Hadoop 2.0 HA 3节点高可用集群搭建
概览
1.集群规划
2.准备
3.修改Hadoop配置文件
4.复制内容
5.启动集群
6.查看jps
7.测试
1.集群规划
HDFS HA背景
HDFS集群中NameNode 存在单点故障(SPOF)。对于只有一个NameNode的集群,如果NameNode机器出现意外情况,将导致整个集群无法使用,直到NameNode 重新启动。
影响HDFS集群不可用主要包括以下两种情况:一是NameNode机器宕机,将导致集群不可用,重启NameNode之后才可使用;二是计划内的NameNode节点软件或硬件升级,导致集群在短时间内不可用。
为了解决上述问题,Hadoop给出了HDFS的高可用HA方案:HDFS通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,比如处理来自客户端的RPC请求,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便能够在它失败时快速进行切换。
规划
之后的服务启动和配置文件都是安装此配置来,master上是namenode,slave2上是yarn,而slave1则是namenode和yarn的备用
| 主机名 | IP | Namenode | DataNode | Yarn | Zookeeper | JournalNode |
|---|---|---|---|---|---|---|
| master | 192.168.134.154 | 是 | 是 | 否 | 是 | 是 |
| slave1 | 192.168.134.155 | 是 | 是 | 是 | 是 | 是 |
| slave2 | 192.168.134.156 | 否 | 是 | 是 | 是 | 是 |
需要说明以下几点:
HDFS HA通常由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便能够在它失败时快速进行切换。
Hadoop 2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode,这里还配置了一个Zookeeper集群,用于ZKFC故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为Active状态。
YARN的ResourceManager也存在单点故障问题,这个问题在hadoop-2.4.1得到了解决:有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调。
YARN框架下的MapReduce可以开启JobHistoryServer来记录历史任务信息,否则只能查看当前正在执行的任务信息。
Zookeeper的作用是负责HDFS中NameNode主备节点的选举,和YARN框架下ResourceManaer主备节点的选举。
2.准备
软件:
1.jdk1.8.141
2.hadoop2.7.3(jdk1.8版本编译)
3.Zookeeper3.4.12
4.Xshell5 + Xftp5
1.设置静态ip,参考Hadoop集群单机版的设置静态ip,然后使用Xshell工具连接(官网有免费版本)
2.配置jdk,hosts文件
jdk安装参考Hadoop集群单机版的jdk安装
[root@master bin]# vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# 上面的给注释掉或者删除
192.168.134.154 master
192.168.134.155 slave1
192.168.134.156 slave2
3.配置ssh免密登录,参考Hadoop集群搭建的ssh免密登录
4.配置Zookeeper,参考Zookeeper的安装
3.修改Hadoop配置文件
如果你之前搭建过hadoop集群,只需要将其中的配置文件做修改即可
1.在/usr下创建个hadoop文件夹,作为hadoop安装(压缩)包的存放路径和解压路径
#进入usr文件夹下
cd /usr
#创建hadoop文件夹
mkdir hadoop
#进入hadoop文件夹
cd hadoop
利用Xftp工具将文件传输到虚拟机中

解压后进入到 hadoop的解压路径/etc/hadoop文件夹下
cd /usr/hadoop/hadoop-2.7.3/etc/hadoop/
3.1.core-site.xml
vim core-site.xml
在其中的configuration标签中添加以下内容
fs.defaultFS
hdfs://ns
hadoop.tmp.dir
/HA/hadoop/tmp
io.file.buffer.size
4096
ha.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
ipc.client.connect.max.retries
100
Indicates the number of retries a client will make to establish
a server connection.
ipc.client.connect.retry.interval
10000
Indicates the number of milliseconds a client will wait for
before retrying to establish a server connection.
3.2.hdfs-site.xml
vim hdfs-site.xml
在其中的configuration标签中添加以下内容
dfs.nameservices
ns
dfs.ha.namenodes.ns
nn1,nn2
dfs.namenode.rpc-address.ns.nn1
master:9000
dfs.namenode.http-address.ns.nn1
master:50070
dfs.namenode.rpc-address.ns.nn2
slave1:9000
dfs.namenode.http-address.ns.nn2
slave1:50070
dfs.namenode.shared.edits.dir
qjournal://master:8485;slave1:8485;slave2:8485/ns
dfs.journalnode.edits.dir
/HA/hadoop/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.namenode.name.dir
file:///HA/hadoop/hdfs/name
dfs.datanode.data.dir
file:///HA/hadoop/hdfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
3.3.mapred-site.xml
这个文件刚开始是没有的,所以我们需要将其创建出来
#利用模版文件copy出来一个
cp mapred-site.xml.template mapred-site.xml
然后在其configuration标签中添加以下内容vim mapred-site.xml
mapreduce.framework.name
yarn
3.4.yarn-site.xml
vim yarn-site.xml
在其configuration标签中添加以下内容
普通版
只有slave2有Resourcemanager
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
slave2
yarn HA高可用版
slave1和slave2都有Resourcemanager
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.cluster-id
yarncluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
slave2
yarn.resourcemanager.hostname.rm2
slave1
yarn.resourcemanager.webapp.address.rm1
slave2:8088
yarn.resourcemanager.webapp.address.rm2
slave1:8088
yarn.resourcemanager.zk-address
master:2181,slave1:2181,slave2:2181
yarn.resourcemanager.zk-state-store.parent-path
/rmstore
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.nodemanager.recovery.enabled
true
yarn.nodemanager.address
0.0.0.0:45454
3.5 .hadoop-env.sh
export JAVA_HOME=${JAVA_HOME} 一行,
将其修改为 export JAVA_HOME=/usr/java/jdkxxx(jdk的安装路径)
3.6.修改slaves文件(dataNode)
修改为
#localhost
#你的集群主机名
master
slave1
slave2
4.复制内容到slave1,slave2
如果你的slave1和slave2什么也没有,可以一并将配置jdk的profile文件和配置ip映射的hosts文件一起复制过去,Zookeeper则需要注意改下配置文件
#复制给slave1,如果之前有hadoop也会覆盖
[root@master hadoop]# scp -r /usr/hadoop root@slave1:/usr/
#复制给slave2
[root@master hadoop]# scp -r /usr/hadoop root@slave2:/usr/
5.启动集群
5.1分别启动Zookeeper
所有虚拟机全部启动
在Zookeeper安装目录的/bin目录下启动
[root@master hadoop]# cd /usr/zookeeper/zookeeper-3.4.12/bin
[root@master bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/zookeeper/zookeeper-3.4.12/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
启动后查看状态
[root@slave1 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/zookeeper/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: leader #leader或者follower则代表启动Zookeeper成功
5.2在master,slave1,slave2上启动journalnode
#进入到hadoop安装目录sbin文件夹下
[root@master bin]# cd /usr/hadoop/hadoop-2.7.3/sbin/
[root@master sbin]# ls
distribute-exclude.sh kms.sh start-balancer.sh stop-all.cmd stop-yarn.cmd
hadoop-daemon.sh mr-jobhistory-daemon.sh start-dfs.cmd stop-all.sh stop-yarn.sh
hadoop-daemons.sh refresh-namenodes.sh start-dfs.sh stop-balancer.sh yarn-daemon.sh
hdfs-config.cmd slaves.sh start-secure-dns.sh stop-dfs.cmd yarn-daemons.sh
hdfs-config.sh start-all.cmd start-yarn.cmd stop-dfs.sh
httpfs.sh start-all.sh start-yarn.sh stop-secure-dns.sh
#这里有一个daemons和daemon,不带s是启动单个,带s是启动集群
[root@master sbin]# ./hadoop-daemons.sh start journalnode
slave2: starting journalnode, logging to /usr/hadoop/hadoop-2.7.3/logs/hadoop-root-journalnode-slave2.out
slave1: starting journalnode, logging to /usr/hadoop/hadoop-2.7.3/logs/hadoop-root-journalnode-slave1.out
master: starting journalnode, logging to /usr/hadoop/hadoop-2.7.3/logs/hadoop-root-journalnode-master.out
分别在master,slave1,slave2上查看jps
#这样正常,否则查看你的Zookeeper是否启动成功
[root@master sbin]# jps
2232 JournalNode
2281 Jps
2157 QuorumPeerMain
5.3在master上格式化zkfc
[root@master sbin]# hdfs zkfc -formatZK
5.4在master上格式化hdfs
[root@master sbin]# hadoop namenode -format
5.5在master上启动namenode
[root@master sbin]# ./hadoop-daemon.sh start namenode
starting namenode, logging to /usr/hadoop/hadoop-2.7.3/logs/hadoop-root-namenode-master.out
[root@master sbin]# jps
2232 JournalNode
2490 Jps
2157 QuorumPeerMain
2431 NameNode
5.6在slave1上启动数据同步和standby的namenode
[root@slave1 sbin]# hdfs namenode -bootstrapStandby
[root@slave1 sbin]# ./hadoop-daemon.sh start namenode
5.7在master上启动datanode
[root@master sbin]# ./hadoop-daemons.sh start datanode
master: starting datanode, logging to /usr/hadoop/hadoop-2.7.3/logs/hadoop-root-datanode-master.out
slave2: starting datanode, logging to /usr/hadoop/hadoop-2.7.3/logs/hadoop-root-datanode-slave2.out
slave1: starting datanode, logging to /usr/hadoop/hadoop-2.7.3/logs/hadoop-root-datanode-slave1.out
5.8在slave1和slave2上启动yarn
./start-yarn.sh
5.9在master上启动zkfc
./hadoop-daemons.sh start zkfc
6.查看jps
master
[root@master sbin]# jps
2593 DataNode
2709 NodeManager
2902 DFSZKFailoverController
2232 JournalNode
2969 Jps
2157 QuorumPeerMain
2431 NameNode
slave1
[root@slave1 sbin]# jps
2337 QuorumPeerMain
3074 Jps
2259 JournalNode
2709 ResourceManager
2475 NameNode
2587 DataNode
3007 DFSZKFailoverController
slave2
[root@slave2 sbin]# jps
2355 DataNode
2164 JournalNode
2244 QuorumPeerMain
3126 NodeManager
3017 ResourceManager
3162 Jps
启动如上则正常
如果有服务没有启动,重启该服务,例如Resourcemanager没启动
#停止
./stop-yarn.sh
#启动
./start-yarn.sh
然后在50070和8088端口进行测试
在测试之前为了防止namenode不能热切换,最好安装此插件
在master和slave1上安装
yum -y install psmisc
7.测试
在(master的ip)192.168.134.154:50070和(slave1的ip)192.168.134.155:50070上查看namenode的状态
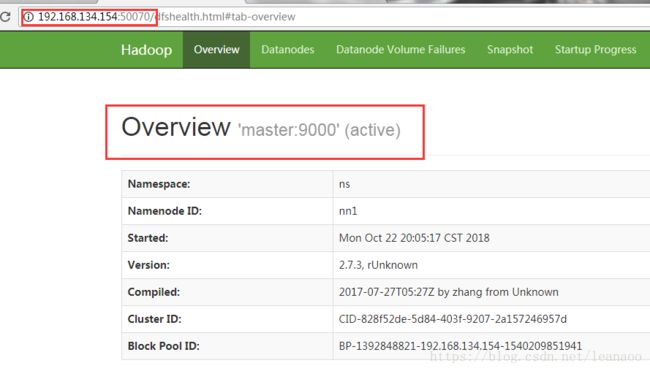
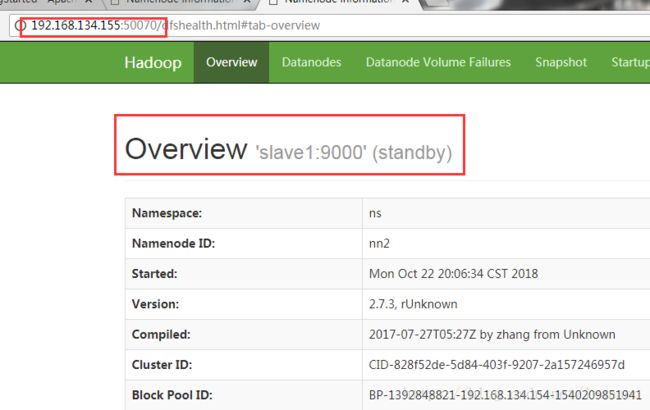
都能访问且一个是active一个是standby状态
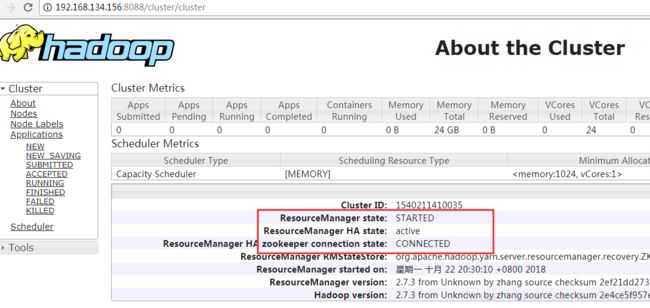
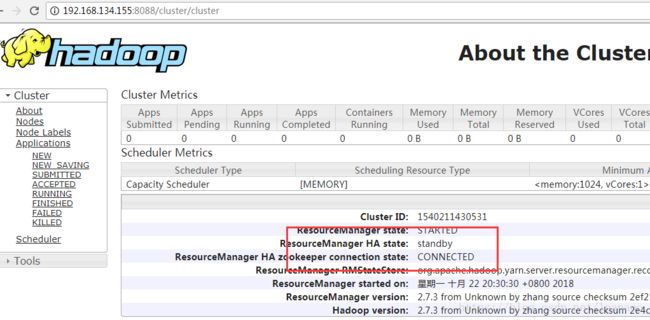
然后访问(slave1)192.168.134.155:8088和(slave2)192.168.134.156:8088查看Resourcemanager状态
若是一个能访问,访问另一个时跳到前一个的时候并不是错误,那样是正常的
能访问的那个是active状态,若是两个都能访问则一个是active一个是standby

首先在master主机上想hdfs上传一个文件,然后尝试能否在slave1和slave2上查看
[root@master tmp]# cd /usr/tmp
[root@master tmp]# touch test
[root@master tmp]# hadoop fs -put test /
#分别在三台虚拟机上查看
[root@master tmp]# hadoop fs -ls /
Found 1 items
-rw-r--r-- 3 root supergroup 0 2018-10-22 20:42 /test
如果都能查看到,接下来再测试是否能够热切换
#查看进程
[root@master tmp]# jps
2593 DataNode
2902 DFSZKFailoverController
2232 JournalNode
3609 NodeManager
2157 QuorumPeerMain
2431 NameNode
3807 Jps
#杀死active的namenode
[root@master tmp]# kill -9 2431
在网页查看standby的是否变为active
从standby成功变更为active则表示成功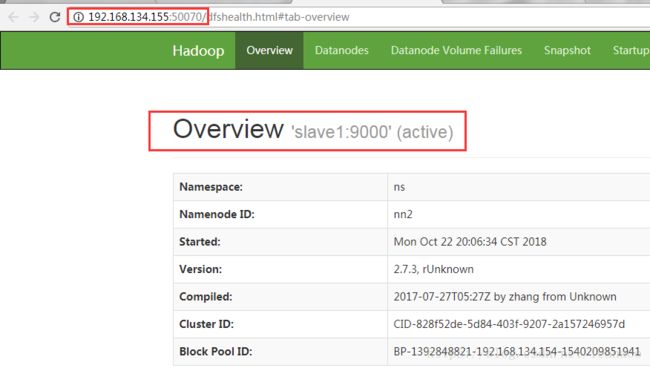
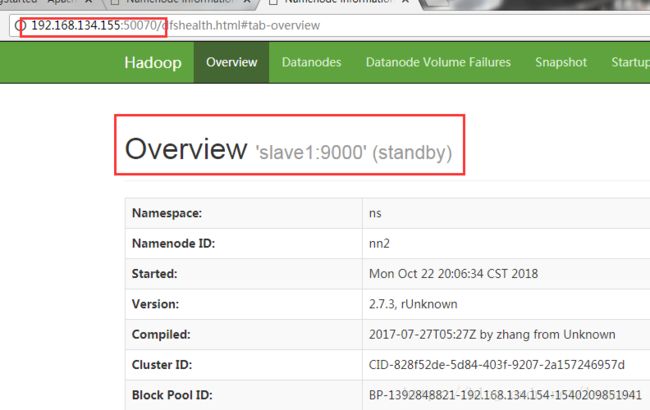
同样,测试yarn HA高可用
#查看进程
[root@slave2 sbin]# jps
4050 Jps
2355 DataNode
2164 JournalNode
2244 QuorumPeerMain
3423 ResourceManager
3919 NodeManager
#杀死active的ResourceManager
[root@slave2 sbin]# kill -9 3423
在网页查看

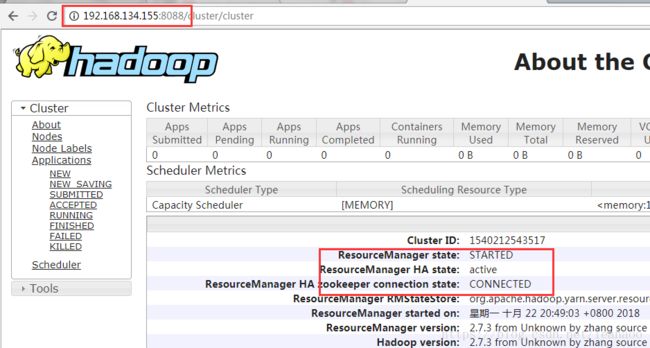
如果说你杀死了namenode进程,那么相应的50070端口则无法访问了,同理8088端口一样
至此hadoop HA高可用版搭建完成.
接下来会说一下hive的安装和使用