gragh embedding相关论文小结(一)
以下是对所读过的各篇论文中的思想简短总结
- A Comprehensive Survey of Graph Embedding-problems,Techniques and Applications
- Graph Embedding Techniques,Applications,and Performance:A Survey
- DeepWalk: Online Learning of Social Representations
- code2vec: Learning Distributed Representations of Code
- node2vec: Scalable Feature Learning for Networks
- PRUNE:Preserving Pxoximity and Global Ranking for Network Embedding
A Comprehensive Survey of Graph Embedding-problems,Techniques and Applications
本文是一篇关于graph vector或者graph embedding或者graph representation的综述,graph embedding有别于NRL(Network Representation Learning),后者有诸多论文可以拜读,在此先记下链接:https://github.com/thunlp/NRLPapers/blob/master/README.md
本篇论文为一篇综述,关于graph Embedding,即将graph表示为低维度的embedding。文中分为problem settings和embedding techniques两部分。前者又分为graph input 和embedding output,input就有四种同质图/非同质图/辅助信息图/无关数据构造的图,都有不同的特征和信息量。输出也分为node embedding/edge embedding/hybrid embedding/whole-graph embedding。要实现graph embdding,首先面临的选择就是选择到底想要哪种output embedding。在谈到preserved graph property时,文中引入了常用的k-th-order proximity,其insight来源于”two nodes are more similar if they are connected by an edge with larger weight”,这需要又edge weight。解决技术方面又分为matrix factorization/Deep Learning/edge reconstruction/graph kernel/generative model/hybrid techniques。每种方法中的每种技术都有其insight,重点关注点在DL方法。Deep Learning方法又分为with random walk和without random walk。使用random walk的方法,将随机游走视为sampling method来对graph进行采样得到可以刻画graph property的N条path,首当其冲的论文便是DeepWalk,DeepWalk=random-walk+SkipGram。在其之后群雄并起,诸多论文进行改进,论文以图表形式说明:

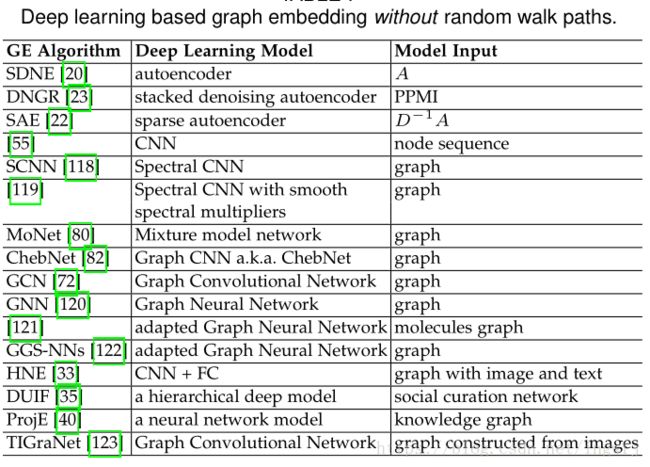
而without random walk的DL方法中则是提到了autoencoder自编码器,CNN-GCN和其他的方法:
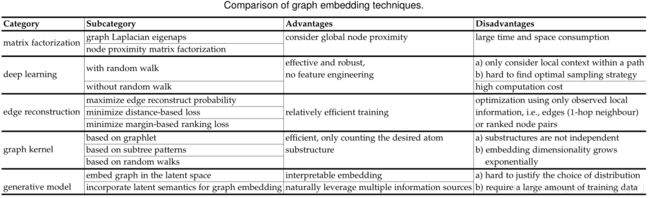
各种技术又自己的优点和缺点:
graph embedding的应用就有很多了,关键时转化为vector之后可以容易操作,例如node classification,node clustering,node recommendation/randking,link prediction/triple classification,graph classification/visulizaiton等。最后文中提到了未来的研究方向,其一是计算效率的问题,计算量太大计算时间太长;其二是动态图问题,之前提到的基本只适用于static graph而非dynamic graph,但是现实中一般都是动态图,streaming graph;其三是对graph的操作粒度;其四是对embedding的应用扩展。
Graph Embedding Techniques,Applications,and Performance:A Survey
本篇论文仍然是一篇survey,关注点在于node embedding。似乎很多领域中开头都有insight,就像执意中的灵感和原则一样。”The higher the edge weight,the more similar the two nodes are expected to be”。论文中仍然提到了衡量graph节点结构和相似度的first-order proximity/second-order proximity/n-order proximity,一阶估计值衡量两个存在边链接的节点的相似度,而二阶衡量不直接相连节点的相邻结构的相似度,更高阶估计值可能衡量的范围再基于每个点“往外扩”,更关键的是有效的算法或者模型却是都在试图preserving这些proximity,而preserving更高的proximity则效果更好。作者提到用来定义higher-order proximity的方法有Katz Index,Rooted PageRank,Common Neighbors,Adamic Adar等,具体是什么还没有细看。同样提到常用来表示graph的方式有邻接矩阵(表示节点相邻关系)/拉普拉斯矩阵(表示graph的一种巧妙方法,半正定,定义是度矩阵-邻接矩阵)/节点概率转移矩阵(猜测就是马尔科夫n阶概率转移矩阵,这个可以通过C-K方程求解)/Katz相似度矩阵(表示节点相似度的有全局相似度和局部相似度,而全局相似度方法有Katz/LHN相似度,局部则是Jacard/Salton相似度)等。
论文中提到的具体方法:LLE(局部线性表示),每个节点的embedding都是neighbors nodes的embedding的线性组合,所以就有了以差为核心的目标函数,也就成了带约束的优化问题,这里将其转换为矩阵特征值问题,这个暂时还不明白为什么;Laplacian特征映射,就是单纯的使用拉普拉斯矩阵来求解,具体方式是对拉普拉斯矩阵进行特征值分解得到最小的d个特征值对应的特征向量,这里需要细看;柯西graph embedding,改了上面的拉普拉斯矩阵分解,具体改了之后的结果又成了带约束的优化问题,更加关注相似节点;SPE,对拉普拉斯特征映射的改进,由embedding重构graph;GF,第一个效率达到O(|E|)的算法,具体方式就是对邻接矩阵与两个节点的embedding内积作差辅以正则化因子来最小化差,只针对有边相连的vertice pair;GraRep,常常提到的方法,使用了节点转移概率矩阵并通过最小化目标函数来试图保留K-order proximity;HOPE,类似于GraRep,它用的是相似矩阵,而相似的度量方法有Katz Index/Rooted PageRank,Common Neighbors/Adamic-Adar score,并用上了SVD;或者把从矩阵得到embedding视为降维过程,或者借助辅助信息来解决;DeepWalk,random walk+word2vec;node2vec,兼顾DFS和BFS,实现更优的random walk;HARP,相较于DeepWalk采用更好的初始化权重的方法;Walklets,修改了DeepWalk的random walk策略,采用跳跃式的采样,说是为了结合显示模型和隐式的random walk;SDNE,旨在保留first&second order network proximity,既用到了autoencoder,又用到了拉普拉斯矩阵;DNGR,结合deep autoencoder和random surfing;GCN,对graph进行卷积操作。以及之后的一系列在GCN上修改的论文,这些方法不同在于卷积核的构造,大体分为spatial filter和spectral filter;LINE,用KL距离来最小化邻接矩阵中对应的节点和embedding点积各自组成的联合概率的差值。
与众不同的是论文后面提到了各个不同应用和数据的实验和分析,还有embedding维度d的规律,以及各算法中超参数的重要度。实验证明d对实验结果的规律是先增后减的,有最优值 但是无法获知。
DeepWalk: Online Learning of Social Representations
这是一篇发表于KDD 2014的论文,算是使用神经网络进行graph-to-vector鼻祖的论文,后续的很多论文在此基础上或对其进行借鉴加以改进的。DeepWalk解决的问题就是学习到graph的特征形成一个固定长度的实数值,连续的,稠密的特征向量,之后就可以利用该向量去实现分类或者相似度检测等应用,这里的向量是针对节点的。采用的方法就是random walk+skip-gram。随机游走会从graph中选择出各种固定长度的path,从某个点随机走到相邻的某点直至到达规定长度。random walk可以作为搜索全局最优点的方法,同时也可以模拟现实情况的算法。论文实际将这条path类比成了NLP中的sentence或者phrase,节点类比于word,之后送入skip-gram模型进行处理。这里不明白的是为什么是skip-gram而非CBOW模型,CBOW模型的效果可能要好一些。当然得到的结果也是每一个node(word)表示为vector。其中也是用到skip-gram中的Hierarchical Softmax优化方法(利用haffuman树来实现取代单纯的softmax输出层从而减少计算量加快速度,具体见https://blog.csdn.net/qq_35732097/article/details/78903981),用的图符合power-law幂律分布,论文中的实验也是表明DeepWalk的效果要好于那些Baseline方法(SpectralClustering,Modularity,EdgeCluster,wvRN,Majority)
这种方法的好处在于:能够并行,模拟实际graph建模的情况,而且抓住graph 的local information.可以应对大图即节点非常多的graph。
这种方法的缺点在于:采样方法上面,随机游走模拟随机事件的发生,认为从i节点到相邻的节点是等概率的,但是现实情况很多不是这样的,节点之间的转移很有可能不是等概率的,那如果还按照先采样再训练的思路来就要改变采样策略,而这一切来源于实际应用情景的各种假设。另外取得固定长度导致注重local information而看不到global information。
code2vec: Learning Distributed Representations of Code
这篇论文是把一段代码转化为vector,之后通过该vector预测这段代码的功用,相当于多标签分类。论文中借鉴传统的代码分析手段,将code解析为AST抽象语法树,之后从这棵树上开始取路径path,实际上是认为这些path就可以刻画出这段代码的特征,取出的路径包括三部分(起点,中间的节点和上下标志,终点),之后将其视为三个向量,简单拼接起来之后经过一层神经网络将拼接的向量转化为一个固定长度的向量,假设取出了n条path,那么得到n个长度为d的vec,之后采用attention机制,因为有些路径包含反应代码中关键节点或者语法内容或者语义内容的节点,所以需要给出不同的权重从而想到使用注意力机制来实现,之后便可以得到一个长度为m的向量,这便是那个code2vec的vector,使用该vector经过一层softmax得到各预先设定好的函数名(函数名代表这段代码的功用)类别标签对应的概率,从而可以使用SGD进行更新参数。模型的结构实际总体借鉴了NLP的CBOW模型,当然没有用其的Hierarchical Softmax和negative sample优化方法,估计是因为没有那么大的标签数量。这篇文章实际和《DeepWalk》那篇文章思想还是有些类似的,都是用某种方法提取path,之后用神经网络处理刻画原始数据特征的这些path,得到vector。
这样做的好处是:
这样做的坏处是:
node2vec: Scalable Feature Learning for Networks
https://blog.csdn.net/myofficials/article/details/78903118
PRUNE:Preserving Pxoximity and Global Ranking for Network Embedding
2017年NIPS上的一篇论文。看到这篇论文时心中狂喜,因为它第一个涉及到了node ranking值,就是节点重要度的衡量和学习。之前经典的PageRank和HITS算法都是通过迭代来完成这种无监督学习任务的,而这里通过一个”carefully designed objective function”来学习node ranking。但是仔细一读,发现模型实际目标在于学习node embedding,而node ranking实际是其一部分task。论文中采用的是孪生神经网络,这种神经网络想法很巧妙,接受成对的输入数据,经过相同参数结构的model之后用两个输出的function作为目标函数,来优化神经网络的参数,这样不需要标签完成无监督学习因为每次都有两个结果来操作,这两个结果可以进行数学运算,而Siamese neural network多用于相似度检测/问答联系,在我看来应该是适用于输入的两个对象之间有联系的情况,这个联系可能是相同或相似,可能是问答,可能是对立。这个模型有两个任务输出:proximity represention和node ranking score,每次接受一个边相连的两个节点的node embedding。得到这两个node对应的proximity presentation和ranking score之后就可以设计用于优化模型的目标函数了。其中论文花了最大的篇幅来讲解那个精心设计的objective function:
![]()
这个目标函数由两部分组成,前面是为了proximity representation后面是为了node ranking,之后开始讲解这个函数的推理得到的过程。论文之所以考虑到了node ranking,是因为认为加上node ranking之后得到的node embedding对于learning-to-ranking的效果更好,同时”it is beneficial for an embedding model to preserve a network property:global node importance ranking”,也就是说该模型所考虑的node ranking不是其主要的解决目标,而是为了辅助model来embedding node得到更好的node embedding。根据global node ranking preservation的目标函数,可以看出类似于pagerank的衡量标准:邻居节点越重要,本节点就越重要。就是想缩小一个差距。之后的实验learning-to-ranking说明这种考虑到node global ranking值的思路可以提高二分类精确度,不过论文是如何将learning-to-eanking转化为二分类问题的还不晓得。