内置函数 & UDF函数在Hive中的使用
在本篇博文中,将对Hive中的内置函数和UDF函数的使用,进行简要介绍,并进行实际操作验证
Hive内置函数的使用
函数在Hive中使用的常用命令
- 网址:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF - UDF:User-Defined Functions
- Build-in
查看hive中支持的函数:
hive>show functions;查看substr函数如何进行使用:
hive>desc function substr;显示的内容:

使用substr函数进行测试 从第一位开始截取两位 注意点:有些index从0开始,该函数从1开始
hive>select job,substr(job,1,2) from emp; 
更详细的查看函数的说明(工作中建议这样使用)
hive>desc function extended substr;
抛出问题
控制台上的这些使用的注释是哪里来的?
如何在开发自定义函数的时候,展示出这些注释呢?
将在后续章节中进行介绍
大小写转换
hive>select ename, upper(ename),lower(ename) from emp;
重点:必须要知道Hive中有哪些内置函数以及如何使用?要学会自己去查阅!
Hive中Date Function的使用
hive>select to_date(from_unixtime(unix_timestamp())) from emp limit 1;打印结果:

hive>select from_unixtime(unix_timestamp()) from emp limit 1;
打印结果:

cast的使用
cast(value as TYPE) 将一个value转换成其它的类型
Type Conversion Functions (类型转换函数)
官网解释:
Converts the results of the expression expr to .
For example, cast('1' as BIGINT) will convert the string '1' to its integral representation.
A null is returned if the conversion does not succeed.
If cast(expr as boolean) Hive returns true for a non-empty string. 使用cast函数,将double类型转换为int类型
hive>select empno,ename,comm,cast(comm as int) from emp;
转换失败,返回值为null
hive>select empno,ename,comm,cast(ename as int) from emp;
string类型不能转换为int类型,转换失败,因此全为null
实际开发中可能会遇到的坑:
- binary ==> int
binary类型的转换,这样直接转是不行的,只支持转成string - binary ==> string ==> int
binary类型的转换,想转成int,只能先转成string类型,再转成int类型
Hive wiki中未提及的函数的使用
官方wiki没有提到的,但是实际工作中常会用到的函数:
- isnull
- isnotnull
- assert_true
- current_database
测试:
isnull和isnotnull
hive>select ename, comm, isnull(comm), isnotnull(comm) from emp; 
assert_true
assert_true函数判断()内的语句 对于这一批次的数据 是否全是正确的;
这里会执行failed,因为数据有null也有非null的
hive>select assert_true(comm is null) from emp;
current_database
current_database()函数 查看当前的数据库是什么
hvie>select current_database();Hive中参数设置
Hive常用的配置信息网址:
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
hive.cli.print.current.db
可以设置参数,打印出当前数据库的名称(始终显示)
该参数可以在hive-site.xml里面配置,这样就是永久有效了
hive>set hive.cli.print.current.db=true; hive.cli.print.header
可以通过设置参数:
hive>set hive.cli.print.header=true;效果:

从而每次在控制台显示的时候,都会带有每个表的字段信息 建议打开,工作中有帮助
Hive中UDF函数概述以及IDEA开发环境搭建
这部分内容,参见博客:将自定义函数集成到Hive的源码
Hive UDF开发及服务器测试
建议
Hive UDF的开发可以参考这骗文章:将自定义函数集成到Hive的源码,本文中的所有测试代码全来自于这篇文章
入参和出参的类型建议使用Hadoop的类型,比如说:Text
参考网址
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-Create/Drop/ReloadFunction
UDF使用方式
- Temporary Function(临时函数)
语法结构:
Create Temporary Function
CREATE TEMPORARY FUNCTION function_name AS class_name; 将包添加到当前环境
hive>add jar /opt/lib/hive-train-1.0.jar;
创建一个临时函数
hive>CREATE TEMPORARY FUNCTION sayHello AS 'com.zhaotao.bigdata.hive.HelloUDF'; 测试:
hive>show functions;
hive>desc function sayHello;
hive>select ename,sayHello(ename) from emp;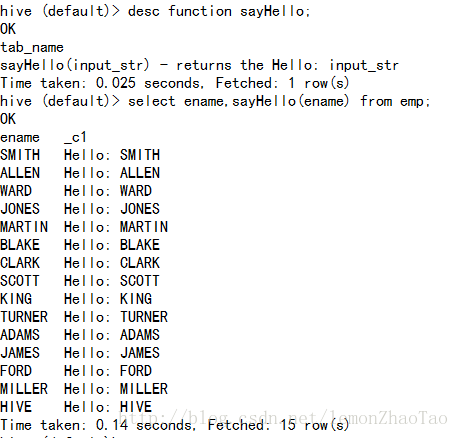
在另外一个窗口,再度启动一个hive,会发现sayHello找不到
对比图:


原因:
TEMPORARY FUNCTION 的生命周期:当前session
可以使用命令查看jar包:
hive-train-1.0.jar 是放在分布式缓存里的
hive>list jars;- 使用auxlib目录
在hive-1.1.0-cdh5.7.0的目录下,创建auxlib目录:
用于存放UDF的一些jar包,使用这种方式之后,就不用再add jar了 因为hive自动会加进来
$>mkdir auxlib
$>cd auxlib
$>cp /opt/lib/hive-train-1.0.jar .
hive>CREATE TEMPORARY FUNCTION sayHello AS 'com.zhaotao.bigdata.hive.HelloUDF';效果:

但是生命周期也仅仅只是当前session,与Temporary Function演示的效果一样
- Permanent Functions(永久函数)
语法结构:
CREATE FUNCTION [db_name.]function_name AS class_name
USING JAR|FILE|ARCHIVE 'file_uri' [, JAR|FILE|ARCHIVE 'file_uri'] ]; 官网说明:
In Hive 0.13 or later, functions can be registered to the metastore,
so they can be referenced in a query without having to create a temporary function each session.可以从官网中的说明中,发现使用Permanent Functions 函数会被注册到metastore中去
jar包存放在hdfs上,从hdfs中读取jar包:
hive>CREATE FUNCTION sayHello AS 'com.zhaotao.bigdata.hive.HelloUDF'
USING JAR 'hdfs://hadoop003:8020/lib/hive-train-1.0.jar';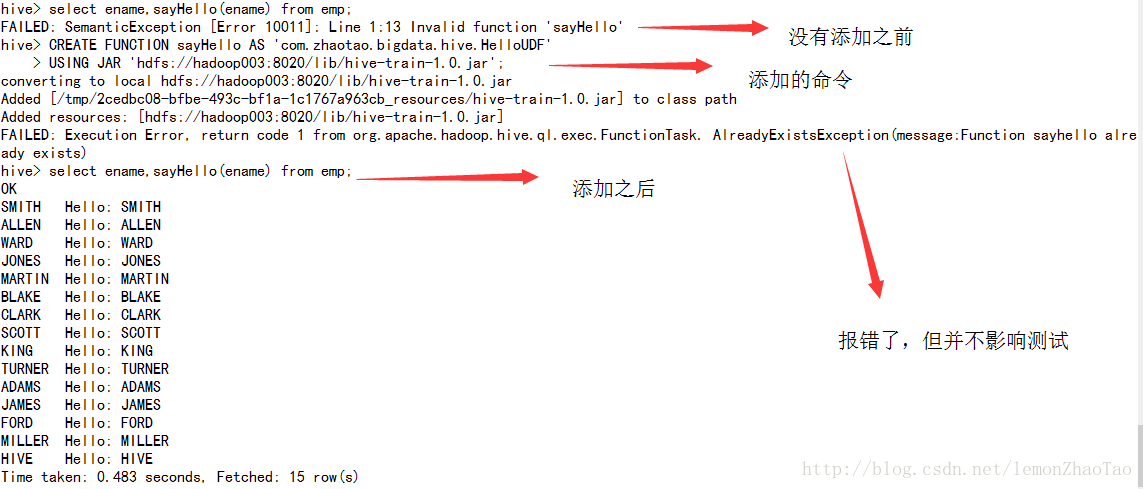
测试:
$>mysql;
mysql>use zhaotao_hive;
查看UDF 永久函数,在mysql上的元数据信息
mysql>select * from FUNCS \G; 
Hive中函数注释的开发及使用
具体参见这篇博客将自定义函数集成到Hive的源码