容错性保证
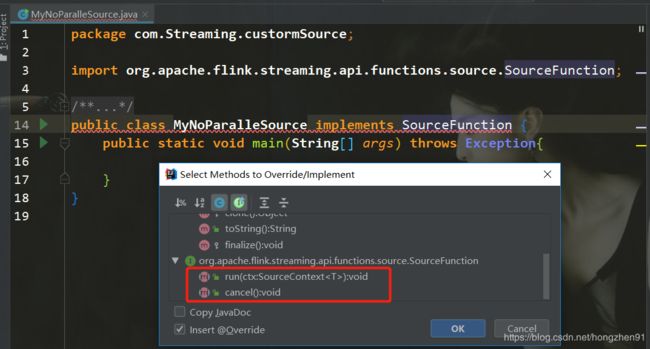
3.3.1、run方法重写(主要的方法):
- 启动一个source
注意:继承接口 SourceFunction的时候需要指定泛型,否则会报错
如:SourceFunction,即run中产生的数据类型
SourceFunction 和 SourceContext 都需要指定
- 在大部分情况下,都需要在这个run方法中实现一个循环,就可以循环产生数据
- 传入参数 (SourceContext ctx)
在这里插入代码片
@Override
public void run(SourceContext ctx) throws Exception {
while(isRunning){
ctx.collect(count);
count++;
//每秒产生一条数据
Thread.sleep(1000);
}
}
3.3.2、cancel方法重写
- UI中点击一个cancel的时候会调用该方法
- 外部通常参数控制该方法的结束
@Override
public void cancel() {
isRunning = false;
}
此时运行会报错:
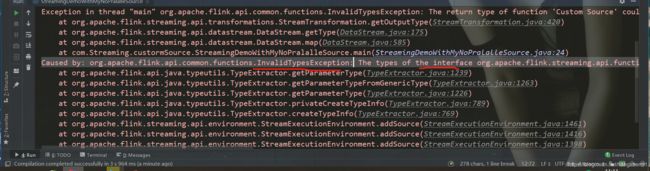
无效接口类型:
Caused by: org.apache.flink.api.common.functions.InvalidTypesException: The types of the interface org.apache.flink.streaming.api.functions.source.SourceFunction could not be inferred. Support for synthetic interfaces, lambdas, and generic or raw types is limited at this point
原因:
SourceFunction接口需要指定泛型

此时,正确运行:
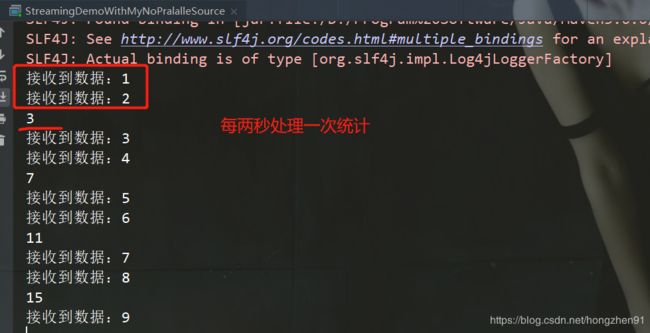
注意,针对此Source,并行度只能设置为1
new MyNoParaSource().setParallelim(1) ,如果将并行度修改为2,则会运行报错:

3.3.3、Java代码实现
MyNoParalleSource:
package com.Streaming.custormSource;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
/**
* @Author: Henry
* @Description: 自定义实现并行度为1的source
* 模拟产生从1开始的递增数字
* @Date: Create in 2019/5/12 10:45
*
* 注意:
* SourceFunction 和 SourceContext 都需要指定数据类型,如果不指定,代码运行的时候会报错
**/
public class MyNoParalleSource implements SourceFunction {
private long count = 1L;
private boolean isRunning = true;
/**
* 主要的方法
* 启动一个source
* 大部分情况下,都需要在这个run方法中实现一个循环,这样就可以循环产生数据了
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext ctx) throws Exception {
while(isRunning){
ctx.collect(count);
count++;
//每秒产生一条数据
Thread.sleep(1000);
}
}
/**
* 取消一个cancel的时候会调用的方法
*
*/
@Override
public void cancel() {
isRunning = false;
}
}
主程序StreamingDemoWithMyNoPralalleSource:
package com.Streaming.custormSource;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* @Author: Henry
* @Description: 自定义实现并行度为1的source
* @Date: Create in 2019/5/12 10:45
*/
public class StreamingDemoWithMyNoPralalleSource {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource text = env.addSource(
new MyNoParalleSource()).setParallelism(1); //注意:针对此source,并行度只能设置为1
DataStream num = text.map(new MapFunction() {
@Override
public Long map(Long value) throws Exception {
System.out.println("接收到数据:" + value);
return value;
}
});
//每2秒钟处理一次数据
DataStream sum = num.timeWindowAll(Time.seconds(2))
.sum(0);
//打印结果
sum.print().setParallelism(1);
// 获取类名
String jobName = StreamingDemoWithMyNoPralalleSource.class.getSimpleName();
env.execute(jobName);
}
}
3.3.4、Scala代码实现
MyNoParallelSourceScala:
package cn.Streaming.custormSource
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
/**
* @Author: Henry
* @Description: 创建自定义并行度为1的source
* 实现从1开始产生递增数字
* @Date: Create in 2019/5/13 22:57
**/
class MyNoParallelSourceScala extends SourceFunction[Long]{
var count = 1L
var isRunning = true
override def run(ctx: SourceContext[Long]) = {
while(isRunning){
ctx.collect(count)
count+=1
Thread.sleep(1000)
}
}
override def cancel()= {
isRunning = false
}
}
主程序StreamingDemoWithMyNoParallelSource:
package cn.Streaming.custormSource
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @Author: Henry
* @Description:
* @Date: Create in 2019/5/13 23:04
**/
object StreamingDemoWithMyNoParallelSource {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val text = env.addSource(new MyNoParallelSourceScala)
val mapData = text.map( line => {
println("接收到的数据:"+line)
line
})
val sum = mapData.timeWindowAll(Time.seconds(2))
.sum(0)
sum.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
3.3.5、Scala运行结果
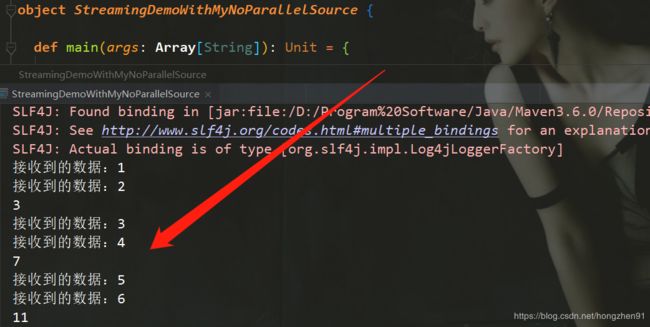
3.4、实现有并行度的自定义Source
3.4.1、Java代码实现ParallelSourceFunction
代码同上一样
public class MyParalleSource implements ParallelSourceFunction {
... // 同上
}
- 实现ParallelSourceFunction
- 或者继承RichParallelSourceFunction
3.4.2 Java运行结果
注意:
如果使用该自定义Source,如果代码中没有设置并行度,会根据机器性能自动设置并行度。
如机器是8核,则打印出来有8个并行度的数据

进行设置并行度:
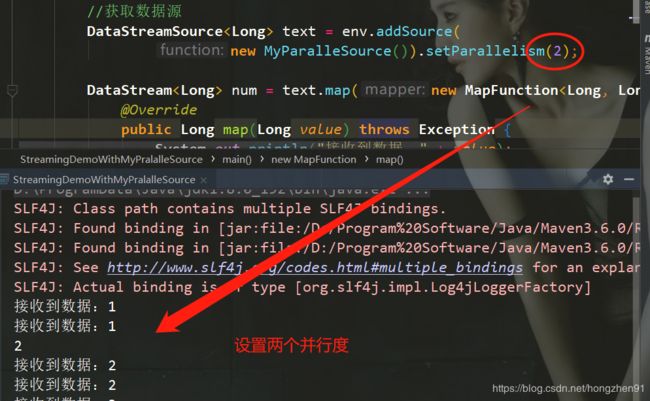
3.4.3、Scala代码实现ParallelSourceFunction
代码同上一样
class MyParallelSourceScala extends ParallelSourceFunction[Long]{
... // 同上
}
3.4.4、Scala运行结果
输出结果:
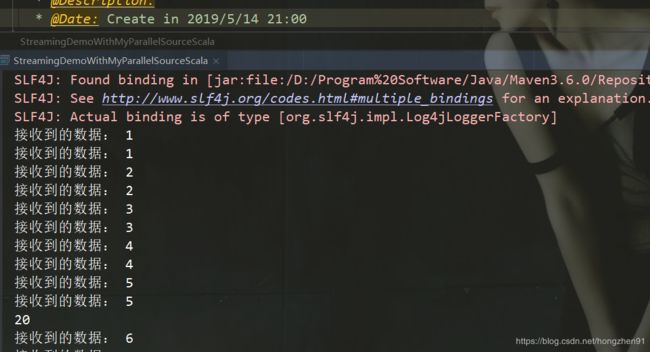
3.4.5、Java代码实现RichSourceFunction
代码其他部分同上,新增部分如下:
public class MyRichParalleSource extends RichParallelSourceFunction {
... // 同上代码
/**
* 这个方法只会在最开始的时候被调用一次
* 实现获取链接的代码
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("open.............");
super.open(parameters);
}
/**
* 实现关闭链接的代码
* @throws Exception
*/
@Override
public void close() throws Exception {
super.close();
}
}
3.4.6、Java 运行结果
运行结果如下:

3.4.7、Scala代码实现RichSourceFunction
代码其他部分同上,新增部分如下:
class MyRichParallelSourceScala extends RichParallelSourceFunction[Long]{
... // 同上代码
/**
* 这个方法只会在最开始的时候被调用一次
* 实现获取链接的代码
* @param parameters
*/
override def open(parameters: Configuration): Unit = super.open(parameters)
/**
* 实现关闭链接的代码
*/
override def close(): Unit = super.close()
}
3.4.8、Scala运行结果
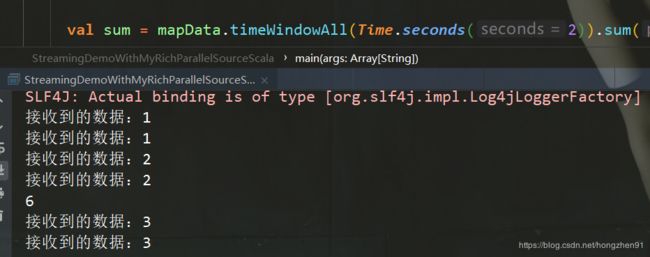
3.4.9、两种有并行度区别
- RichSourceFunction和ParallelSourceFunction区别:
RichSourceFunction 除了实现了ParallelSourceFunction接口,还继承
了AbstractRichFunction
@Public
public abstract class RichParallelSourceFunction extends AbstractRichFunction
implements ParallelSourceFunction {
private static final long serialVersionUID = 1L;
}
- 额外多提供了open()和close()方法
- 针对source中如果需要获得其他链接资源,那么可以在open()方法
中获取资源链接,在close中关闭资源链接
下一节:Flink 之 DataStream API(二):Transformations 操作