目标检测系列(七)——CornerNet:detecting objects as paired keypoints
文章目录
- 摘要
- 1、引言
- 2、相关工作
- 3、CornerNet
- 3.1 概况
- 3.2 检测角点
- 3.3 角点的分组
- 3.4 Corner Pooling
- 3.5 沙漏网络
论文链接: https://arxiv.org/abs/1808.01244
代码链接: https://github.com/umich-vl/CornerNet
摘要
本文提出了CornetNet,一种利用单个卷积神经网络来检测b-box的方法,且是通过检测b-box的“左上”和“右下”两个关键点来检测b-box。
相比之前的单阶段检测器,本文的方法不需要设定一系列的anchor box,且本文引入了corner pooling,有助于网络更好的定位corners。
CornerNet网络的效果:在 MS COCO 上获得了42.2%的 AP,比目前的所有单阶段检测器都要好。
1、引言
目前的单阶段检测因为引入了anchor机制,获得可以和两阶段检测相媲美的精度的同时,有较高的效率。单阶段检测器在输入图像上放置了密集的 anchor ,并通过微调和回归 box 尺寸来得到最终的预测。
使用anchor的方法的缺点:
-
正负样本不均衡:大部分检测算法的anchor数量都成千上万,(DSSD中使用了多于40k个anchor,RetinaNet 中使用了多于100k个anchor)但是一张图中的目标数量并没有那么多,这就导致正样本数量会远远小于负样本,因此有了对负样本做欠采样以及 focal loss等算法来解决这个问题。
-
引入更多的超参数,比如anchor的数量、大小和宽高比等。
本文 CornerNet 的特点:
-
一种新的、无anchor的单阶段目标检测方法
-
检测 b-box 的左上和右下角的角点
-
使用单个卷积神经网络来预测同一目标类别(category)中的所有实例的“左上”角点的和heatmap、右下角点的heatmap、每个检测到角点的 embedding vector。嵌入向量用于对属于同一目标的corner进行分组,也就是该网络的训练目标是实现对同一目标的“左上”和“右下”角点进行匹配,将两者预测得到相同的嵌入向量。
-
本文的方法很大程度地简化了网络的输出,并且无需设计相应的 anchor。
-
本文方法灵感源于Newell等人的文章(2017)中的多人姿态估计上下文中关联嵌入方法,结构如图1所示。
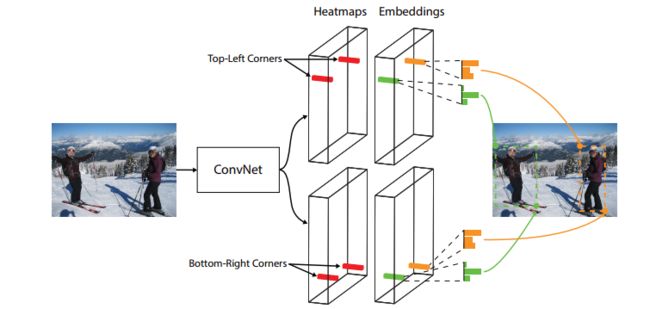
图1 将目标检测为一对b-box的角点利用卷积网络,对所有的左上角点生成一幅热力图,对所有右下角点生成一幅热力图,并且对所有检测到的角点生成一个嵌入式向量。
训练网络将属于同一目标的角点预测成相同的嵌入式向量
-
corner pooling:一种新的 pooling 方法,有助于卷积网络更好的定位b-box的角点。一个b-box的corner常常位于目标之外,如图2所示,所以不能使用局部信息来对corner进行定位。

为了确定在某个像素点上是否有“左上”角点,需要从目标边界的最上边从右至左来进行水平扫描,从边界的左边从下至上来进行垂直扫描,该扫描方法启发了我们corner pooling 方法的产生。最终的输出源于两个特征图,它包含两个特征图; 在每个像素位置,它最大池化从第一个特征映射到右侧的所有特征向量,最大池化从第二个特征映射下面的所有特征向量,然后将两个池化结果一起添加,如图3所示

我们认为,检测角点效果比检测b-box中心点或region proposal 方法更好的原因有两个: -
b-box 的中心确定后也很难确定b-box的位置,因为其基于目标的四个边,而定位角点只基于两个边,更简单。且使用 corner pooling使其更加简单,因为该pooling方法能够对corner的先验知识进行编码。
-
角点能够提供更有效的方法来密集的离散化box空间,只需要 O ( w h ) O(wh) O(wh) 个角点就可以表示 0 ( w 2 h 2 ) 0(w^2h^2) 0(w2h2) 个 anchor boxes。
2、相关工作
已有的两阶段目标检测方法精度高但效率较低,已有的单阶段目标检测方法也借鉴了 anchor-based 方法, SSD 和 RetinaNet 都使用了很多的anchor来进行检测,但 Lin 等人(2017)在文章中提出,稠密的 anchor box会导致严重的正负样本不平衡问题,从而发生难以训练或训练效果较差的问题。故他们提出了focal loss的方法,来动态调整每个anchor box的权重,使得单阶段的方法能够接近两阶段检测的方法。
RefineDet(2017)提出了对anchor box 进行滤波的方法来减少负box的量,粗尺度的调整 anchor box。
本文的方法受启发于Newell的多人姿态估计上下文中关联嵌入[27]。Newell等人提出了一种在单个网络中检测和分组人类关节的方法。在他们的方法中,每个检测到的人类关节都有一个嵌入向量。这些关节是根据它们嵌入向量的距离来分组的。
本文是第一个将目标检测任务定义为同时检测和分组角点的任务。我们的另一个新颖之处在于corner pooling layer,它有助于更好定位角点。我们还对沙漏结构进行了显著地修改,并添加了新的focal loss[23]的变体,以帮助更好地训练网络。
3、CornerNet
3.1 概况
cornernet 是通过检测b-box的左上和右下角点来检测一个目标的,通过一个卷积网络预测两组热力图来表示不同类别目标的角点位置,一个热力图表示左上角点,一个热力图表示右下角点。
神经网络同时可以对每个检测到的角点预测嵌入向量,两个源于同一b-box的角点向量距离肯定是最短的。
为了产生紧的b-box,网络同时预测偏移来稍微调整角点的位置,有了预测的热力图、嵌入向量和偏移,我们就可以使用简单的后处理方法来得到最终的b-box。
图4展示了 CornerNet 的结构,我们使用沙漏网络(hourglass network)作为backbone,沙漏网络之后跟两个预测模块:一个模块是左上角点,另一个模块是右下角点。

每个模块都有其自己的corner pooling 模型对沙漏网络的输出进行pooling,即在预测热力图、嵌入向量和偏移之前就pooling。
不同于其他检测器,我们没有使用来自不同尺度的特征。
3.2 检测角点
我们需要预测两组热力图,一组是左上角点的热力图,另一组是右下角点的热力图。
每组热力图有 C 个通道(C 为目标类别),大小为 HxW,没有背景通道。每个通道是表示每个类别的角点的二值掩膜。
对于每个角点,有一个真值 positive 位置,其余的都是 negative 位置,训练过程中,我们没有对负位置都使用相同的惩罚,而是根据其到正位置的半径距离来惩罚,因为一对错误的角点检测如果和正确的角点检测相距很近,其产生的框和真实框交并比会很大,如图5所示。

我们通过确保半径内的一对点生成的边界框与ground-truth的IoU ≥ t(我们在所有实验中将t设置为0.3)来确定物体的大小,从而确定半径。
给定半径之后,惩罚的量会根据非标准的 2D 高斯分布 e − x 2 + y 2 2 δ 2 e^{-\frac{x^2+y^2}{2\delta^2}} e−2δ2x2+y2来确定,该高斯分布的中心是在正例位置,且其 δ \delta δ 是半径的1/3。
令 p c i j p_{cij} pcij 表示预测的热力图中类别 c 在位置 (i,j) 上的得分, y c i j y_{cij} ycij 是用非标准化高斯增强得到的真实热力图。
定义 focal loss 的变体如下:

- N 是图像中目标的个数
- α \alpha α 和 β \beta β 是控制每个点的权重(贡献量)的超参数( α = 2 \alpha=2 α=2 、 β = 4 \beta=4 β=4 )
利用 y c i j y_{cij} ycij 中编码的高斯凸点, ( 1 − y c i j ) (1−ycij) (1−ycij) 减少了ground-truth周围点的惩罚。
许多网络使用下采样层来综合全局信息,且减少内存使用,当在图像的全卷积过程中使用该方法时,网络的输出总数小于输入图像的大小,所以输入图像的位置 ( x , y ) (x,y) (x,y) 会投影到热力图中的 ( ⌊ x n ⌋ , ⌊ y n ⌋ ) (\lfloor \frac{x}{n}\rfloor,\lfloor \frac{y}{n}\rfloor) (⌊nx⌋,⌊ny⌋),其中 n n n 是下采样因子。
当从热力图中定位原图中的位置时,可能会丢失一定的精度,这会很大的影响小的b-box和其真实框的 IoU,所以在从热力图估计原图中的位置的时候,先估计一个offset来调整一下角点的位置。
![]()
其中, O k O_k Ok 是偏移 offset, x k x_k xk 和 y k y_k yk 是角点 k k k 的坐标。
我们预测的所有类别的左上角共享一组偏移,右下角共享一组偏移。
训练过程中,我们在真实角点的位置使用 smooth L1 loss :

3.3 角点的分组
一个图像中可能出现多种不同类别的目标,所以可能会检测出来多种左上角和右下角的角点,我们需要确定一组左上+右下角点是否源于同一个box。
判断的方法源于 Newell,因为网络对源于同一个box的角点预测的嵌入向量的距离是最短的,我们可以基于左上和右下角点的嵌入向量的距离来对角点进行分组,而嵌入向量内在的值是不用关心的,我们只使用两者的距离。
我们只使用以为的嵌入向量,令 e t k e_{t_k} etk表示目标 k k k 的 top-left角点, e b k e_{b_k} ebk表示目标 k k k 的 bottom-right 角点。
我们使用 “pull” loss 来训练网络来分组角点,使用“push” loss 来分离角点:

其中, e k e_k ek 是 e t k e_{t_k} etk 和 e b k e_{b_k} ebk 的均值,令 Δ = 1 \Delta=1 Δ=1,与偏移损失类似,我们仅在ground-truth角点位置应用损失。
3.4 Corner Pooling
如图2所示,通常没有局部视觉证明角点的存在,为了确定一个像素点是不是左上角点(top-left),我们需要从目标边界最上面从右向左水平扫描,从目标边界的最左边从下向上垂直扫描最大值。
我们提出了 corner pooling 来通过编码一直先验信息来更好的定位角点。
假设我们想要确定位置 ( i , j ) (i,j) (i,j) 的像素是否是一个 top-left 角点,令 f t f_t ft 和 f l f_l fl 作为 top-left pooling 层的输入, f t i j f_{t_{ij}} ftij 和 f l i j f_{l_{ij}} flij 分别为 f t f_t ft 和 f l f_l fl 的 ( i , j ) (i,j) (i,j) 位置上的向量。
特征图大小为 H × W H\times W H×W,corner pooling 层首先对 f t f_t ft 中的 ( i , j ) (i,j) (i,j) 和 ( i , H ) (i,H) (i,H) 之间的像素进行最大池化,得到 t i j t_{ij} tij。之后对 f l f_l fl 中的 ( i , j ) (i,j) (i,j) 和 ( W , j ) (W,j) (W,j) 之间的像素进行最大池化,得到 l i j l_{ij} lij。最后,将 t i j t_{ij} tij 和 l i j l_{ij} lij 相加,结算公式如下:
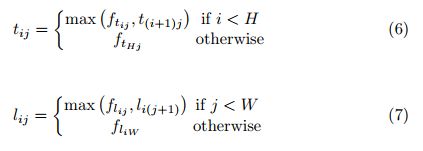
其中,我们使用的是像素域最大化操作,其过程如图6所示,右下角点的corner pooling 操作相同。

我们的对所有 ( 0 , j ) (0,j) (0,j) 和 ( i , j ) (i,j) (i,j) 之间的特征向量进行最大池化,对所有 ( i , 0 ) (i,0) (i,0) 和 ( i , j ) (i,j) (i,j) 之间的特征也进行最大池化,然后将两者重合的地方相加即可。
corner pooling作用:用于预测热力图、嵌入向量、偏移
预测模块结构如图7所示,第一个部分是修正后的残差模块,该修正的残差模块中,将第一个 3x3 卷积模块用 corner pooling 代替。
修正后的残差模块:首先用128个通道的3x3的卷积模块处理从backbone网络输出的特征向量,之后使用 corner pooling。
残差模块之后:将经过 corner pooling 的特征向量输入 256 个通道的 3x3 的Conv-BN 层,同时加上一个映射捷径。
修正的残差模块之后连接一个有256通道的3x3卷积模块,和 3 个Conv-ReLU-Conv 层来产生热力图、嵌入式向量和偏移。

3.5 沙漏网络
CornerNet 网络使用沙漏网络作为backbone。
沙漏网络最初提出是为了人体姿态估计任务,该网络是一个全卷积网络,包含了多个沙漏模块。
沙漏模块:首先对输入特征利用一系列的卷积核最大池化进行下采样,之后通过一系列上采用和卷积层来对特征进行上采样,使得能够获得和原始输入分辨率一样的输出。
因为最大池化会使得丢失一定的细节信息,所以使用跳跃连接层来重现。
当网络中使用多个沙漏网络时,沙漏模型可以重新处理特征,来捕捉信息的高层特征,该特性使得沙漏网络成为目标检测的理想backbone选择。
本文的沙漏网络(hourglass network)包含了两个沙漏结构,并且我们做了一些修正。
- 我们没有使用最大池化,使用步长为2来降低特征分辨率,我们降低了5倍的分辨率,并且提高了特征通道数(256,384,384,384,512)。
当对特征进行上采样时,我们使用 2 个残差模块,之后使用最近邻上采样。
每个跳跃连接也是由 2 个残差模块组成的,沙漏网络中间有4个512通道的残差模块,进入沙漏模块之前,我们使用步长为2,通道数为128,的7x7的卷积模块将图像分辨率降低 4 倍,之后使用步长为2,通道数为256的残差模块。
类似于 Newell 的文章,我们也在训练时增加了中间监督,但没有给网络添加中间预测回传,这会损害网络性能。
我们给第一个沙漏模块的输入和输出都使用了 1x1 的 onv-BN 模块,之后通过像素相加并使用 Relu 和残差模块,作为第二个沙漏模块的输入。
沙漏网络的深度为104,不同于其他性能较好的检测器,我们只使用的所有网络的最后一层的输出来预测。