Hive学习笔记(3)
- Hive学习笔记
- HiveQL:查询
- SELECT…FROM语句
- 算数运算符
- 使用函数
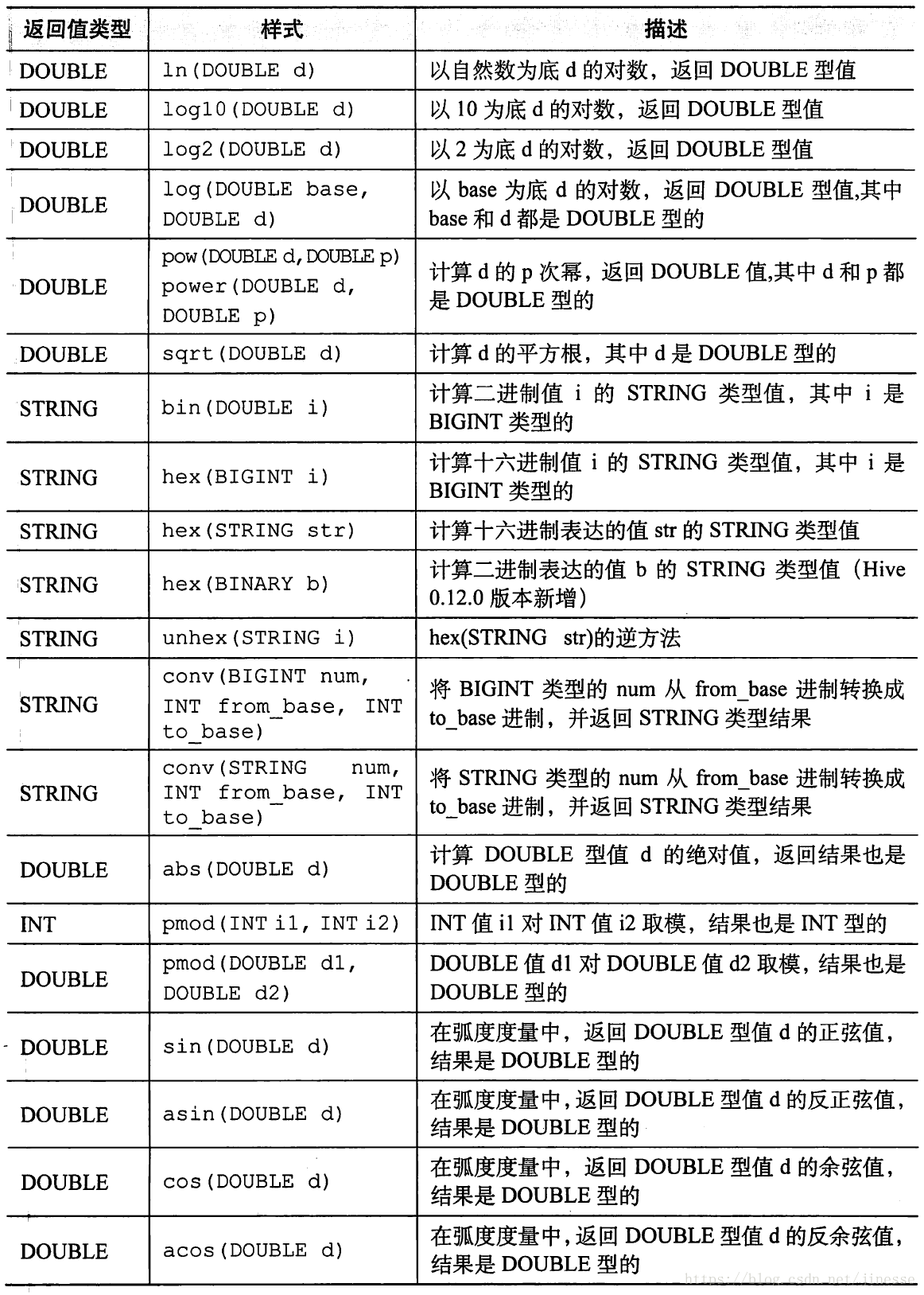
- 数学函数
- 聚合函数
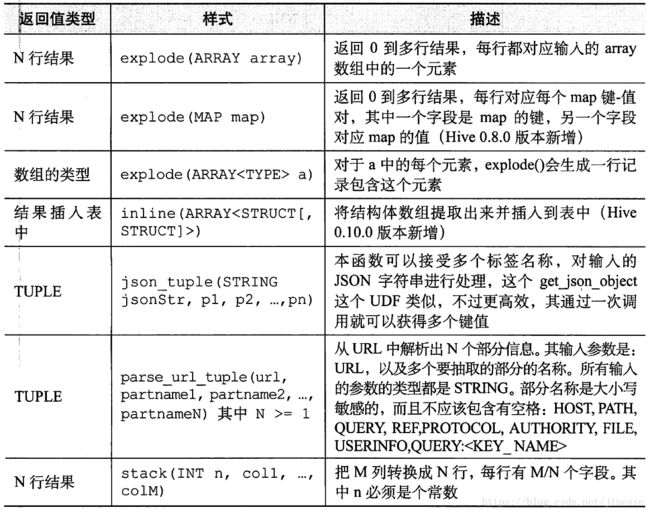
- 表生成函数
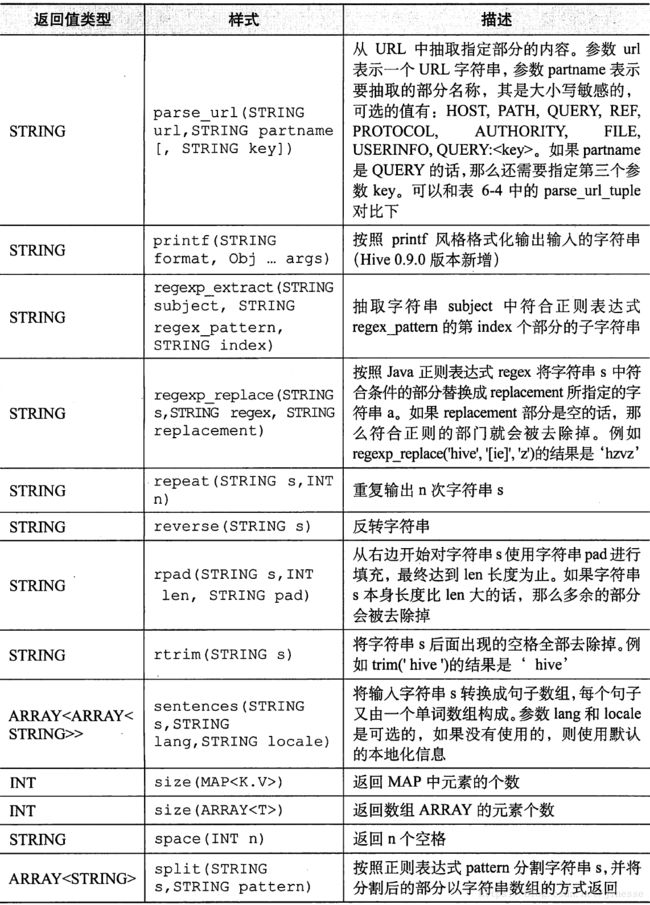
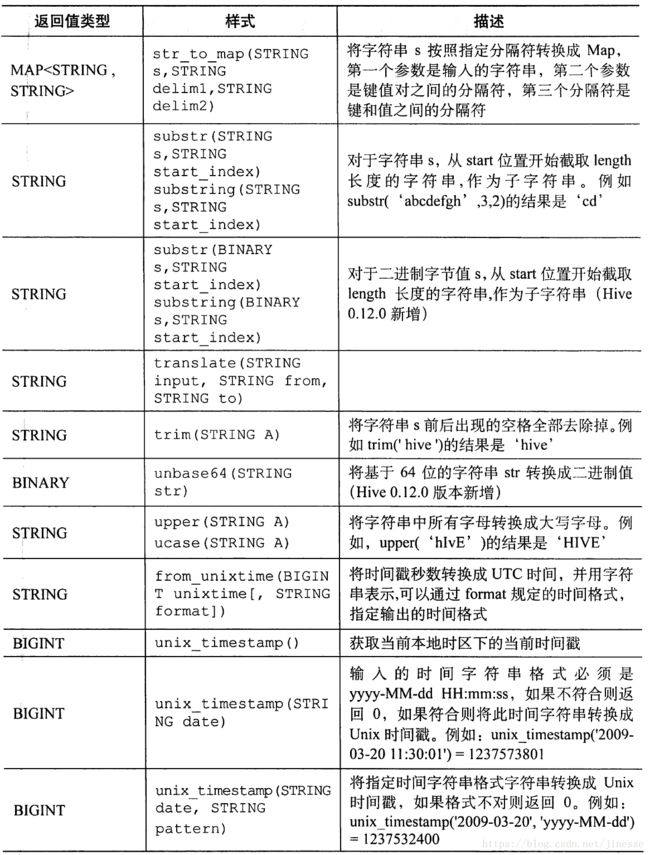
- 其他内置函数
- LIMIT 语句
- 列别名
- 嵌套 SELECT 语句
- CASE…WHEN…THEN 句式
- 什么情况下 Hive 可以避免进行MapReduce
- WHERE 语句
- 谓词操作符
- 关于浮点数的比较
- LIKE和RLIKE
- GROUP BY 语句
- JOIN 语句
- INNER JOIN
- JOIN 优化
- LEFT OUTER JOIN
- OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- LEFT SEMI-JOIN
- 笛卡尔积 JOIN
- map-side JOIN
- ORDER BY 和 SORT BY
- 含有 SORT BY 的 DISTRIBUTE BY
- CLUSTER BY
- 类型转换
- 抽样查询
- UNION ALL
- SELECT…FROM语句
- HiveQL:查询
Hive学习笔记
笔记内容主要来自Hive编程指南
HiveQL:查询
SELECT…FROM语句
SELECT 是 SQL中的射影算子。FROM子句标识了从哪个表、视图或嵌套查询中选择记录。
--分区 employees 表
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY,
deductions MAPFLOAT >,
address STRUCT
)
PARTITIONED BY (country STRING, state STRING); 用户选择的列是集合数据类型时,Hive会使用JSON语法应用于输出
-- 选取 ARRAY 类型
SELECT name, subordinates FROM employees;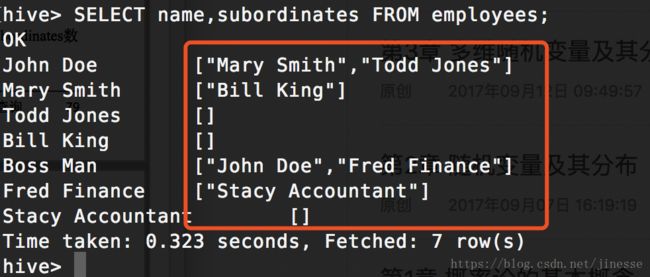
-- 选取 MAP 类型
SELECT name, deductions FROM employees;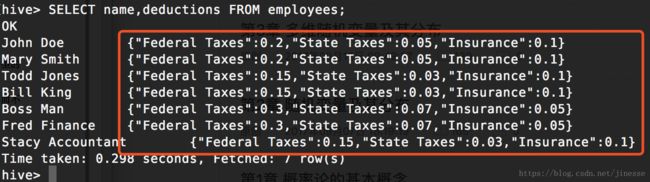
-- 选取 STRUCT 类型
SELECT name, address FROM employees;
-- 选取 ARRAY 类型的第 N 个元素
-- 引用一个不存在的元素将返回NULL
SELECT name, subordinates[0] FROM employees;
-- 选取 MAP 类型
SELECT name, deductions["State Taxes"] FROM employees;
-- 选取 MAP 类型
SELECT name, address.city FROM employees;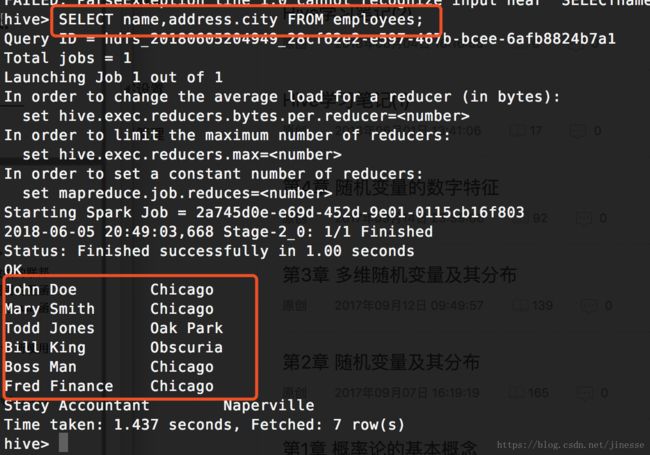
-- 使用正则表达式来指定列
SELECT symbol,'price.*' FROM stocks;
--使用列值进行计算
SELECT upper(name), salary, deductions["Federal Taxes"], round(salary*(1-deductions["Federal Taxes"])) FROM employees;算数运算符

使用函数
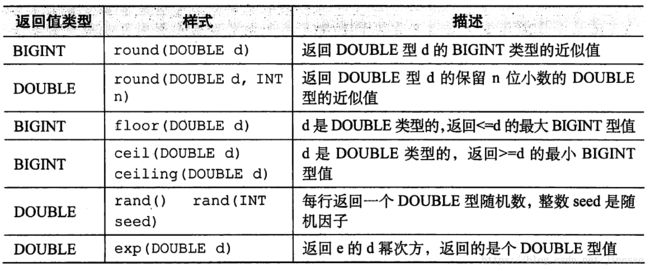
数学函数

聚合函数


-- 设置属性值为true来提高聚合的性能
SET hive.map.aggr=true;
-- HIVE中 不允许在一个查询语句中使用多于一个的函数(DISTINCT...)
SELECT count(DISTINCT ymd),count(DISTINCT volume) FROM stocks;
表生成函数
-- 数组拆分
SELECT explode(subordinates) AS sub FROM employees;
其他内置函数


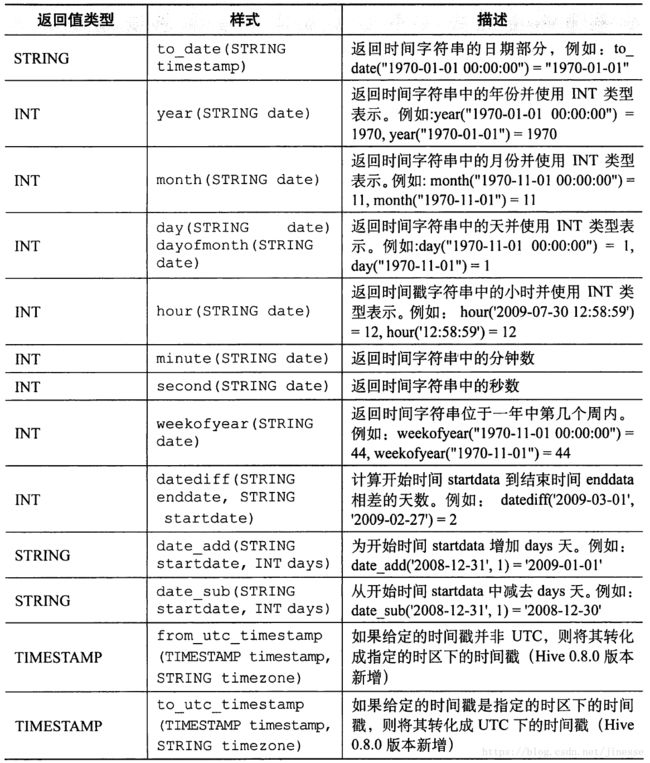
LIMIT 语句
-- LIMIT...
SELECT upper(name), salary, deduction["Federal Taxes"], round(salary * (1 - deduction["Federal Taxes"]) FROM employees LIMIT 2;
列别名
-- 列别名 使用 AS 关键字
SELECT upper(name), salary, deduction["Federal Taxes"] as fed_taxes, round(salary * (1 - deduction["Federal Taxes"]) as salary_minus_fed_taxes
FROM employees
LIMIT 2;
嵌套 SELECT 语句
-- 嵌套查询
FROM (
SELECT upper(name), salary, deduction["Federal Taxes"] as fed_taxes, round(salary * (1 - deduction["Federal Taxes"]) as salary_minus_fed_taxes
FROM employee
) e
SELECT e.name, e.salary minus_fed_taxes
WHERE e.salary_minus_fed_taxes > 70000;
CASE…WHEN…THEN 句式
-- 用于处理单个列的查询结果
SELECT name, salary,
CASE
WHEN salary < 50000.0 THEN 'low'
WHEN salary >=50000.0 AND salary < 70000.0 THEN 'middle'
WHEN salary >=70000.0 AND salary <100000.0 THEN 'high'
ELSE 'very high'
END AS bracket FROM employees;
什么情况下 Hive 可以避免进行MapReduce
-- 本地模式不需要mr过程
SELECT * FROM employees;
-- 对于WHERE 语句中过滤条件只是分区字段这种情况(无论是否使用LIMIT语句限制输出记录条数),无需MapReduce过程
SELECT * FROM employees
WHERE country='US' AND state='CA'
LIMIT 100;
-- 如果属性hive.exec.mode.local.auto 的值为true,Hive还会尝试使用本地模式执行其他操作。
WHERE 语句
SELECT 语句用于选取字段, WHERE 语句用于过滤字段
谓词操作符
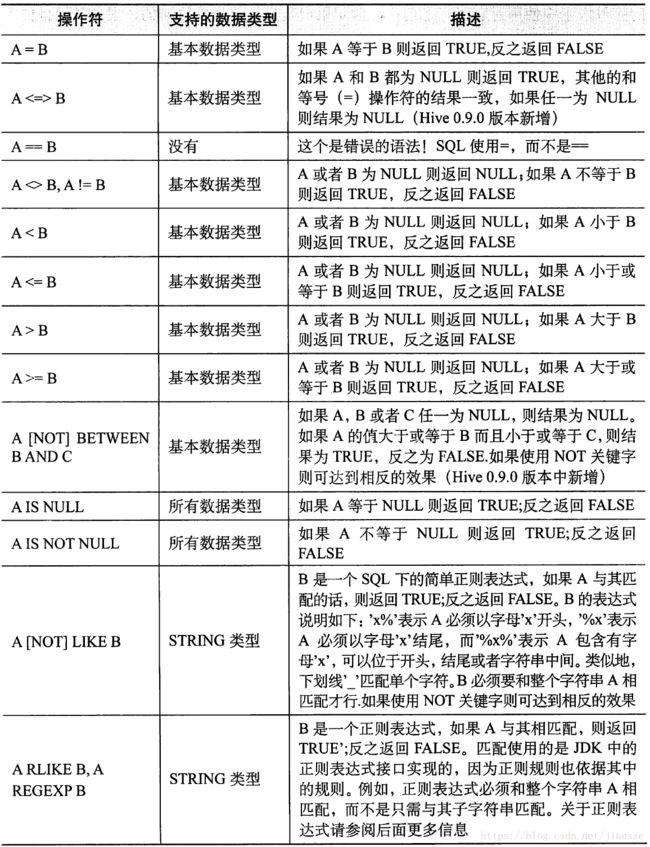
关于浮点数的比较
对浮点数进行比较时,需要保持极端谨慎的态度。要避免任何从窄类型隐式转换到更广泛类型的操作。
LIKE和RLIKE
-- LIKE 标准SQL操作符。
SELECT name, address.street
FROM employees WHERE address.city LIKE 'O%';
-- RLIKE 子句是 Hive 中这个功能的一个扩展,可以通过Java的正则表达式来指定匹配条件
SELECT name, address.street
FROM employees
WHERE address.street RLIKE '.*(Chicago|Ontario).*';
GROUP BY 语句
-- GROUP BY 分组语句
SELECT year(ymd), avg(price_close) FROM stocks
WHERE exchange = 'NASDAQ' AND symbol = 'AAPL'
GROUP BY year(ymd);
-- HAVING 分组后,条件过滤子句。
SELECT year(ymd), avg(price_close) FROM stocks
WHERE exchange = 'NASDAQ' AND symbol = 'AAPL'
GROUP BY year(ymd)
HAVING avg(price_close) >50.0;JOIN 语句
INNER JOIN
-- 内连接(INNER JOIN)中,只有进行连接的两个表中都存在与连接标准相匹配的数据才会被保留下来。
SELECT a.ymd, a.price_close, b.price_close
FROM stocks a JOIN stocks b ON a.ymd = b.ymd
WHERE a.symbol = 'AAPL' AND b.symbol = 'IBM';
-- ON a.ymd <= b.ymd 这种标准SQL支持的非等值连接,在Hive中是非法的,主要原因是通过MapReduce 很难实现这种类型的连接
-- Hive 目前还不支持在 ON 子句中的谓词间使用 OR
-- Hive 总是按照从左到右的顺序执行的JOIN 优化
当对3个或更多个表进行JOIN连接时,如果每个ON子句都使用相同的连接键的话,那么只会产生一个 MapReduce job
-- Hive 同时假定查询中最后一个表是最大的那个表。在对每行记录进行连接操作时,它会尝试将其他表缓存起来,然后扫描最后的那个表进行计算。因此,用户需要保证连续查询中的表的大小从左到右是依次增加的
-- 错误地将最小的表dividends放在了最后面(假定stocks是大表)
SELECT s.ymd, s.symbol, s.price_close, d.dividend
FROM stocks s JOIN dividends d ON s.ymd = d.ymd AND s.symbol = d.symbol
WHERE s.symbol = 'AAPL';
-- 应该交换下表stocks和表dividends的位置
SELECT s.ymd, s.symbol, s.price_close, d.dividend
FROM dividends d JOIN stocks s ON s.ymd = d.ymd AND s.symbol = d.symbol
WHERE s.symbol = 'AAPL';
-- Hive 提供了一个 "标记" 机制来显示地告知查询优化器哪张表是大表
SELECT /*+STREAMTABLE(s) */ s.ymd, s.price_close, d.dividend
FROM stocks s JOIN dividends d ON s.ymd = d.ymd AND s.symbol = d.symbol
WHERE s.symbol = 'AAPL';
LEFT OUTER JOIN
-- 左外连接通过关键字 LEFT OUTER 进行标识
-- JOIN 操作符左边表中符合 WHERE 子句的所有记录将会被返回
-- JOIN 操作符右边表中如果没有符合 ON 后面连接条件的记录时, 那么从右边表指定选择的列的值将会是NULL
SELECT s.ymd, s.symbol, s.price_close, d.dividend
FROM stocks s LEFT OUTER JOIN dividends d ON s.ymd = d.ymd AND s.symbol = d.symbol
WHERE s.symbol = 'AAPL';
OUTER JOIN
OUTER JOIN 语句 先执行 JOIN 语句,然后再将结果通过WHERE 语句进行过滤。
WHERE 语句在连接操作执行后才会执行,因此WHERE 语句应该只用于过滤那些非NULL值的列值。同时,和Hive的文档说明中相反的是,ON语句中的分区过滤条件外连接(OUTER JOIN)中是无效的,不过在内连接(INNTER JOIN) 中是有效的。
RIGHT OUTER JOIN
-- 右外连接(RIGHT OUTER JOIN)会返回右边表所有符合WHERE语句的记录。左表中匹配不上的字段值用NULL代替。
SELECT a.ymd, s.symbol, s.price_close, d.dividend
FROM dividends d OUTER JOIN stocks s ON d.ymd = s.ymd AND d.symbol = s.symbol
WHERE s.symbol = 'AAPL';FULL OUTER JOIN
-- 完全外连接(FULL OUTER JOIN)将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代
SELECT s.ymd, s.symbol, s.price_close, d.dividend
FROM dividends d FULL OUTER JOIN stocks s ON d.ymd = s.ymd AND d.symbol = s.symbol
WHERE s.symbol = 'AAPL';LEFT SEMI-JOIN
-- 左半开连接(LEFT SEMI-JOIN)会返回左边表的记录,前提是其记录对于右边表满足 ON 语句中的判断条件。
SELECT s.ymd, s.symbol, s.price_close
FROM stocks s LEFT SEMI JOIN dividends d ON s.ymd = d.ymd AND s.symbol = d.symbol;
-- SELECT 和 WHERE 语句中不能引用到右边表中的字段
-- Hive 不支持右半开连接笛卡尔积 JOIN
笛卡尔积在一些情况下是很有用的。例如,假设有一个表表示用户偏好,另有一个表表示新闻文章,同时有一个算法会推测出用户可能会喜欢读哪些文章。这个时候就需要使用笛卡尔积生成所有用户和所有网页的对应关系和集合。
-- 笛卡尔积是一种连接,表示左边表的行数乘以右边表的行数等于笛卡尔积结果集的大小
SELECT * FROM stocks JOIN dividends;map-side JOIN
所有表中只有一张表是小表,那么可以在最大的表通过 mapper的时候将小表完全放到内存中。Hive可以在map端执行连接过程(称为 map-side JOIN),这是因为Hive可以和内存中的小表进行逐一匹配,从而省略掉常规连接操作所需要的reduce过程。
-- 设置属性
-- 也可以将属性 设置在 $HOME/.hiverc 文件中
set hive.auto.convert.join=true;
set hive.mapjoin.smalltable.filesize=25000000;
-- Hive对右外连接(RIGHT OUTER JOIN) 和全外连接 (FULL OUTER JOIN)不支持这个优化
-- 如果所有表中的数据是分桶的,那么对于大表,在特定的情况下同样可以使用这个优化。
-- 分桶优化设置参数
set hive.optimize.bucketmapJOIN=true
-- 如果所涉及的分桶表都具有相同的分桶数,而且数据是按照连接键或桶的键进行排序的。那么这时Hive可以执行一个更狂的分类-合并连接(sort-merge JOIN)。
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
ORDER BY 和 SORT BY
Hive找那个 ORDER BY 语句会对查询结果集执行一个全局排序。
SORT BY 只会咋每个reducer中对数据进行排序,也就是执行一个局部排序过程。
-- ORDER BY
SELECT s.ymd, s.symbol,s.price_close
FROM stocks s
ORDER BY s.ymd ASC, s.symbol DESC;
-- SORT BY
SELECT s.ymd, s.symbol,s.price_close
FROM stocks s
SORT BY s.ymd ASC, s.symbol DESC;含有 SORT BY 的 DISTRIBUTE BY
-- DISTRIBUTE BY 控制 map的输出在reducer中是如何划分,相同的Key 会分发到同一个 reducer 当中
-- DISTRIBUTE BY 语句要写在 SORT BY 语句之前
SELECT s.ymd, s.symbol, s.price_close
FROM stocks s
DISTRIBUTE BY s.symbol
SORT BY s.symbol ASC, s.ymd ASC;
CLUSTER BY
-- CLUSTER BY 等价于 DISTRIBUTE BY...SORT BY... ASC
SELECT s.ymd, s.symbol, s.price_close
FROM stocks s
CLUSTER BY s.symbol;
-- 使用 DISTRIBUTE BY...SORT BY 语句或其简化版的CLUSTER BY 语句会剥夺 SORT BY的并行性,然后这样可以实现输出文件的数据是全局排序类型转换
--cast()函数,用户可以使用这个函数对指定的值进行显式的类型转换
SELECT name, salary FROM employees
WHERE cast(salary AS FLOAT) <100000.0;
-- 将浮点数转换成整数的推荐方式是 使用表中列举的 round() 或者 floor()函数,而不是使用类型转换操作符 cast
-- BINARY类型只支持 BINARY类型转换为STRING类型
-- 用户同样可以将STRING 类型转换为 BINARY类型
SELECT (2.0*cast(cast(b as string) as double)) from src;
抽样查询
--使用rand()函数进行抽样
SELECT * FROM numbers TABLESAMPLE(BUCKET 3 OUT OF 10 ON rand()) s;
-- 有可能是 2 4 有可能是 7 10 有可能没有值
-- 按照指定的列而非 rand()函数进行分桶,那么同一语句多次执行的返回值是相同的
SELECT * FROM numbers TABLESAMPLE(BUCKET 3 OUT OF 10 ON number) s;
-- result 2
SELECT * FROM numbers TABLESAMPLE(BUCKET 5 OUT OF 10 ON number) s;
-- result 4
-- 分桶语句转给你的分母表示的是数据将会散列的桶的个数,而分子表示将会选择的桶的个数。
-- 数据块抽样
-- Hive提供按照百分比进行抽样的方式,这种是基于行数的,按照输入路径下的数据块百分比进行的抽样
SELECT * FROM numbersflat TABLESAMPLE(0.1 PERCENT) s;
-- 这种抽样方式不一定适用于所有的文件格式。另外,这种抽样的最小抽样单元是一个 HDFS数据块。因此,如果表的数据大小小于普通的块大小128MB的话,那么将放回所有行
UNION ALL
--UNION ALL 可以将2个或多个表进行合并
SELECT log.ymd, log.level, log.message
FROM(
SELECT 11.ymd, 11.level, 11.message, 'Log1' AS source
FROM log1 11
UNION ALL
SELECT 12.ymd, 12.level, 12.message, 'Log2' AS source
FROM log1 12
) log
SORT BY log.ymd ASC;