TensorFlow之循环神经网络&自然语言处理 学习总结
作者:jliang
https://blog.csdn.net/jliang3
junliang 20190303
说明:以下所有代码使用版本TensorFlow1.4.0或1.12.0版本
import tensorflow as tf
print(tf.__version__)1.12.08. 循环神经网络
TensorFlow中实现LSTM结构的循环神经网络的前向传播过程
- BasicLSTMCell类提供了zero_state函数来生成全零状态。
- state是一个包含两个张量的LSTMStateTuple类,其中state.c和state.h分别对应c状态和h状态。
- 和其他神经网络类似,在优化循环神经网络时,每次也会使用一个batch的训练样本。
# LSTM中使用的变量也会在函数中自动被声明
lstm = tf.nn.rnn_cell.BasicLSTMCell(lstm_hidden_size)
# 将LSTM中的状态初始化为全0数组。BasicLSTMCell类提供了zero_state函数来生成全零状态。
state = lstm.zero_state(batch_size, tf.float32)
# 定义损失函数
loss = 0.0
# 虽然在测试时循环神经网络可以处理任意长度的序列,但是在训练中为了将循环网络展开成前馈神经网络,
# 我们需要知道训练数据的序列长度。
# 以下使用num_steps来表示这个长度。
# 第9章中将介绍使用dynamic_rnn动态处理变长序列的方法。
for i in range(num_steps):
# 在第一个时刻声明LSTM结构中使用的变量,在之后的时刻都需要复用之前定义好的变量。
if i > 0: tf.get_variable_scope().reuse_variables()
# 每一步处理时间序列中的一个时刻,将当前输入current_input
# 和前一个时刻state(h和c)传入定义的LSTM结构
# 可以得到当前的LSTM的输出lstm_output(h)和更新后状态state(h和c)
# lstm_output用于输出给其他层,state用于输出给下一时刻,它们在dropout等方面可以有不同的处理方式。
lstm_output, state = lstm(current_input, state)
# 把当前时刻LSTM结构输出传入一个全连接层得到最后的输出。
final_output = fully_connected(lstm_output)
# 计算当前时刻的输出损失
loss += calc_loss(final_output, expected_output)8.3 循环神经网络的变种
在经典的循环神经网络中,状态的传输是从前往后单向的。然而,有些问题中当前时刻的输出不仅和之前的状态有关系,也和之后的状态有关系,这是就需要使用双向循环神经网络来解决这类问题。
如:预测一个语句中缺失的单词不仅需要根据前文来判断,也需要根据后文来判断。
- 双向循环神经网络时由两个独立的循环神经网络叠加在一起组成,输出由两个循环神经网络的输出拼接而成。
- 每一层网络中的循环体可以自由选用任意结构,如RNN、LSTM。
深层循环神经网络
为了增强模型的表达能力,可以在网络中设置多个循环层,将每层循环网络的输出传给下一层进行处理。
- TensorFlow提供了MultiRNNCell类来实现深层循环神经网络的前向传播过程
- 只需要在BasicLSTMCell的基础上再封装一层MultiRNNCell就可以非常容易地实现深层循环神经网络
# 定义一个基本的LSTM结构作为循环体的基础结构
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell
# 通过MultiRNNCell类实现深层循环神经网络中每一个时刻的前向传播过程。
# number_of_layers表示有多少层
# 注意:从TensorFlow1.1版本起,不能使用[lstm_cell(lstm_size)] * N的形式来初始化MultiRNNCell,
# 否则TensorFlow会在每一层之间共享参数。
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(lstm_size) for _ in range(number_of_layers)]
)
# 和经典的循环神经网络一样,可以通过zero_state来获取初始状态
state = stacked_lstm.zero_state(batch_size, tf.float32)
# 计算每一时刻的前向传播结果
for i in range(len(num_steps)):
if i > 0: tf.get_variable_scope().reuse_variables()
stacked_lstm_output, state = stacked_lstm(current_input, state)
final_output = fully_connected(stacked_lstm_output)
loss += calc_loss(final_output, expected_output)
循环神经网络的dropout
- 通过dropout,可以让卷积神经网络更加健壮,类似,在循环神经网络中使用dropout也有同样的功能。
- 循环神经网络一般只在不同层循环体结构中使用dropout,而不在同一层的循环体结构之间使用(不同时刻之间不使用)
- TensorFlow中使用tf.nn.rnn_cell.DropoutWrapper类可以很容易实现dropout功能
# 定义LSTM结构
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell
# 使用DropoutWrapper类实现dropout功能。该类通过两个参数来控制dropout的概率,
# 一个参数为Input_keep_prob,可以控制输入的dropout概率;另一个为output_keep_prob,它可以用来控制输出的dropout概率。
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.DropoutWrapper(lstm_cell(lstm_size)) for _ in range(number_of_layers)]
)
...8.5 循环神经网络样例应用
利用循环神经网络实现函数sinx取值的预测
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# 1. 定义RNN的参数。
HIDDEN_SIZE = 30 # LSTM中隐藏节点的个数。
NUM_LAYERS = 2 # LSTM的层数。
TIMESTEPS = 10 # 循环神经网络的训练序列长度。
TRAINING_STEPS = 10000 # 训练轮数。
BATCH_SIZE = 32 # batch大小。
TRAINING_EXAMPLES = 10000 # 训练数据个数。
TESTING_EXAMPLES = 1000 # 测试数据个数。
SAMPLE_GAP = 0.01 # 采样间隔。
# 2. 产生正弦数据。
def generate_data(seq):
X = []
y = []
# 序列的第i项和后面的TIMESTEPS-1项合在一起作为输入;第i + TIMESTEPS项作为输
# 出。即用sin函数前面的TIMESTEPS个点的信息,预测第i + TIMESTEPS个点的函数值。
for i in range(len(seq) - TIMESTEPS):
X.append([seq[i: i + TIMESTEPS]])
y.append([seq[i + TIMESTEPS]])
return np.array(X, dtype=np.float32), np.array(y, dtype=np.float32)
# 用正弦函数生成训练和测试数据集合。
test_start = (TRAINING_EXAMPLES + TIMESTEPS) * SAMPLE_GAP
test_end = test_start + (TESTING_EXAMPLES + TIMESTEPS) * SAMPLE_GAP
train_X, train_y = generate_data(np.sin(np.linspace(
0, test_start, TRAINING_EXAMPLES + TIMESTEPS, dtype=np.float32)))
test_X, test_y = generate_data(np.sin(np.linspace(
test_start, test_end, TESTING_EXAMPLES + TIMESTEPS, dtype=np.float32)))
# 3. 定义网络结构和优化步骤。
def lstm_model(X, y, is_training):
# 使用多层的LSTM结构。
cell = tf.nn.rnn_cell.MultiRNNCell([
tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE)
for _ in range(NUM_LAYERS)])
# 使用TensorFlow接口将多层的LSTM结构连接成RNN网络并计算其前向传播结果。
outputs, _ = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
output = outputs[:, -1, :]
# 对LSTM网络的输出再做加一层全链接层并计算损失。注意这里默认的损失为平均
# 平方差损失函数。
predictions = tf.contrib.layers.fully_connected(
output, 1, activation_fn=None)
# 只在训练时计算损失函数和优化步骤。测试时直接返回预测结果。
if not is_training:
return predictions, None, None
# 计算损失函数。
loss = tf.losses.mean_squared_error(labels=y, predictions=predictions)
# 创建模型优化器并得到优化步骤。
train_op = tf.contrib.layers.optimize_loss(
loss, tf.train.get_global_step(),
optimizer="Adagrad", learning_rate=0.1)
return predictions, loss, train_op
# 4. 定义测试方法。
def run_eval(sess, test_X, test_y):
# 将测试数据以数据集的方式提供给计算图。
ds = tf.data.Dataset.from_tensor_slices((test_X, test_y))
ds = ds.batch(1)
X, y = ds.make_one_shot_iterator().get_next()
# 调用模型得到计算结果。这里不需要输入真实的y值。
with tf.variable_scope("model", reuse=True):
prediction, _, _ = lstm_model(X, [0.0], False)
# 将预测结果存入一个数组。
predictions = []
labels = []
for i in range(TESTING_EXAMPLES):
p, l = sess.run([prediction, y])
predictions.append(p)
labels.append(l)
# 计算rmse作为评价指标。
predictions = np.array(predictions).squeeze()
labels = np.array(labels).squeeze()
rmse = np.sqrt(((predictions - labels) ** 2).mean(axis=0))
print("Root Mean Square Error is: %f" % rmse)
#对预测的sin函数曲线进行绘图。
plt.figure()
plt.plot(predictions, label='predictions')
plt.plot(labels, label='real_sin')
plt.legend()
plt.show()
# 5. 执行训练和测试。
# 将训练数据以数据集的方式提供给计算图。
ds = tf.data.Dataset.from_tensor_slices((train_X, train_y))
ds = ds.repeat().shuffle(1000).batch(BATCH_SIZE)
X, y = ds.make_one_shot_iterator().get_next()
# 定义模型,得到预测结果、损失函数,和训练操作。
with tf.variable_scope("model"):
_, loss, train_op = lstm_model(X, y, True)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 测试在训练之前的模型效果。
print("Evaluate model before training.")
run_eval(sess, test_X, test_y)
# 训练模型。
for i in range(TRAINING_STEPS):
_, l = sess.run([train_op, loss])
if i % 1000 == 0:
print("train step: " + str(i) + ", loss: " + str(l))
# 使用训练好的模型对测试数据进行预测。
print("Evaluate model after training.")
run_eval(sess, test_X, test_y)WARNING:tensorflow:From :39: BasicLSTMCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is deprecated, please use tf.nn.rnn_cell.LSTMCell, which supports all the feature this cell currently has. Please replace the existing code with tf.nn.rnn_cell.LSTMCell(name='basic_lstm_cell').
Evaluate model before training.
Root Mean Square Error is: 0.681598 
train step: 0, loss: 0.4930264
train step: 1000, loss: 0.0015030965
...
train step: 9000, loss: 3.4491877e-06
Evaluate model after training.
Root Mean Square Error is: 0.001859
9.自然语言处理
利用循环神经网络来搭建自然语言处理方面的一些经典应用,如语言模型、机器翻译等。
9.1语言模型的背景知识
语言模型:假设一门语言中所有可能的句子服从某一个概率分布,每个句子出现的概率加起来为1,那么语言模型的任务就是预测每个句子在语言中出现的概率。
- 对于语言中常见的句子,一个好的语言模型应得出相对较高的概率;而对于不合语法的句子,计算出的概率则应接近零。
- 语言模型仅仅对句子出现的概率进行建模,并不尝试去理解句子的内容含义。
- 神经网络机器翻译的Seq2Seq模型可以看作是一个条件语言模型(Conditional Language Model),它相当于在给定输入的情况下对目标语言的所有句子估算概率,并选座其中概率最大的句子作为输出。
- 常见的方法有:n-gram模型、决策树、最大熵模型、条件随机场、神经网络语言模型等。
语言模型的评价方法:语言模型效果好坏的常用评价指标是复杂度(perplexity)。在测试集上perplexity越低,效果越好。
- perplexity值刻画的是语言模型预测一个语言样本的能力。比如已经知道(w1,w2,...wm)这句话会出现在语料库中,那么通过语言模型计算得到这句子的概率越高,说明语言模型对这个语料库拟合得越好。
- perplexity实际是计算每一个单词得到的概率倒数的几何平均,因此perplexity可以理解为平均分支系数,即模型预测下一个词时的平均可选择数量。
- 目前在PTB(Penn Tree Bank)数据集上最好的语言模型perplexity为47.7,即在平均情况下,该模型预测下一个词时,有47.7个词等可能地作为下一个词的合理选择。
- 在神经网络模型中,p(wi|w1,w2,...wi-1)分布通常是由一个softmax层产生的,这时TensorFlow中提供了两个方便计算交叉熵的函数
tf.nn.softmax_cross_entropy_with_logitstf.nn.sparse_softmax_cross_entropy_with_logits
tf.nn.softmax_cross_entropy_with_logits与tf.nn.sparse_softmax_cross_entropy_with_logits的区别
- 由于
softmax_cross_entropy_with_logits允许提供一个概率分布,因此在使用时有更大的自由度。 - 举个例子:一种叫label smoothing的技巧是将正确数据的概率设为一个比1.0略小的值,将错误数据的概率设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果。
# 假设词汇表的大小为3(即整个语料库只有3个单词),语料包含两个单词“2 0”
word_labels = tf.constant([2, 0])
# 假设模型对两个单词预测时,产生的logit分别是[2.0, -1.0, 3.0]和[1.0, 0.0, -0.5]
# 注意这里的logit不是概率,因此它们不是0.0~1.0之间的数字。
# 如果需要计算概率,则需要调用prop=tf.nn.softmax(logits)。但这里计算交叉熵的函数直接输入logits即可。
predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]])
# 使用tf.nn.sparse_softmax_cross_entropy_with_logits计算交叉熵
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=word_labels, logits=predict_logits)
with tf.Session() as sess:
print(sess.run(loss))
# softmax_cross_entropy_with_logits与上面类似,但是需要将预测目标以概率分布的形式给出。
word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]])
loss = tf.nn.softmax_cross_entropy_with_logits(
labels=word_prob_distribution, logits=predict_logits
)
print(sess.run(loss))
# 由于softmax_cross_entropy_with_logits允许提供一个概率分布,因此在使用时有更大的自由度。
# 举个例子:一种叫label smoothing的技巧是将正确数据的概率设为一个比1.0略小的值,
# 将错误数据的概率设为比0.0略大的值,
# 这样可以避免模型与数据过拟合,在某些时候可以提高训练效果
word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]])
loss = tf.nn.softmax_cross_entropy_with_logits(
labels=word_prob_smooth, logits=predict_logits
)
print(sess.run(loss))[0.32656264 0.4643688 ]
[0.32656264 0.4643688 ]
[0.37656265 0.48936883]9.2 神经语言模型
- 每个时刻的输入为句子中的单词wi,而每个时刻的输出为一个概率分布,表示句子中下一个位置为不同单词的概率p(wi+1|w1,w2,...wi)
- 每个单词输入时先会被转换成Enbedding向量(实数向量)

9.2.1 PTB数据集的预处理
- PTB(Penn Treebank Dataset)文本数据集是目前语言模型学习中使用广泛的数据集。
- 下载源自Tomas Mikolov网站的PTB数据:http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
- 此处只关系data文件夹下的三个文件:ptb.test.txt, ptb.train.txt, ptb.valid.txt。
- 这三个文件已经预处理,相邻单词之间用空格隔开。
- 数据集中包含了9998个不同的单词词汇,加上稀有词语的特殊符号和语句结束标记符,一共10000个词汇。
(1) 为了将稳步转化为模型可以读入的单词序列,需要将这10000个单词分别映射到0~9999之间的整数编号
import codecs
import collections
from operator import itemgetter
RAW_DATA = 'simple-examples/data/ptb.train.txt' # 训练集数据文件
VOCAB_OUTPUT = 'ptb.vocab' # 输出的词汇表文件
counter = collections.Counter()
with codecs.open(RAW_DATA, 'r', 'utf-8') as f:
for line in f:
for word in line.strip().split():
counter[word] +=1
# 按词频顺序对单词进行排序
sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True)
sorted_words = [x[0] for x in sorted_word_to_cnt]
# 把句子结束符添加到词汇表中
sorted_words = [''] + sorted_words
# 一般情况下,还需要把词汇表中删除低频词汇,在PTB数据中,因为输入数据已经将低频词汇替换成'',
# 因此不需要这一步骤。
with codecs.open(VOCAB_OUTPUT, 'w', 'utf-8') as file_output:
for word in sorted_words:
file_output.write(word + '\n')
(2)在确定词汇表之后,再将训练文件、测试文件等都根据词汇表文件转化为单词编号
import codecs
import sys
VOCAB = 'data/ptb.vocab' # 输出的词汇表文件
TRAIN_RAW_DATA = 'simple-examples/data/ptb.train.txt' # 训练集数据文件
TRAIN_OUTPUT_DATA = 'data/ptb.train'
VALID_RAW_DATA = 'simple-examples/data/ptb.valid.txt' # 验证集数据文件
VALID_OUTPUT_DATA = 'data/ptb.valid'
TEST_RAW_DATA = 'simple-examples/data/ptb.test.txt' # 测试集数据文件
TEST_OUTPUT_DATA = 'data/ptb.test'
# 读取词汇表,并建立词汇到单词编号的映射
with codecs.open(VOCAB, 'r', 'utf-8') as f_vocab:
vocab = [w.strip() for w in f_vocab.readlines()]
word_to_id = {k:v for (k, v) in zip(vocab, range(len(vocab)))}
# 如果出现被删除的低频词,则替换为''
def get_id(word):
return word_to_id[word] if word in word_to_id else word_to_id['']
def transfter_data(input_file_path, output_file_path):
fin = codecs.open(input_file_path, 'r', 'utf-8')
fout = codecs.open(output_file_path, 'w', 'utf-8')
for line in fin:
# 每个句子末尾增加句子结束符''
words = line.strip().split() + ['']
out_line = ' '.join([str(get_id(w)) for w in words]) + '\n'
fout.write(out_line)
fin.close()
fout.close()
transfter_data(TRAIN_RAW_DATA, TRAIN_OUTPUT_DATA)
transfter_data(VALID_RAW_DATA, VALID_OUTPUT_DATA)
transfter_data(TEST_RAW_DATA, TEST_OUTPUT_DATA) 在实际工程中,通常使用TFRecords格式来提高读写效率。虽然预处理原则上可以放在TensorFlow的Dataset框架中与读取文本同时进行,但在工程实践上,保存处理好的数据有几个重要的优点:
- 在调试模型的过程中,可以保证不同模型采取的预处理步骤相同
- 减少文件体积,节省磁盘读取实践
- 方便对预处理步骤本身进行debug
9.2.2 PTB数据的batching方法
文本数据的每个句子长度不同,又无法像图像一样调整到固定维度,因此在对文本数据进行batching时需要采取一些特殊的操作。
- 常见的办法
- 办法一:使用填充(padding)将同一个batch内的句子长度补齐。
- 办法二:语言模型为了利用上下文信息,必须将前面句子的信息传递到后面的句子,为了实现这个目标,在PTB上下文有关联的数据集中,通常采用另一种batching方法。
- 若将整个文档放入计算图,这会导致计算图过大,另外序列过长可能造成训练中梯度爆炸的问题。
- 解决方法:将长序列切割为固定长度的子序列。
- 循环神经网络在处理完一个子序列后,它最终的隐藏状态将复制到下一个序列中作为初始值,这样在前向计算时,效果等同于一次性顺序地读取了整个文档
- 在反向传播时,梯度则只在每个子序列内部传播
import numpy as np
import tensorflow as tf
TRAIN_DATA = 'data/pb.train' # 使用单词编号表示的训练数据
TRAIN_BATCH_SIZE = 20
TRAIN_NUM_STEP = 35
# 从文件中读取数据,并返回包含单词编号的数组
def read_data(file_path):
with open(file_path, 'r') as fin:
id_string = ' '.join([line.strip() for line in fin.readlines()])
id_list = [(int)(w) for w in id_string.split()]
return id_list
def make_batches(id_list, batch_size, num_step):
# 计算总的batch数量,每个batch包含的单词数量是batch_size*num_step
num_batches = (len(id_list)-1)// (batch_size*num_step)
# 将数据整理成一个维度为[batch_size, num_batches*num_step]的二维数组
data = np.array(id_list[:num_batches*batch_size*num_step])
print('data shape={}, data:{}\n'.format(data.shape, data[:1]))
data = np.reshape(data, [batch_size, num_batches*num_step])
print('data shape={}, data:{}\n'.format(data.shape, data[:1]))
# 沿着第二个维度将数据切分(纵轴方向往下切)成num_batches个batch,存入一个数组。
data_batches = np.split(data, num_batches, axis=1)
print('data_batches len={}, data_batches:{}'.format(len(data_batches), data_batches[:1]))
# 重复上述操作,但是每个位置向右移动一位,这里得到的是RNN每一步输出所需要的预测的下一个单词
label = np.array(id_list[1:num_batches*batch_size*num_step + 1])
label = np.reshape(label, [batch_size, num_batches*num_step])
label_batches = np.split(label, num_batches, axis=1)
#返回一个长度为num_batches的数组,其中每一项包括一个data矩阵和一个label矩阵。
return list(zip(data_batches, label_batches))
train_batches = make_batches(read_data(TRAIN_DATA), TRAIN_BATCH_SIZE, TRAIN_NUM_STEP)
data shape=(928900,), data:[9970]
data shape=(20, 46445), data:[[9970 9971 9972 ... 138 767 14]]
data_batches len=1327, data_batches:[array([[9970, 9971, 9972, 9973, 9974, 9975, 9976, 9977, 9978, 9979, 9980,
9981, 9982, 9983, 9984, 9985, 9986, 9987, 9988, 9989, 9990, 9991,
9992, 9993, 0, 8569, 2, 3, 72, 393, 33, 2116, 1,
146, 19],
[ 13, 1513, 18, 1446, 1, 844, 236, 1, 1384, 5, 1273,
7, 1635, 1089, 3842, 17, 380, 1352, 4, 207, 0, 1,
2600, 4, 1, 261, 13, 5, 335, 1, 2, 16, 767,
1499, 10],
...
[1298, 746, 20, 1, 12, 3, 21, 7, 1, 334, 109,
0, 8, 28, 1300, 10, 45, 1312, 1468, 13, 169, 7,
1, 130, 1559, 4, 2317, 0, 1, 37, 369, 27, 501,
253, 720]])]batching例子
- 假如输入句子是[ 1 2 3 4 5 6 7 8 9 10 11 12],并设置batchsize为4,numstep为2。
- 先把输入句子按batch_size分为多个batch
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]] - 再从纵轴方向由上往下把上面划分batch后的二维数据在切分为num_step份
array([[ 1, 2], [ 5, 6],
[ 9, 10]])
array([[ 3, 4],
[ 7, 8],
[11, 12]])
切分操作示意图:

a = [
1, 2, 3, 4,
5, 6, 7, 8,
9, 10, 11, 12,
]
a = np.array(a)
print('a shape={}, a:{}\n'.format(a.shape, a))
a.shape = (3, 4)
print('a shape={}, a:\n{}\n'.format(a.shape, a))
print(np.split(a, 2, axis=1))
a shape=(12,), a:[ 1 2 3 4 5 6 7 8 9 10 11 12]
a shape=(3, 4), a:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[array([[ 1, 2],
[ 5, 6],
[ 9, 10]]), array([[ 3, 4],
[ 7, 8],
[11, 12]])]9.2.3 基于循环神经网络的神经语言模型
与循环神经网络相比,NLP应用主要多了两层:词向量层(embedding)和softmax(层)。
词向量
- 在输入层,每一个单词用一个实数向量表示,这个向量被称为”词向量“/"词嵌入",词向量作用:
- 降低输入的维度
- 增加语义信息
- 假设词向量的维度时EMB_SIZE,词汇表的大小为
VOCAB_SIZE,那么所有单词的词向量可以放入一个大小为VOCAB_SIZE*EMB_SIZE的矩阵内。 - 在读取词向量时,可以调用
tf.nn.embedding_lookup方法
embedding = tf.get_variable('embedding', [VOCAB_SIZE, EMB_SIZE])
# 输出的矩阵比输入数据多一个维度,新增维度的大小是EMB_SIZE。在语言模型中,一般input_data的维度时batch_size*num_steps,而输出的input_embedding维度时batch_size*num_steps*EMB_SIZE.
input_embedding = tf.nn.embedding_lookup(embedding, input_data)Softmax层
- 作用是将循环神经网络的输出转化为一个单词表中每个单词的输出概率,两个步骤:
- 使用一个线性映射将循环神经网络的输出映射为一个维度与词汇表大小相同的向量,这一步的输出叫作logits
- 调用softmax方法将logits转化为加和未1的概率
# 定义线性映射用到的参数。
# HIDDEN_SIZE是循环神经网络的隐藏状态维度,VOCAB_SIZE是词汇表的大小。
weight = tf.get_variable('weight', [HIDDENT_SIZE, VOCAB_SIZE])
bias = tf.get_variable('bias', [VOCAB_SIZE])
# 计算线性映射
# output是RNN的输出,其维度为[batch_size*num_steps, HIDDENT_SIZE]
logits = tf.nn.bias_add(tf.matmul(output, weight), bias)
# prob的维度与logits的维度相同
probs = tf.nn.softmax(logits)模型训练通常不关心概率的具体取值,而更关心最终的log perplexity,因此可以调用tf.nn.sparse_softmax_cross_entropy_with_logits方法直接从logits计算log perplexity作为损失函数。
# 单词编号
# logits的维度时[batch_size*num_steps, HIDDEN_SIZE]
# loss的维度与label相同,代表每个位置上的log perplexity
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.reshape(self.targets, [-1]), logits=logits
)通过共享参数减少参数数量
- softmax层和词向量的参数数量都与词汇表大小
VOCAB_SIZE成正比,softmax和embedding在整个网络的参数数量中占有很大的比例。 - 词向量和softmax层的参数数量是相等的,如果共享词向量层和softmax层的参数,不仅能大幅度减少参数数量,还能提高最终模型效果。
完整的训练程序:一个双层LSTM作为循环神经网络的主体,并共享softmax层和词向量层的参数
# coding: utf-8
import numpy as np
import tensorflow as tf
# 1.设置参数。
TRAIN_DATA = "data/ptb.train" # 训练数据路径。
EVAL_DATA = "data/ptb.valid" # 验证数据路径。
TEST_DATA = "data/ptb.test" # 测试数据路径。
HIDDEN_SIZE = 300 # 隐藏层规模。
NUM_LAYERS = 2 # 深层循环神经网络中LSTM结构的层数。
VOCAB_SIZE = 10000 # 词典规模。
TRAIN_BATCH_SIZE = 20 # 训练数据batch的大小。
TRAIN_NUM_STEP = 35 # 训练数据截断长度。
EVAL_BATCH_SIZE = 1 # 测试数据batch的大小。
EVAL_NUM_STEP = 1 # 测试数据截断长度。
NUM_EPOCH = 5 # 使用训练数据的轮数。
LSTM_KEEP_PROB = 0.9 # LSTM节点不被dropout的概率。
EMBEDDING_KEEP_PROB = 0.9 # 词向量不被dropout的概率。
MAX_GRAD_NORM = 5 # 用于控制梯度膨胀的梯度大小上限。
SHARE_EMB_AND_SOFTMAX = True # 在Softmax层和词向量层之间共享参数。
# 2.定义模型。
# 通过一个PTBModel类来描述模型,这样方便维护循环神经网络中的状态。
class PTBModel(object):
def __init__(self, is_training, batch_size, num_steps):
# 记录使用的batch大小和截断长度。
self.batch_size = batch_size
self.num_steps = num_steps
# 定义每一步的输入和预期输出。两者的维度都是[batch_size, num_steps]。
self.input_data = tf.placeholder(tf.int32, [batch_size, num_steps])
self.targets = tf.placeholder(tf.int32, [batch_size, num_steps])
# 定义使用LSTM结构为循环体结构且使用dropout的深层循环神经网络。
dropout_keep_prob = LSTM_KEEP_PROB if is_training else 1.0
lstm_cells = [
tf.nn.rnn_cell.DropoutWrapper(
tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE),
output_keep_prob=dropout_keep_prob)
for _ in range(NUM_LAYERS)]
cell = tf.nn.rnn_cell.MultiRNNCell(lstm_cells)
# 初始化最初的状态,即全零的向量。这个量只在每个epoch初始化第一个batch
# 时使用。
self.initial_state = cell.zero_state(batch_size, tf.float32)
# 定义单词的词向量矩阵。
embedding = tf.get_variable("embedding", [VOCAB_SIZE, HIDDEN_SIZE])
# 将输入单词转化为词向量。
inputs = tf.nn.embedding_lookup(embedding, self.input_data)
# 只在训练时使用dropout。
if is_training:
inputs = tf.nn.dropout(inputs, EMBEDDING_KEEP_PROB)
# 定义输出列表。在这里先将不同时刻LSTM结构的输出收集起来,再一起提供给
# softmax层。
outputs = []
state = self.initial_state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
cell_output, state = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
# 把输出队列展开成[batch, hidden_size*num_steps]的形状,然后再
# reshape成[batch*numsteps, hidden_size]的形状。
output = tf.reshape(tf.concat(outputs, 1), [-1, HIDDEN_SIZE])
# Softmax层:将RNN在每个位置上的输出转化为各个单词的logits。
if SHARE_EMB_AND_SOFTMAX:
weight = tf.transpose(embedding)
else:
weight = tf.get_variable("weight", [HIDDEN_SIZE, VOCAB_SIZE])
bias = tf.get_variable("bias", [VOCAB_SIZE])
logits = tf.matmul(output, weight) + bias
# 定义交叉熵损失函数和平均损失。
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.reshape(self.targets, [-1]),
logits=logits)
self.cost = tf.reduce_sum(loss) / batch_size
self.final_state = state
# 只在训练模型时定义反向传播操作。
if not is_training: return
trainable_variables = tf.trainable_variables()
# 控制梯度大小,定义优化方法和训练步骤。
grads, _ = tf.clip_by_global_norm(
tf.gradients(self.cost, trainable_variables), MAX_GRAD_NORM)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0)
self.train_op = optimizer.apply_gradients(
zip(grads, trainable_variables))
# 3.定义数据和训练过程。
# 使用给定的模型model在数据data上运行train_op并返回在全部数据上的perplexity值。
def run_epoch(session, model, batches, train_op, output_log, step):
# 计算平均perplexity的辅助变量。
total_costs = 0.0
iters = 0
state = session.run(model.initial_state)
# 训练一个epoch。
for x, y in batches:
# 在当前batch上运行train_op并计算损失值。交叉熵损失函数计算的就是下一个单
# 词为给定单词的概率。
cost, state, _ = session.run(
[model.cost, model.final_state, train_op],
{model.input_data: x, model.targets: y,
model.initial_state: state})
total_costs += cost
iters += model.num_steps
# 只有在训练时输出日志。
if output_log and step % 100 == 0:
print("After %d steps, perplexity is %.3f" % (
step, np.exp(total_costs / iters)))
step += 1
# 返回给定模型在给定数据上的perplexity值。
return step, np.exp(total_costs / iters)
# 从文件中读取数据,并返回包含单词编号的数组。
def read_data(file_path):
with open(file_path, "r") as fin:
# 将整个文档读进一个长字符串。
id_string = ' '.join([line.strip() for line in fin.readlines()])
id_list = [int(w) for w in id_string.split()] # 将读取的单词编号转为整数
return id_list
def make_batches(id_list, batch_size, num_step):
# 计算总的batch数量。每个batch包含的单词数量是batch_size * num_step。
num_batches = (len(id_list) - 1) // (batch_size * num_step)
# 如9-4图所示,将数据整理成一个维度为[batch_size, num_batches * num_step]
# 的二维数组。
data = np.array(id_list[: num_batches * batch_size * num_step])
data = np.reshape(data, [batch_size, num_batches * num_step])
# 沿着第二个维度将数据切分成num_batches个batch,存入一个数组。
data_batches = np.split(data, num_batches, axis=1)
# 重复上述操作,但是每个位置向右移动一位。这里得到的是RNN每一步输出所需要预测的
# 下一个单词。
label = np.array(id_list[1 : num_batches * batch_size * num_step + 1])
label = np.reshape(label, [batch_size, num_batches * num_step])
label_batches = np.split(label, num_batches, axis=1)
# 返回一个长度为num_batches的数组,其中每一项包括一个data矩阵和一个label矩阵。
return list(zip(data_batches, label_batches))
# 4.主函数
def main():
# 定义初始化函数。
initializer = tf.random_uniform_initializer(-0.05, 0.05)
# 定义训练用的循环神经网络模型。
with tf.variable_scope("language_model",
reuse=None, initializer=initializer):
train_model = PTBModel(True, TRAIN_BATCH_SIZE, TRAIN_NUM_STEP)
# 定义测试用的循环神经网络模型。它与train_model共用参数,但是没有dropout。
with tf.variable_scope("language_model",
reuse=True, initializer=initializer):
eval_model = PTBModel(False, EVAL_BATCH_SIZE, EVAL_NUM_STEP)
# 训练模型。
with tf.Session() as session:
tf.global_variables_initializer().run()
train_batches = make_batches(
read_data(TRAIN_DATA), TRAIN_BATCH_SIZE, TRAIN_NUM_STEP)
eval_batches = make_batches(
read_data(EVAL_DATA), EVAL_BATCH_SIZE, EVAL_NUM_STEP)
test_batches = make_batches(
read_data(TEST_DATA), EVAL_BATCH_SIZE, EVAL_NUM_STEP)
step = 0
for i in range(NUM_EPOCH):
print("In iteration: %d" % (i + 1))
step, train_pplx = run_epoch(session, train_model, train_batches,
train_model.train_op, True, step)
print("Epoch: %d Train Perplexity: %.3f" % (i + 1, train_pplx))
_, eval_pplx = run_epoch(session, eval_model, eval_batches,
tf.no_op(), False, 0)
print("Epoch: %d Eval Perplexity: %.3f" % (i + 1, eval_pplx))
_, test_pplx = run_epoch(session, eval_model, test_batches,
tf.no_op(), False, 0)
print("Test Perplexity: %.3f" % test_pplx)
# if __name__ == "__main__":
main()
WARNING:tensorflow:From :41: BasicLSTMCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is deprecated, please use tf.nn.rnn_cell.LSTMCell, which supports all the feature this cell currently has. Please replace the existing code with tf.nn.rnn_cell.LSTMCell(name='basic_lstm_cell').
In iteration: 1
After 0 steps, perplexity is 9986.597
After 100 steps, perplexity is 1820.443
...
After 1300 steps, perplexity is 326.178
Epoch: 1 Train Perplexity: 323.125
Epoch: 1 Eval Perplexity: 183.125
In iteration: 2
After 1400 steps, perplexity is 176.553
...
After 6600 steps, perplexity is 71.955
Epoch: 5 Train Perplexity: 72.133
Epoch: 5 Eval Perplexity: 107.790
Test Perplexity: 104.232 9.3 神经网络机器翻译
- Seq2Seq模型的基本思想非常简单,使用一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度的编码中;再使用另一个循环神经网络读取这个编码,将其“解压”为目标语言的一个句子。
- 解码器的结构和语言模型几乎相同:输入为单词的词向量,输出为softmax层产生的单词概率,损失函数为log perplexity。
- 编码阶段并未输出,因此编码器不需要softmax层。
- 共享softmax层和词向量的参数,都可以直接应用到Seq2Seq模型的解码器中。
- 训练过程中,编码器顺序读入每个单词的词向量,然后将最终的隐藏状态复制到解码器作为初始状态。
- 解码器的第一个输入是一个特殊的
- 解码器的第一个输入是一个特殊的
- 语言模型中测试的标准是给定目标句子上的perplexity,而机器翻译的测试方法是让解码器在没有“正确答案”的情况下自主生成一个翻译句子,然后采用人工或自动的方法对翻译句子的质量进行评测。

机器翻译文本数据预处理
-
机器翻译领域最重要的公开数据集是WMT数据集
- 下载地址:http://data.statmt.org/wmt17/translation-task/
- IWLST TED数据集“https://wit3.fbk.eu/mt.php?release=2015-01
- 英文-中文数据训练数据包含21万个句子对,内容是TED演讲的中英字幕。
-
首先需要统计语料中出现的单词,为每个单词分配一个ID,将词汇表存入一个vocab文件,然后将文件转换为用单词编号的形式来表示。
- WMT数据集没有经过预处理,尤其是没有经过切词。
- 最常用的切词工具是moses:https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.pel
- 用法:perl ./moses_tokenizer.perl -no-escape -l en < ./train.raw.en > train.txt.en
- -no-escape 表示不把标点符号替换成HTML编码
- -l en表示输入文件的语言是英文
- 切词后,分别生成英文文本和中文文本词汇文件,并将转化为单词编号。
- 生成词汇文件时,需要注意将
- 限制词汇表大小,将词频过低的词替换为
- 生成词汇文件时,需要注意将
-
在机器翻译的训练样本中,每个句子对通常是作为独立的数据来训练的。
-
由于每个句子的长短不一致,因此在将这些句子放入同一个batch时,需要将较短的句子补齐到与同batch内最长句子相同的长度。tf.data.Dataset的
padded_batch()提供了填充功能 -
循环神经网络在读取数据时会将填充位置的内容与其他内容一样纳入计算,为了不让填充数据影响训练,注意内容:
- 循环神经网络在读取填充时,应当跳过这一位置的计算。
- TensorFlow提供了
tf.nn.dynamic_rnn方法来实现这功能 dynamic_rnn输入数据的内容(维度为[batch_size, time])和输入数据的长度(维度为[time])。- 对于输入batch里的每一条数据,在读取了相应长度的内容后,
dynamic_rnn就跳过后面的输入,直接把前一步的计算结果复制到后面的时刻。相当于忽略padding内容。
- TensorFlow提供了
- 在设计损失函数时需要特别将填充位置的损失的权重设置为0,这样在填充位置产生的预测不会影响梯度的计算。
- 循环神经网络在读取填充时,应当跳过这一位置的计算。

* 上图为两个batch,第一个batch的维度时2*4,第二个batch是2*7 * 'A1A2A3A4'和'B1B200'为一个batch
使用tf.data.Dataset.padded_batch来进行填充和batching,并记录每个句子的序列长度以用作dynamic_rnn的输入
MAX_LEN = 50 # 限定句子的最大单词数量
SOS_ID = 1 # 目标语言词汇表中的的ID
# 使用Dataset从一个文件中读取一个语言的数据,数据的格式为每行一句话,单词已经转化为单词编号
def MakeDataset(file_path):
dataset = tf.data.TextLineDataset(file_path)
# 根据空格将单词编号且分开并放入一维向量。
dataset = dataset.map(lambda string: tf.string_split([string]).values)
print(dataset)
# 将字符串形式的单词编号转化为整数
dataset = dataset.map(lambda string: tf.string_to_number(string, tf.int32))
# 统计每个句子的单词数量,并与句子内容一起放入Dataset中
dataset = dataset.map(lambda x: (x, tf.size(x)))
return dataset
# 从源语言文件src_path和目标语言文件trg_path中分别读取数据,并进行填充和batching操作
def MakeSrcTrgDataset(src_path, trg_path, batch_size):
src_data = MakeDataset(src_path)
trg_data = MakeDataset(trg_path)
# 通过zip操作将两个Dataset合并在一个Dataset,现在每个Dataset中每一项数据ds由4个张量组成
# ds[0][0]是源句子
# ds[0][1]是源句子长度
# ds[1][0]是目标句子
# ds[1][1]是目标句子长度
dataset = tf.data.Dataset.zip((src_data, trg_data))
# 删除内容为空(只包含)的句子和长度过长的句子
def FilterLength(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
src_len_ok = tf.logical_and(tf.greater(src_len, 1), tf.less_equal(src_len, MAX_LEN))
trg_len_ok = tf.logical_and(tf.greater(trg_len, 1), tf.less_equal(trg_len, MAX_LEN))
return tf.logical_and(src_len_ok, trg_len_ok)
dataset = dataset.filter(FilterLength)
# 解码器需要两种格式的目标句子
# 1.解码器的输入(trg_input),形式如同:' X Y Z'
# 2.解码器的目标输出(trg_label),形式如同:'X Y Z '
# 从文件中读到目标句子是'X Y Z ',需要从中生成' X Y Z'形式并加入到Dataset中
def MakeTrgInput(src_tuple, trg_tuple):
((src_input, src_len), (trg_lable, trg_len)) = (src_tuple, trg_tuple)
trg_input = tf.concat([[SOS_ID], trg_lable[:-1]], axis=0)
return ((src_input, src_len), (trg_input, trg_label, trg_len))
dataset = dataset.map(MakeTrgInput)
# 随机打乱训练数据
dataset = dataset.shuffle(10000)
# 规定填充后输出的数据维度
padded_shapes = (
(tf.TensorShape([None]), # 源句子是长度未知的向量
tf.TensorShape([])), # 源句子长度是单个数字
(tf.TensorShape([None]), # 目标句子(解码器输入)是长度未知的向量
tf.TensorShape([None]), # 目标句子(解码器目标输出)是长度未知的向量
tf.TensorShape([]) # 目标句子长度是单个数字
)
)
# 调用padded_batch方法进行batching操作
batched_dataset = dataset.padded_batch(batch_size, padded_shapes)
return batch_dataset
Seq2Seq模型实现
与语言模型相比,主要变化有以下几点:
- 增加一个循环神经网络作为编码器
- 使用Dataset动态读取数据,而不是直接将所有数据读入内容
- 每个batch完全独立,不需要在batch之间传递状态
- 每训练200步便将参数保存到一个checkpoint中
训练代码
因为训练时解码器可以从输入中读取完整的目标训练句子,因此可以用dynamic_rcc简单地展开成前馈网络。
import tensorflow as tf
# 1.参数设置
# 假设输入数据已经用9.2.1小节中的方法转换成了单词编号的格式。
SRC_TRAIN_DATA = "./data/train.en" # 源语言输入文件。
TRG_TRAIN_DATA = "./data/train.zh" # 目标语言输入文件。
CHECKPOINT_PATH = "./data/seq2seq_ckpt" # checkpoint保存路径。
HIDDEN_SIZE = 1024 # LSTM的隐藏层规模。
NUM_LAYERS = 2 # 深层循环神经网络中LSTM结构的层数。
SRC_VOCAB_SIZE = 10000 # 源语言词汇表大小。
TRG_VOCAB_SIZE = 4000 # 目标语言词汇表大小。
BATCH_SIZE = 100 # 训练数据batch的大小。
NUM_EPOCH = 5 # 使用训练数据的轮数。
KEEP_PROB = 0.8 # 节点不被dropout的概率。
MAX_GRAD_NORM = 5 # 用于控制梯度膨胀的梯度大小上限。
SHARE_EMB_AND_SOFTMAX = True # 在Softmax层和词向量层之间共享参数。
MAX_LEN = 50 # 限定句子的最大单词数量。
SOS_ID = 1 # 目标语言词汇表中的ID。
# 2.读取训练数据并创建Dataset
# 使用Dataset从一个文件中读取一个语言的数据。
# 数据的格式为每行一句话,单词已经转化为单词编号。
def MakeDataset(file_path):
print('Read dataset from {}'.format(file_path))
dataset = tf.data.TextLineDataset(file_path)
print(dataset)
# 根据空格将单词编号切分开并放入一个一维向量。
dataset = dataset.map(lambda string: tf.string_split([string]).values)
# 将字符串形式的单词编号转化为整数。
dataset = dataset.map(
lambda string: tf.string_to_number(string, tf.int32))
# 统计每个句子的单词数量,并与句子内容一起放入Dataset中。
dataset = dataset.map(lambda x: (x, tf.size(x)))
return dataset
# 从源语言文件src_path和目标语言文件trg_path中分别读取数据,并进行填充和
# batching操作。
def MakeSrcTrgDataset(src_path, trg_path, batch_size):
# 首先分别读取源语言数据和目标语言数据。
src_data = MakeDataset(src_path)
trg_data = MakeDataset(trg_path)
# 通过zip操作将两个Dataset合并为一个Dataset。现在每个Dataset中每一项数据ds
# 由4个张量组成:
# ds[0][0]是源句子
# ds[0][1]是源句子长度
# ds[1][0]是目标句子
# ds[1][1]是目标句子长度
dataset = tf.data.Dataset.zip((src_data, trg_data))
# 删除内容为空(只包含)的句子和长度过长的句子。
def FilterLength(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
src_len_ok = tf.logical_and(
tf.greater(src_len, 1), tf.less_equal(src_len, MAX_LEN))
trg_len_ok = tf.logical_and(
tf.greater(trg_len, 1), tf.less_equal(trg_len, MAX_LEN))
return tf.logical_and(src_len_ok, trg_len_ok)
dataset = dataset.filter(FilterLength)
# 从图9-5可知,解码器需要两种格式的目标句子:
# 1.解码器的输入(trg_input),形式如同" X Y Z"
# 2.解码器的目标输出(trg_label),形式如同"X Y Z "
# 上面从文件中读到的目标句子是"X Y Z "的形式,我们需要从中生成" X Y Z"
# 形式并加入到Dataset中。
def MakeTrgInput(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
trg_input = tf.concat([[SOS_ID], trg_label[:-1]], axis=0)
return ((src_input, src_len), (trg_input, trg_label, trg_len))
dataset = dataset.map(MakeTrgInput)
# 随机打乱训练数据。
dataset = dataset.shuffle(10000)
# 规定填充后输出的数据维度。
padded_shapes = (
(tf.TensorShape([None]), # 源句子是长度未知的向量
tf.TensorShape([])), # 源句子长度是单个数字
(tf.TensorShape([None]), # 目标句子(解码器输入)是长度未知的向量
tf.TensorShape([None]), # 目标句子(解码器目标输出)是长度未知的向量
tf.TensorShape([]))) # 目标句子长度是单个数字
# 调用padded_batch方法进行batching操作。
batched_dataset = dataset.padded_batch(batch_size, padded_shapes)
return batched_dataset
# 3.定义翻译模型。
# 定义NMTModel类来描述模型。
class NMTModel(object):
# 在模型的初始化函数中定义模型要用到的变量。
def __init__(self):
# 定义编码器和解码器所使用的LSTM结构。
self.enc_cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE)
for _ in range(NUM_LAYERS)])
self.dec_cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE)
for _ in range(NUM_LAYERS)])
# 为源语言和目标语言分别定义词向量。
self.src_embedding = tf.get_variable(
"src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable(
"trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
# 定义softmax层的变量
if SHARE_EMB_AND_SOFTMAX:
self.softmax_weight = tf.transpose(self.trg_embedding)
else:
self.softmax_weight = tf.get_variable(
"weight", [HIDDEN_SIZE, TRG_VOCAB_SIZE])
self.softmax_bias = tf.get_variable(
"softmax_bias", [TRG_VOCAB_SIZE])
# 在forward函数中定义模型的前向计算图。
# src_input, src_size, trg_input, trg_label, trg_size分别是上面
# MakeSrcTrgDataset函数产生的五种张量。
def forward(self, src_input, src_size, trg_input, trg_label, trg_size):
batch_size = tf.shape(src_input)[0]
# 将输入和输出单词编号转为词向量。
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input)
# 在词向量上进行dropout。
src_emb = tf.nn.dropout(src_emb, KEEP_PROB)
trg_emb = tf.nn.dropout(trg_emb, KEEP_PROB)
# 使用dynamic_rnn构造编码器。
# 编码器读取源句子每个位置的词向量,输出最后一步的隐藏状态enc_state。
# 因为编码器是一个双层LSTM,因此enc_state是一个包含两个LSTMStateTuple类
# 张量的tuple,每个LSTMStateTuple对应编码器中的一层。
# enc_outputs是顶层LSTM在每一步的输出,它的维度是[batch_size,
# max_time, HIDDEN_SIZE]。Seq2Seq模型中不需要用到enc_outputs,而
# 后面介绍的attention模型会用到它。
with tf.variable_scope("encoder"):
enc_outputs, enc_state = tf.nn.dynamic_rnn(
self.enc_cell, src_emb, src_size, dtype=tf.float32)
# 使用dyanmic_rnn构造解码器。
# 解码器读取目标句子每个位置的词向量,输出的dec_outputs为每一步
# 顶层LSTM的输出。dec_outputs的维度是 [batch_size, max_time,
# HIDDEN_SIZE]。
# initial_state=enc_state表示用编码器的输出来初始化第一步的隐藏状态。
with tf.variable_scope("decoder"):
dec_outputs, _ = tf.nn.dynamic_rnn(
self.dec_cell, trg_emb, trg_size, initial_state=enc_state)
# 计算解码器每一步的log perplexity。这一步与语言模型代码相同。
output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE])
logits = tf.matmul(output, self.softmax_weight) + self.softmax_bias
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.reshape(trg_label, [-1]), logits=logits)
# 在计算平均损失时,需要将填充位置的权重设置为0,以避免无效位置的预测干扰
# 模型的训练。
label_weights = tf.sequence_mask(
trg_size, maxlen=tf.shape(trg_label)[1], dtype=tf.float32)
label_weights = tf.reshape(label_weights, [-1])
cost = tf.reduce_sum(loss * label_weights)
cost_per_token = cost / tf.reduce_sum(label_weights)
# 定义反向传播操作。反向操作的实现与语言模型代码相同。
trainable_variables = tf.trainable_variables()
# 控制梯度大小,定义优化方法和训练步骤。
grads = tf.gradients(cost / tf.to_float(batch_size),
trainable_variables)
grads, _ = tf.clip_by_global_norm(grads, MAX_GRAD_NORM)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0)
train_op = optimizer.apply_gradients(
zip(grads, trainable_variables))
return cost_per_token, train_op
# 4.训练过程和主函数。
# 使用给定的模型model上训练一个epoch,并返回全局步数。
# 每训练200步便保存一个checkpoint。
def run_epoch(session, cost_op, train_op, saver, step):
# 训练一个epoch。
# 重复训练步骤直至遍历完Dataset中所有数据。
while True:
try:
# 运行train_op并计算损失值。训练数据在main()函数中以Dataset方式提供。
cost, _ = session.run([cost_op, train_op])
if step % 10 == 0:
print("After %d steps, per token cost is %.3f" % (step, cost))
# 每200步保存一个checkpoint。
if step % 200 == 0:
saver.save(session, CHECKPOINT_PATH, global_step=step)
step += 1
except tf.errors.OutOfRangeError:
break
return step
def main():
# 定义初始化函数。
initializer = tf.random_uniform_initializer(-0.05, 0.05)
# 定义训练用的循环神经网络模型。
with tf.variable_scope("nmt_model", reuse=None,
initializer=initializer):
train_model = NMTModel()
# 定义输入数据。
data = MakeSrcTrgDataset(SRC_TRAIN_DATA, TRG_TRAIN_DATA, BATCH_SIZE)
iterator = data.make_initializable_iterator()
(src, src_size), (trg_input, trg_label, trg_size) = iterator.get_next()
# 定义前向计算图。输入数据以张量形式提供给forward函数。
cost_op, train_op = train_model.forward(src, src_size, trg_input,
trg_label, trg_size)
# 训练模型。
saver = tf.train.Saver()
step = 0
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(NUM_EPOCH):
print("In iteration: %d" % (i + 1))
sess.run(iterator.initializer)
step = run_epoch(sess, cost_op, train_op, saver, step)
# if __name__ == "__main__":
main()
测试代码
- 在解码过程中,模型只能看到输入句子,却不能看到目标句子。解码器在第一步读取
- 这个过程需要使用一个循环结构来实现,在TensorFlow中,循环结构是由tf.while_loop来实现
tf.while_loop使用
- cond是一个函数,负责判断继续执行循环的条件
- loop_body是每个循环体内执行的操作,负责对循环状态更新
- init_state为循环的起始状态,它可以包含多个Tensor或者TensorArray
- 返回的结果是循环结束时的循环状态
final_state = tf.while_loop(cood, loop_body, init_state)import tensorflow as tf
import codecs
import sys
# 1.参数设置。
# 读取checkpoint的路径。9000表示是训练程序在第9000步保存的checkpoint。
CHECKPOINT_PATH = "./seq2seq_ckpt-9000"
# 模型参数。必须与训练时的模型参数保持一致。
HIDDEN_SIZE = 1024 # LSTM的隐藏层规模。
NUM_LAYERS = 2 # 深层循环神经网络中LSTM结构的层数。
SRC_VOCAB_SIZE = 10000 # 源语言词汇表大小。
TRG_VOCAB_SIZE = 4000 # 目标语言词汇表大小。
SHARE_EMB_AND_SOFTMAX = True # 在Softmax层和词向量层之间共享参数。
# 词汇表文件
SRC_VOCAB = "./en.vocab"
TRG_VOCAB = "./zh.vocab"
# 词汇表中和的ID。在解码过程中需要用作为第一步的输入,并将检查
# 是否是,因此需要知道这两个符号的ID。
SOS_ID = 1
EOS_ID = 2
# 2.定义NMT模型和解码步骤。
# 定义NMTModel类来描述模型。
class NMTModel(object):
# 在模型的初始化函数中定义模型要用到的变量。
def __init__(self):
# 定义编码器和解码器所使用的LSTM结构。
self.enc_cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE)
for _ in range(NUM_LAYERS)])
self.dec_cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE)
for _ in range(NUM_LAYERS)])
# 为源语言和目标语言分别定义词向量。
self.src_embedding = tf.get_variable(
"src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable(
"trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
# 定义softmax层的变量
if SHARE_EMB_AND_SOFTMAX:
self.softmax_weight = tf.transpose(self.trg_embedding)
else:
self.softmax_weight = tf.get_variable(
"weight", [HIDDEN_SIZE, TRG_VOCAB_SIZE])
self.softmax_bias = tf.get_variable(
"softmax_bias", [TRG_VOCAB_SIZE])
def inference(self, src_input):
# 虽然输入只有一个句子,但因为dynamic_rnn要求输入是batch的形式,因此这里
# 将输入句子整理为大小为1的batch。
src_size = tf.convert_to_tensor([len(src_input)], dtype=tf.int32)
src_input = tf.convert_to_tensor([src_input], dtype=tf.int32)
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
# 使用dynamic_rnn构造编码器。这一步与训练时相同。
with tf.variable_scope("encoder"):
enc_outputs, enc_state = tf.nn.dynamic_rnn(
self.enc_cell, src_emb, src_size, dtype=tf.float32)
# 设置解码的最大步数。这是为了避免在极端情况出现无限循环的问题。
MAX_DEC_LEN=100
with tf.variable_scope("decoder/rnn/multi_rnn_cell"):
# 使用一个变长的TensorArray来存储生成的句子。
init_array = tf.TensorArray(dtype=tf.int32, size=0,
dynamic_size=True, clear_after_read=False)
# 填入第一个单词作为解码器的输入。
init_array = init_array.write(0, SOS_ID)
# 构建初始的循环状态。循环状态包含循环神经网络的隐藏状态,保存生成句子的
# TensorArray,以及记录解码步数的一个整数step。
init_loop_var = (enc_state, init_array, 0)
# tf.while_loop的循环条件:
# 循环直到解码器输出,或者达到最大步数为止。
def continue_loop_condition(state, trg_ids, step):
return tf.reduce_all(tf.logical_and(
tf.not_equal(trg_ids.read(step), EOS_ID),
tf.less(step, MAX_DEC_LEN-1)))
def loop_body(state, trg_ids, step):
# 读取最后一步输出的单词,并读取其词向量。
trg_input = [trg_ids.read(step)]
trg_emb = tf.nn.embedding_lookup(self.trg_embedding,
trg_input)
# 这里不使用dynamic_rnn,而是直接调用dec_cell向前计算一步。
dec_outputs, next_state = self.dec_cell.call(
state=state, inputs=trg_emb)
# 计算每个可能的输出单词对应的logit,并选取logit值最大的单词作为
# 这一步的而输出。
output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE])
logits = (tf.matmul(output, self.softmax_weight)
+ self.softmax_bias)
next_id = tf.argmax(logits, axis=1, output_type=tf.int32)
# 将这一步输出的单词写入循环状态的trg_ids中。
trg_ids = trg_ids.write(step+1, next_id[0])
return next_state, trg_ids, step+1
# 执行tf.while_loop,返回最终状态。
state, trg_ids, step = tf.while_loop(
continue_loop_condition, loop_body, init_loop_var)
return trg_ids.stack()
# 3.翻译一个测试句子。
def main():
# 定义训练用的循环神经网络模型。
with tf.variable_scope("nmt_model", reuse=None):
model = NMTModel()
# 定义个测试句子。
test_en_text = "This is a test . "
print(test_en_text)
# 根据英文词汇表,将测试句子转为单词ID。
with codecs.open(SRC_VOCAB, "r", "utf-8") as f_vocab:
src_vocab = [w.strip() for w in f_vocab.readlines()]
src_id_dict = dict((src_vocab[x], x) for x in range(len(src_vocab)))
test_en_ids = [(src_id_dict[token] if token in src_id_dict else src_id_dict[''])
for token in test_en_text.split()]
print(test_en_ids)
# 建立解码所需的计算图。
output_op = model.inference(test_en_ids)
sess = tf.Session()
saver = tf.train.Saver()
saver.restore(sess, CHECKPOINT_PATH)
# 读取翻译结果。
output_ids = sess.run(output_op)
print(output_ids)
# 根据中文词汇表,将翻译结果转换为中文文字。
with codecs.open(TRG_VOCAB, "r", "utf-8") as f_vocab:
trg_vocab = [w.strip() for w in f_vocab.readlines()]
output_text = ''.join([trg_vocab[x] for x in output_ids])
# 输出翻译结果。
print(output_text.encode('utf8').decode(sys.stdout.encoding))
sess.close()
# if __name__ == "__main__":
main()
注意力模型
- 在Seq2Seq模型中,编码器将完整的输入句子压缩到一个维度固定的向量中,然后解码器根据这个向量生成输出句子。
- 当输入句子较长时,这个中间向量难以存储足够的信息,就成为这个模型的一个瓶颈。
-
注意力(Attention)机制就是为了解决这个问题而设计的。注意力机制允许解码器随时查阅输入句子中的部分单词或片段,因此不再需要在中间向量中存储所有信息。
-
解码器在解码的每一步将隐藏状态作为查询的输入来”查询“编码器的隐藏状态,在每个输入的位置计算一个反映与查询输入相关程度的权重,再根据这个权重对各输入位置的隐藏状态求加权平均。
-
加权平均后得到的向量称为”context“,表示它是与翻译当前单词最相关的原文信息。
-
在解码下一个单词时,将context作为额外信息输入到循环神经网络中,这样循环神经网络可以时刻读取原文中最相关的信息,而不必完全依赖于上一时刻的隐藏状态。
-
通过context向量,解码器可以在解码的每一步查询最相关的原文信息,从而避免Seq2Seq模型中信息瓶颈问题。
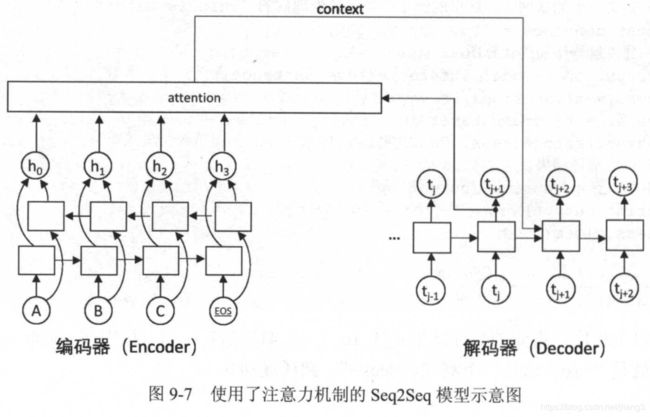

数学定义


- 注意力机制还有多种其他设计,e(h,s)的公式不一样,但是通过softmax计算权重a和通过加权平均计算context的方法是一样的。
注意力模型与Seq2Seq的不同
- 增加了注意力机制
- 编码器采用了双向循环网络,因为在解码器通过注意力查询一个单词时,通常也需要知道单词周围的部分信息。
- 取消了编码器与解码器之间的连接,解码器完全依赖于注意力机制获取原文信息。
- 使得编码器和解码器可以独立自由选择模型,可以选择不同层数、不同维度、不同结构的循环神经网络
TensorFlow提供了几种预置的实现,tf.contrib.seq2seq.AttentionWrapper将编码器的神经网络层和注意力层结合,成为一个更高层的循环神经网络。
# 下面的self.enc_cell_fw和self.enc_cell_bw定义了编码器中的前向和后向循环网络,
# 它取代了Seq2Seq样例中__init__里的self.enc_cell。
self.enc_cell_fw = tf.nn.rcc_cell.BasicLSTMCell(HIDDENT_SIZE)
self.enc_cell_bw = tf.nn.rcc_cell.BasicLSTMCell(HIDDENT_SIZE)
# 下面的代码取代了Seq2Seq样例中forward函数的相应部分
with tf.variable_scope('encoder'):
# 构造编码器时,使用bidirectional_dynamic_cnn构造双向循环网络。
# 双向循环网络的顶层输出enc_outputs是一个包含两个张量的tuple,
# 每个张量的维度都是[batch_size, max_time, HIDDEN_SIZE],
# 代表两个LSTM在每一步的输出。
enc_outputs, enc_state = tf.nn.bidirectional_dynamic_rnn(
self.enc_cell_fw, self.enc_cell_bw, src_emb, src_size,
dtype=tf.float32)
# 将两个LSTM的输出拼接为一个张量。
enc_outputs = tf.concat([enc_outputs[0], enc_outputs[1]], -1)
with tf.variable_scope("decoder"):
# 选择注意力权重的计算模型。BahdanauAttention是使用一个隐藏层的前馈神经网络。
# memory_sequence_length是一个维度为[batch_size]的张量,代表batch
# 中每个句子的长度,Attention需要根据这个信息把填充位置的注意力权重设置为0。
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(
HIDDEN_SIZE, enc_outputs,
memory_sequence_length=src_size)
# 将解码器的循环神经网络self.dec_cell和注意力一起封装成更高层的循环神经网络。
attention_cell = tf.contrib.seq2seq.AttentionWrapper(
self.dec_cell, attention_mechanism,
attention_layer_size=HIDDEN_SIZE)
# 使用attention_cell和dynamic_rnn构造编码器。
# 这里没有指定init_state,也就是没有使用编码器的输出来初始化输入,而完全依赖
# 注意力作为信息来源。
dec_outputs, _ = tf.nn.dynamic_rnn(
attention_cell, trg_emb, trg_size, dtype=tf.float32)- 一方面注意力机制使得编码器可以在每一步主动查询最相关的信息,而暂时忽略不相关的信息;
- 另一方面,它大大缩短了信息流动的距离,解码器在任意时刻只需一步就可以查阅输入的任意单词。