SparkML之特征提取(二)词项加权之DF-IDF
词项加权(Term Weighting)的目的是给分词后的词语加上权重。重要的词项给予更高的权重。那么当我们对文本
进行检索的时候。比如当我们在淘宝购物,输入“那本语义分析类的书最好”,那么我们进行Term Weighting可能
是:“那本:0.1,语义分析:0.8,类:0.2,的:0.1,书:0.5,最好:0.4”.那么当有这些权重时,对于突出搜索重
点是很有帮助的。最近因强调非结构化数据的处理,结合语义分析在推荐系统中可以得到非常广泛的应用。
词项加权的打分公式一般有三个部分组成:local、global和normalization。TermWeight的公式如下[1]:
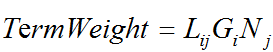
其中:

对于词项加权的关于local、global和normalization打分公式[1],如下:

图1:Local Weight formulas

图2:Local weight formulas
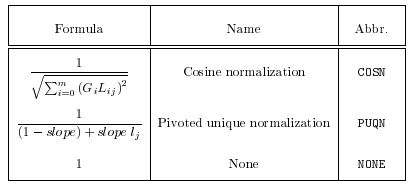
图3:Global Weight formulas
TF-IDF是一种简单高效的词项加权方法。在上面的公式体系里,TF-IDF的local weight是FREQ,global weight是
IDFB,normalization是None。其中TF是词频,表示这个词出现的次数。df是文档频率,表示这个词在多少个文档
中出现。IDF则是逆文档频率,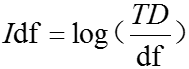 ,其中:TD表示总文档数。
,其中:TD表示总文档数。
步骤1:计算一篇文档中,出现’数学’的频率,即 ,比如数学出现了30次。一篇文件的总词语数是1000个,那么
”数学“一词的词频 为0.03
步骤2: 计算一个文件频率的逆,即IDF.比如‘数学’一次在1000份文件出现过,总文件数是:10000000.那么

步骤3:计算 TF-IDF= 0.03*4 = 12
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Spark源码分析
HashingTF类(计算df)
/**
* 用hash表的方式,把词项的频率放入到序列表中
* @param numFeatures number of features (default: 2^20^)
*/
@Since("1.1.0")
class HashingTF(val numFeatures: Int) extends Serializable {
import HashingTF._
private var binary = false
private var hashAlgorithm = HashingTF.Murmur3
/**
*/
@Since("1.1.0")
def this() = this(1 << 20)//1 << 20=2^20=1048576
/**
* 如果 true, 词项频率的向量会变成二进制,非零的词项会被设置为1
* (default: false)
*/
@Since("2.0.0")
def setBinary(value: Boolean): this.type = {
binary = value
this
}
/**
*在把词项映射到整数时,设置hash 算法,默认是 (murmur3)
* (default: murmur3)
*/
@Since("2.0.0")
def setHashAlgorithm(value: String): this.type = {
hashAlgorithm = value
this
}
/**
* 返回输入词项的索引
*/
@Since("1.1.0")
def indexOf(term: Any): Int = {
Utils.nonNegativeMod(getHashFunction(term), numFeatures)
}
/**
* Get the hash function corresponding to the current [[hashAlgorithm]] setting.
*/
private def getHashFunction: Any => Int = hashAlgorithm match {
case Murmur3 => murmur3Hash
case Native => nativeHash
case _ =>
// This should never happen.
throw new IllegalArgumentException(
s"HashingTF does not recognize hash algorithm $hashAlgorithm")
}
/**
* Transforms the input document into a sparse term frequency vector.
* 返回的是:Vectors.sparse(numFeatures, termFrequencies.toSeq),因为numFeatures设置为1 << 20,那么返回的是:(1048576,[每个词的hash值组成的列表(从小到大)],[对应前面单词的频率频率])
*/
@Since("1.1.0")
def transform(document: Iterable[_]): Vector = {
val termFrequencies = mutable.HashMap.empty[Int, Double]
val setTF = if (binary) (i: Int) => 1.0 else (i: Int) => termFrequencies.getOrElse(i, 0.0) + 1.0
val hashFunc: Any => Int = getHashFunction
document.foreach { term =>
val i = Utils.nonNegativeMod(hashFunc(term), numFeatures)
termFrequencies.put(i, setTF(i))
}
Vectors.sparse(numFeatures, termFrequencies.toSeq)
}
/**
* Transforms the input document into a sparse term frequency vector (Java version).
*/
@Since("1.1.0")
def transform(document: JavaIterable[_]): Vector = {
transform(document.asScala)
}
/**
* Transforms the input document to term frequency vectors.
*/
@Since("1.1.0")
def transform[D <: Iterable[_]](dataset: RDD[D]): RDD[Vector] = {
dataset.map(this.transform)
}
/**
* Transforms the input document to term frequency vectors (Java version).
*/
@Since("1.1.0")
def transform[D <: JavaIterable[_]](dataset: JavaRDD[D]): JavaRDD[Vector] = {
dataset.rdd.map(this.transform).toJavaRDD()
}
}
object HashingTF {
private[spark] val Native: String = "native"
private[spark] val Murmur3: String = "murmur3"
private val seed = 42
/**
* Calculate a hash code value for the term object using the native Scala implementation.
* This is the default hash algorithm used in Spark 1.6 and earlier.
*/
private[spark] def nativeHash(term: Any): Int = term.##
/**
* Calculate a hash code value for the term object using
* Austin Appleby's MurmurHash 3 algorithm (MurmurHash3_x86_32).
* This is the default hash algorithm used from Spark 2.0 onwards.
*/
private[spark] def murmur3Hash(term: Any): Int = {
term match {
case null => seed
case b: Boolean => hashInt(if (b) 1 else 0, seed)
case b: Byte => hashInt(b, seed)
case s: Short => hashInt(s, seed)
case i: Int => hashInt(i, seed)
case l: Long => hashLong(l, seed)
case f: Float => hashInt(java.lang.Float.floatToIntBits(f), seed)
case d: Double => hashLong(java.lang.Double.doubleToLongBits(d), seed)
case s: String =>
val utf8 = UTF8String.fromString(s)
hashUnsafeBytes(utf8.getBaseObject, utf8.getBaseOffset, utf8.numBytes(), seed)
case _ => throw new SparkException("HashingTF with murmur3 algorithm does not " +
s"support type ${term.getClass.getCanonicalName} of input data.")
}
}
}
/**
* 逆文档频率 (IDF).
* The standard formulation is used: `idf = log((m + 1) / (d(t) + 1))`, where `m` is the total
* number of documents and `d(t)` is the number of documents that contain term `t`.
*
* This implementation supports filtering out terms which do not appear in a minimum number
* of documents (controlled by the variable `minDocFreq`). For terms that are not in
* at least `minDocFreq` documents, the IDF is found as 0, resulting in TF-IDFs of 0.
*
* @param minDocFreq minimum of documents in which a term
* should appear for filtering
*/
@Since("1.1.0")
class IDF @Since("1.2.0") (@Since("1.2.0") val minDocFreq: Int) {
@Since("1.1.0")
def this() = this(0)
// TODO: Allow different IDF formulations.
/**
* 计算逆文档频率
* @param dataset an RDD of term frequency vectors
*/
@Since("1.1.0")
def fit(dataset: RDD[Vector]): IDFModel = {
val idf = dataset.treeAggregate(new IDF.DocumentFrequencyAggregator(
minDocFreq = minDocFreq))(
seqOp = (df, v) => df.add(v),
combOp = (df1, df2) => df1.merge(df2)
).idf()
new IDFModel(idf)
}
/**
* 计算逆文档频率
* @param dataset a JavaRDD of term frequency vectors
*/
@Since("1.1.0")
def fit(dataset: JavaRDD[Vector]): IDFModel = {
fit(dataset.rdd)
}
}
private object IDF {
/** 文档频率聚合. */
class DocumentFrequencyAggregator(val minDocFreq: Int) extends Serializable {
/** number of documents */
private var m = 0L
/** document frequency vector */
private var df: BDV[Long] = _
def this() = this(0)
/** 添加新文档。. */
def add(doc: Vector): this.type = {
if (isEmpty) {
df = BDV.zeros(doc.size)
}
doc match {
case SparseVector(size, indices, values) =>
val nnz = indices.length
var k = 0
while (k < nnz) {
if (values(k) > 0) {
df(indices(k)) += 1L
}
k += 1
}
case DenseVector(values) =>
val n = values.length
var j = 0
while (j < n) {
if (values(j) > 0.0) {
df(j) += 1L
}
j += 1
}
case other =>
throw new UnsupportedOperationException(
s"Only sparse and dense vectors are supported but got ${other.getClass}.")
}
m += 1L
this
}
/**合并另一个 */
def merge(other: DocumentFrequencyAggregator): this.type = {
if (!other.isEmpty) {
m += other.m
if (df == null) {
df = other.df.copy
} else {
df += other.df
}
}
this
}
private def isEmpty: Boolean = m == 0L
/** 返回当前的IDF向量 */
def idf(): Vector = {
if (isEmpty) {
throw new IllegalStateException("Haven't seen any document yet.")
}
val n = df.length
val inv = new Array[Double](n)
var j = 0
while (j < n) {
/*
* If the term is not present in the minimum
* number of documents, set IDF to 0. This
* will cause multiplication in IDFModel to
* set TF-IDF to 0.
*
* Since arrays are initialized to 0 by default,
* we just omit changing those entries.
*/
if (df(j) >= minDocFreq) {
inv(j) = math.log((m + 1.0) / (df(j) + 1.0))
}
j += 1
}
Vectors.dense(inv)
}
}
}
/**
* Represents an IDF model that can transform term frequency vectors.
*/
@Since("1.1.0")
class IDFModel private[spark] (@Since("1.1.0") val idf: Vector) extends Serializable {
/**
* 输入 词项频率向量(TF) vectors 返回 TF-IDF vectors
* 如果设置了 minDocFreq 那么词项小于minDocFreq时,那么TF-IDF值为0
* @param dataset an RDD of term frequency vectors
* @return an RDD of TF-IDF vectors
*/
@Since("1.1.0")
def transform(dataset: RDD[Vector]): RDD[Vector] = {
val bcIdf = dataset.context.broadcast(idf)
dataset.mapPartitions(iter => iter.map(v => IDFModel.transform(bcIdf.value, v)))
}
/**
* Transforms a term frequency (TF) vector to a TF-IDF vector
*
* @param v a term frequency vector
* @return a TF-IDF vector
*/
@Since("1.3.0")
def transform(v: Vector): Vector = IDFModel.transform(idf, v)
/**
* Transforms term frequency (TF) vectors to TF-IDF vectors (Java version).
* @param dataset a JavaRDD of term frequency vectors
* @return a JavaRDD of TF-IDF vectors
*/
@Since("1.1.0")
def transform(dataset: JavaRDD[Vector]): JavaRDD[Vector] = {
transform(dataset.rdd).toJavaRDD()
}
}
private object IDFModel {
/**
* Transforms a term frequency (TF) vector to a TF-IDF vector with a IDF vector
*
* @param idf an IDF vector
* @param v a term frequence vector
* @return a TF-IDF vector
*/
def transform(idf: Vector, v: Vector): Vector = {
val n = v.size
v match {
case SparseVector(size, indices, values) =>
val nnz = indices.length
val newValues = new Array[Double](nnz)
var k = 0
while (k < nnz) {
newValues(k) = values(k) * idf(indices(k))
k += 1
}
Vectors.sparse(n, indices, newValues)
case DenseVector(values) =>
val newValues = new Array[Double](n)
var j = 0
while (j < n) {
newValues(j) = values(j) * idf(j)
j += 1
}
Vectors.dense(newValues)
case other =>
throw new UnsupportedOperationException(
s"Only sparse and dense vectors are supported but got ${other.getClass}.")
}
}
}
-----------------------------------------------------------------------------------------------------------------------------
SparkML实验
(数据:链接:http://pan.baidu.com/s/1o7C5EsU 密码:v00d)
import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.mllib.feature.{HashingTF, IDF} import org.apache.spark.mllib.linalg.Vector import org.apache.spark.rdd.RDD object TFIDFExample { type Word = String type Sentence = List[String] def splitWords(content: String): List[Word] = ("[a-zA-Z]+".r findAllIn content).toList def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("TFIDFExample").setMaster("local") val sc = new SparkContext(conf) // Load documents (one per line). val documents = sc.textFile("/root/application/upload/dfIdf.data") documents.foreach(println) /*Innovation can be viewed as a adoption and dissemination of something new in a given context. E-commerce is thus an innovation when it is introduced to a new environment in an emerging market or when adopted by a new class of user industries. As a techno-managerial innovation, it requires business adaption, organizational learning, and supportive environment that could lead to wide diffusion and transformational impact. Several global forces drive the adoption of e-commerce such as global competition, trade liberalization, and increasingly, ICT advances and Internet diffusion. National factors, such as governance, education, and infrastructure, then shape and differentiate the speed of adoption across enterprises within a country, the breadth and depth of use within an enterprise, and ultimately the impact on the firm and the nation. Understanding the national environment, the policy, technological and infrastructural contexts, and the common drivers and barriers to adoption and effective use within firms should provide a guide to promoting e-commerce as a techno-managerial innovation, and realizing its full potential for the nation.*/ val parseDate = documents.map{x => splitWords(x) } parseDate.foreach(println) /*List(Innovation, can, be, viewed, as, a, adoption, and, dissemination, of, something, new, in) List(a, given, context, E, commerce, is, thus, an, innovation, when, it, is, introduced, to, a) List(new, environment, in, an, emerging, market, or, when, adopted, by, a, new, class, of) List(user, industries, As, a, techno, managerial, innovation, it, requires, business) List(adaption, organizational, learning, and, supportive, environment, that, could, lead, to) List(wide, diffusion, and, transformational, impact, Several, global, forces, drive, the) List(adoption, of, e, commerce, such, as, global, competition, trade, liberalization, and) List(increasingly, ICT, advances, and, Internet, diffusion, National, factors, such, as) List(governance, education, and, infrastructure, then, shape, and, differentiate, the) List(speed, of, adoption, across, enterprises, within, a, country, the, breadth, and, depth, of) List(use, within, an, enterprise, and, ultimately, the, impact, on, the, firm, and, the, nation) List(Understanding, the, national, environment, the, policy, technological, and) List(infrastructural, contexts, and, the, common, drivers, and, barriers, to, adoption, and) List(effective, use, within, firms, should, provide, a, guide, to, promoting, e, commerce, as, a) List(techno, managerial, innovation, and, realizing, its, full, potential, for, the, nation)*/ println("------------------------HashingTF-----------------------------") val hashingTF = new HashingTF() val tf: RDD[Vector] = hashingTF.transform(parseDate) /*(1048576,[97,3122,3139,3365,3543,96727,98256,108960,209412,297082,393027,459141,765528],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[69,97,3117,3370,3371,3707,337253,413714,472495,498469,502586,518875,849789],[1.0,2.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[97,3117,3159,3365,3543,3555,78355,108960,126031,371064,502586,824380,935664],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[97,727,2130,3371,76718,311232,337253,453579,576391,725756],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[3707,78355,96727,171868,291614,413095,479425,513446,578217,948382],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[81222,96727,114801,432522,478149,503507,590755,819444,861148,1037032],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[101,3122,3543,96727,364991,395847,438311,518875,520548,590755,765528],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[3122,72314,96727,395730,395847,478149,485425,666465,733444,883788],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[96727,114801,115010,329123,348065,413213,747432,853474],[2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[97,3543,51907,96727,114801,481174,526700,589895,765528,959595,961663,997682],[1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[3117,3551,81222,96727,114801,116103,151367,233886,471905,959595,1046078],[1.0,1.0,1.0,2.0,3.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[78355,96727,114801,763314,808708,894258,919890],[1.0,1.0,2.0,1.0,1.0,1.0,1.0]) (1048576,[3707,96727,114801,421195,765528,765613,993771,1015972,1037212],[1.0,3.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[97,101,3122,3707,116103,146172,380577,403879,518875,726451,851069,959595,971253],[2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (1048576,[727,8847,96727,101577,104616,114801,151367,245790,337253,567859,576391],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0])*/ tf.collect.foreach(println) println("a indexOf:"+hashingTF.indexOf("a"))//a indexOf:97 tf.cache() println("-------------------------tfIdf--------------------------------") val idf = new IDF().fit(tf) val tfidf: RDD[Vector] = idf.transform(tf) val idfIgnore = new IDF(minDocFreq = 2).fit(tf) val tfidfIgnore: RDD[Vector] = idfIgnore.transform(tf) println("tfidf: ") tfidf.foreach(x => println(x)) /*(1048576,[97,3122,3139,3365,3543,96727,98256,108960,209412,297082,393027,459141,765528],[0.8266785731844679,1.1631508098056809,2.0794415416798357,1.6739764335716716,1.1631508098056809,0.28768207245178085,2.0794415416798357,1.6739764335716716,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357,1.1631508098056809]) (1048576,[69,97,3117,3370,3371,3707,337253,413714,472495,498469,502586,518875,849789],[2.0794415416798357,1.6533571463689358,1.3862943611198906,4.1588830833596715,1.6739764335716716,1.1631508098056809,1.3862943611198906,2.0794415416798357,2.0794415416798357,2.0794415416798357,1.6739764335716716,1.3862943611198906,2.0794415416798357]) (1048576,[97,3117,3159,3365,3543,3555,78355,108960,126031,371064,502586,824380,935664],[0.8266785731844679,1.3862943611198906,2.0794415416798357,1.6739764335716716,1.1631508098056809,2.0794415416798357,1.3862943611198906,3.347952867143343,2.0794415416798357,2.0794415416798357,1.6739764335716716,2.0794415416798357,2.0794415416798357]) (1048576,[97,727,2130,3371,76718,311232,337253,453579,576391,725756],[0.8266785731844679,1.6739764335716716,2.0794415416798357,1.6739764335716716,2.0794415416798357,2.0794415416798357,1.3862943611198906,2.0794415416798357,1.6739764335716716,2.0794415416798357]) (1048576,[3707,78355,96727,171868,291614,413095,479425,513446,578217,948382],[1.1631508098056809,1.3862943611198906,0.28768207245178085,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357]) (1048576,[81222,96727,114801,432522,478149,503507,590755,819444,861148,1037032],[1.6739764335716716,0.28768207245178085,0.6931471805599453,2.0794415416798357,1.6739764335716716,2.0794415416798357,1.6739764335716716,2.0794415416798357,2.0794415416798357,2.0794415416798357]) (1048576,[101,3122,3543,96727,364991,395847,438311,518875,520548,590755,765528],[1.6739764335716716,1.1631508098056809,1.1631508098056809,0.28768207245178085,2.0794415416798357,1.6739764335716716,2.0794415416798357,1.3862943611198906,2.0794415416798357,1.6739764335716716,1.1631508098056809]) (1048576,[3122,72314,96727,395730,395847,478149,485425,666465,733444,883788],[1.1631508098056809,2.0794415416798357,0.28768207245178085,2.0794415416798357,1.6739764335716716,1.6739764335716716,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357]) (1048576,[96727,114801,115010,329123,348065,413213,747432,853474],[0.5753641449035617,0.6931471805599453,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357]) (1048576,[97,3543,51907,96727,114801,481174,526700,589895,765528,959595,961663,997682],[0.8266785731844679,2.3263016196113617,2.0794415416798357,0.28768207245178085,0.6931471805599453,2.0794415416798357,2.0794415416798357,2.0794415416798357,1.1631508098056809,1.3862943611198906,2.0794415416798357,2.0794415416798357]) (1048576,[3117,3551,81222,96727,114801,116103,151367,233886,471905,959595,1046078],[1.3862943611198906,2.0794415416798357,1.6739764335716716,0.5753641449035617,2.0794415416798357,1.6739764335716716,1.6739764335716716,2.0794415416798357,2.0794415416798357,1.3862943611198906,2.0794415416798357]) (1048576,[78355,96727,114801,763314,808708,894258,919890],[1.3862943611198906,0.28768207245178085,1.3862943611198906,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357]) (1048576,[3707,96727,114801,421195,765528,765613,993771,1015972,1037212],[1.1631508098056809,0.8630462173553426,0.6931471805599453,2.0794415416798357,1.1631508098056809,2.0794415416798357,2.0794415416798357,2.0794415416798357,2.0794415416798357]) (1048576,[97,101,3122,3707,116103,146172,380577,403879,518875,726451,851069,959595,971253],[1.6533571463689358,1.6739764335716716,1.1631508098056809,1.1631508098056809,1.6739764335716716,2.0794415416798357,2.0794415416798357,2.0794415416798357,1.3862943611198906,2.0794415416798357,2.0794415416798357,1.3862943611198906,2.0794415416798357]) (1048576,[727,8847,96727,101577,104616,114801,151367,245790,337253,567859,576391],[1.6739764335716716,2.0794415416798357,0.28768207245178085,2.0794415416798357,2.0794415416798357,0.6931471805599453,1.6739764335716716,2.0794415416798357,1.3862943611198906,2.0794415416798357,1.6739764335716716]) */ println("tfidfIgnore: ") tfidfIgnore.foreach(x => println(x)) /*(1048576,[97,3122,3139,3365,3543,96727,98256,108960,209412,297082,393027,459141,765528],[0.8266785731844679,1.1631508098056809,0.0,1.6739764335716716,1.1631508098056809,0.28768207245178085,0.0,1.6739764335716716,0.0,0.0,0.0,0.0,1.1631508098056809]) (1048576,[69,97,3117,3370,3371,3707,337253,413714,472495,498469,502586,518875,849789],[0.0,1.6533571463689358,1.3862943611198906,0.0,1.6739764335716716,1.1631508098056809,1.3862943611198906,0.0,0.0,0.0,1.6739764335716716,1.3862943611198906,0.0]) (1048576,[97,3117,3159,3365,3543,3555,78355,108960,126031,371064,502586,824380,935664],[0.8266785731844679,1.3862943611198906,0.0,1.6739764335716716,1.1631508098056809,0.0,1.3862943611198906,3.347952867143343,0.0,0.0,1.6739764335716716,0.0,0.0]) (1048576,[97,727,2130,3371,76718,311232,337253,453579,576391,725756],[0.8266785731844679,1.6739764335716716,0.0,1.6739764335716716,0.0,0.0,1.3862943611198906,0.0,1.6739764335716716,0.0]) (1048576,[3707,78355,96727,171868,291614,413095,479425,513446,578217,948382],[1.1631508098056809,1.3862943611198906,0.28768207245178085,0.0,0.0,0.0,0.0,0.0,0.0,0.0]) (1048576,[81222,96727,114801,432522,478149,503507,590755,819444,861148,1037032],[1.6739764335716716,0.28768207245178085,0.6931471805599453,0.0,1.6739764335716716,0.0,1.6739764335716716,0.0,0.0,0.0]) (1048576,[101,3122,3543,96727,364991,395847,438311,518875,520548,590755,765528],[1.6739764335716716,1.1631508098056809,1.1631508098056809,0.28768207245178085,0.0,1.6739764335716716,0.0,1.3862943611198906,0.0,1.6739764335716716,1.1631508098056809]) (1048576,[3122,72314,96727,395730,395847,478149,485425,666465,733444,883788],[1.1631508098056809,0.0,0.28768207245178085,0.0,1.6739764335716716,1.6739764335716716,0.0,0.0,0.0,0.0]) (1048576,[96727,114801,115010,329123,348065,413213,747432,853474],[0.5753641449035617,0.6931471805599453,0.0,0.0,0.0,0.0,0.0,0.0]) (1048576,[97,3543,51907,96727,114801,481174,526700,589895,765528,959595,961663,997682],[0.8266785731844679,2.3263016196113617,0.0,0.28768207245178085,0.6931471805599453,0.0,0.0,0.0,1.1631508098056809,1.3862943611198906,0.0,0.0]) (1048576,[3117,3551,81222,96727,114801,116103,151367,233886,471905,959595,1046078],[1.3862943611198906,0.0,1.6739764335716716,0.5753641449035617,2.0794415416798357,1.6739764335716716,1.6739764335716716,0.0,0.0,1.3862943611198906,0.0])16/06/05 19:25:10 INFO Executor: Finished task 0.0 in stage 6.0 (TID 6). 2044 bytes result sent to driver (1048576,[78355,96727,114801,763314,808708,894258,919890],[1.3862943611198906,0.28768207245178085,1.3862943611198906,0.0,0.0,0.0,0.0]) (1048576,[3707,96727,114801,421195,765528,765613,993771,1015972,1037212],[1.1631508098056809,0.8630462173553426,0.6931471805599453,0.0,1.1631508098056809,0.0,0.0,0.0,0.0]) (1048576,[97,101,3122,3707,116103,146172,380577,403879,518875,726451,851069,959595,971253],[1.6533571463689358,1.6739764335716716,1.1631508098056809,1.1631508098056809,1.6739764335716716,0.0,0.0,0.0,1.3862943611198906,0.0,0.0,1.3862943611198906,0.0]) (1048576,[727,8847,96727,101577,104616,114801,151367,245790,337253,567859,576391],[1.6739764335716716,0.0,0.28768207245178085,0.0,0.0,0.6931471805599453,1.6739764335716716,0.0,1.3862943611198906,0.0,1.6739764335716716]) */ sc.stop() } }
参考文献
http://www.sandia.gov/~tgkolda/pubs/pubfiles/ornl-tm-13756.pdf