k-d树+bbf算法的介绍与实现
最近还是一直在研究SIFT算法,而SIFT特征点匹配是一个比较经典的问题,使用暴力匹配的话确实可以得到结果,但是运行速度较慢。我的计算机处理是i5的二代系列,匹配两张各检测有2000+个SIFT特征点的图像,通过正反匹配(即取图像1与图像2的匹配结果余图像2和图像1的匹配结果的交集),再加上OpenMP多线程加速,使用暴力匹配,大概要花20多秒,还是比较慢的。所以这一周啥也没做,一直在实现kd树和对应的bbf算法。下面详细介绍下种数据结构。
一、k-d树的介绍与实现
1.1 k-d树的创建
k-d树其实就是一种树形的数据结构,但是在创建这棵树时有一些固定的规则。下面来讲一下kd树的创建过程
输入:一组数据点集,n个数据点,每个点有m维
输出:k-d树的根结点指针
过程:(1)分别计算这n个数据点在m维中各个维度的方差,取方差最大的维度dim作为分割维度;
(2)把数据点集按照该维度中值的大小进行排列,选择具有中间值的点作为该树的根结点;
(3)前半部分点进行如(1)、(2)所示的递归操作,选出的递归子树的根节点作为(2)中得到的根节点的左孩子;
同理,后半部分也这样操作。如此一直递归,直到各个递归子树的数据点集为空则算法截止。
例子:以2维平面上的点集为例,设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}。
(1) 首先计算这6个点的横坐标和纵坐标的方差值,横坐标的方差值为39,纵坐标上的方差值为28.63,因此第一次分割取横坐标上的值作为分割标准。把这些点按照横坐标进行排序得到{(2,3),(4,7),(5,4),(7,2),(8,1),(9,6)},取中间点为(7,2),因此根节点为(7,2)进行分割,如下图所示:

图1 分割示意图
(2)接下来对{(2,3),(4,7),(5,4)}和{(8,1),(9,6)}分别进行分割,在{(2,3),(4,7),(5,4)}中纵坐标的方差较大,因此按纵坐标进行排序后分割,则(5,4)为(7,2)的左孩子,{(8,1),(9,6)}中也是纵坐标方差较大,因此选纵坐标进行排序后分割,这里算则(9,6)作为(7,2)的右孩子。
(3)依次递归进行分割,最终形成的分割图和树状结构如下所示:

图2 上例中形成的分割图
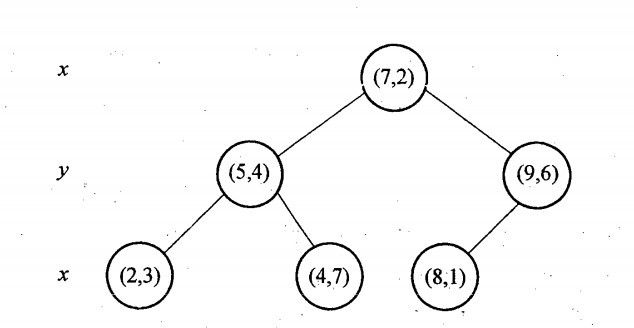
图3 上例中形成的树状结构
1.2 k-d树的查询
k-d树建立好以后,需要查询它的最近邻,方法如下:
(1)查询点与k-d树的根节点进行比较,比较两者在根节点划分时的维度的值的大小,若查询点在该维的值小,则进入根节点的左子树,否则进入右子树。依次类推,进行查找,直到到达树的叶子节点。
(2)设当前到达的叶子节点为目前的最近邻(注意:可能并非真正的最近邻),并且记录目前的最近邻距离。沿着来时的路向前回溯,让目前的最近邻距离与查找点与当前叶子节点的父节点形成的分割超平面的距离进行比较,若当前最近邻比较小,则不用遍历当前叶子节点的父节点的另一边,否则需要遍历查找以更新最近邻距离和最近邻节点。
(3)按照(2)中所说依次遍历,直到到达根节点为止,查询结束。
上面的说法比较抽象,下面用两个博客中广为流传的例子进行解读。
假设我们需要查找点(2.1,3.1)在前面中提到的二维点集中的最近邻点。我们首先判断(7,2)的分割标准是x轴,而2.1<7,因此查找点进入(7,2)的左子树;而(5,4)的分割标准是y轴,而3.1<4,因此我们进入(5,4)的左子树,即找到叶子节点(2,3);把(2,3)作为查找点(2.1,3.1)的临时最近邻点,最近邻距离为0.1414,向前回溯。
因为查找点到(5,4)的距离大于到(2,3)的距离,因此最近邻点和最近邻距离保持不变,因此以(2.1,3.1)为原点,以0.1414为半径画圆,该圆与(5,4)确定的分割线没有相交(即当前最近邻距离比查找点到(5,4)所确定的分割线距离要小),因此不需要进入(5,4)的右子树,继续回溯,同理,最近邻点和最近邻距离不变,以(2.1,3.1)为原点,以0.1414为半径画圆,该圆与(7,2)所确定的分割线也没有相交,因此也不需要进入(7,2)的右子树;回溯结束。因此(2,3)就是真正的最近邻节点。
如下图所示:

图4 (2.1,3.1)查询最近邻示意图
上面这个例子比较简单,下面我们看一个复杂一些的例子,假设我们要查找(2,4.5)的最近邻。
同上,首先我们判断(7,2)的分割标准是x周,而2<7,因此到(7,2)的左孩子进行查找,而(5,4)的分割标准为y轴,而4.5>4因此3.041,因此需要到(5,4)的右孩子进行查找,找到了叶子节点(4,7)。那么我们把(4,7)作为查找点的临时最近邻,最近邻距离为3.202,向前回溯,可以看到到(5,4)的距离为3.041,因此更新(5,4)为最近邻点,最近邻距离为3.041。然后以(2,4.5)为圆心,以3.041为半径画圆,可以看到该圆与(5,4)确定的分割线相交,因此需要遍历(5,4)的左子树。如下图所示:
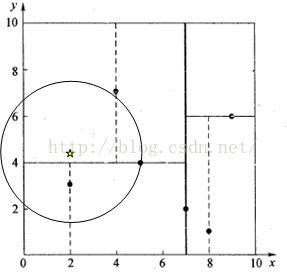
判断(2,4.5)到(2,3)的距离为1.5,因此更新最近邻点和最近邻距离。回溯到(7,2),可以判断不需到(7,2)的右子树进行查找,如下图所示:

1.3 代码实现
class kdNode
{
public:
kdNode(Point &data);
~kdNode();
Point data;//数据点的信息
int sort_dim;//数据点的划分维度
kdNode *left;
kdNode *right;
kdNode *parent;
};//创建kd树,keypoints为点数据,parent表示当前树的双亲,默认为NULL
kdNode* kdTree::createTree(vector &keypoints, kdNode *parent)
{
if (keypoints.size() == 0)//若数据点集为空,则停止创建
return NULL;
int sort_dim = findSortDim(keypoints, parent);//确定分割的维度
kdNode *tmp = findMidNode(keypoints);//找到分割结点
int sort_num = keypoints.size() / 2;
vector leftKeyPoints(keypoints.begin(), keypoints.begin() + sort_num);
vector rightKeyPoints(keypoints.begin() + sort_num + 1, keypoints.end());
tmp->sort_dim = sort_dim;//记录当前结点的分割维度
tmp->left = createTree(leftKeyPoints, tmp);//递归调用,创建左子树
tmp->right = createTree(rightKeyPoints, tmp);//递归调用,创建右子树
tmp->parent = parent;//记录父节点
return tmp;//返回当前树的根节点
} //通过kd树查找距离指定点node最近的点
//root是查找的kd树的根节点
//point是查找点
nearestNodeInfo& kdTree::findNearestNode(kdNode* root, const Point& point)
{
if (root == NULL)
{
return nearestNodeInfo();
}
kdNode *p = root;
//通过kd树的二叉搜索,顺着搜索路径很快就能找到最邻近的近似点
while ((p->left != NULL) || (p->right != NULL))//只要p不是指向叶节点
{
int sort_dim = p->sort_dim;
if (point.data[sort_dim] <= p->data.data[sort_dim])
{
if (p->left == NULL)
break;
p = p->left;
}
else
{
if (p->right == NULL)
break;
p = p->right;
}
}
float min_dis = FLT_MAX;//距离查找点最近的距离
float secmin_dis = FLT_MAX;//距离查找点的次近邻距离
int min_subscript = 0;
min_dis = calcDistance(point, p->data);//计算查找点与近似邻近叶子节点的距离
min_subscript = p->data.subscript;//记录最近邻结点在数据点集中的下标,以便以后找到它
kdNode* q = p;
kdNode* tmp = q;
//开始回溯
while (q != root)
{
q = tmp->parent;
//当前结点距离查找点的距离
float tmp_dis = calcDistance(point, q->data);
//当tmp_dis小于最近邻距离时,更新最近邻和次近邻
if (tmp_dis < min_dis)
{
secmin_dis = min_dis;
min_dis = tmp_dis;
min_subscript = q->data.subscript;
}
//当tmp_dis大于等于最近邻且小于次近邻时,更新次近邻
else if (tmp_dis == min_dis || tmp_dis < secmin_dis)
{
secmin_dis = tmp_dis;
}
//查找点距离当前结点构成的区域分割线的垂直距离
float sortdim_dis = std::fabs(point.data[q->sort_dim] - q->data.data[q->sort_dim]);
//若垂直距离小于距离当前结点的距离
//则证明以查找点为中心,以到当前结点距离为半径画圆,会与该结点构成的区域分割线相交
if (sortdim_dis < min_dis)
{
nearestNodeInfo tmpResult;
if (tmp == q->left)
{
tmpResult = findNearestNode(q->right, point);
}
else if (tmp == q->right)
{
tmpResult = findNearestNode(q->left, point);
}
else
cout << "q is not parent of tmp" << endl;
//tmpDis为查找点距离当前结点的另一边的子树的最小距离
float tmp_nearest_dis = tmpResult.nearest_dis;
float tmp_sec_nearest_dis = tmpResult.sec_nearest_dis;
//当子树中距离查找点的最小距离小于当前记录的最邻近距离时,更新最近邻和次近邻距离
if (tmp_nearest_dis < min_dis)
{
secmin_dis = min_dis;
min_dis = tmp_nearest_dis;
min_subscript = tmpResult.point_subscript;
}
//当子树中距离查找点的最小距离在最近邻和次近邻距离之间时,更新次近邻距离
else if (tmp_nearest_dis == min_dis || tmp_nearest_dis < secmin_dis)
secmin_dis = tmp_nearest_dis;
//当子树中距离查找点的次近邻距离小于更新后的次近邻距离时,再次更新
if (tmp_sec_nearest_dis < secmin_dis)
secmin_dis = tmp_sec_nearest_dis;
}
tmp = q;
}
nearestNodeInfo result(min_dis, secmin_dis, min_subscript);
return result;
}前面讲到了用k-d树对于高维的数据进行最邻近查询时实际上效率并不高,这里介绍一个算法用以加速k-d树对于高维数据的处理。
二、bbf(Best Bin First)算法介绍与实现
nearestNodeInfo& kdTree::findNearestNode_bbf(kdNode* root, const Point& point)
{
if (root == NULL)
return nearestNodeInfo();
kdNode *p = root;
float min_dis = FLT_MAX;//最近邻距离
float sec_min_dis = FLT_MAX;//次近邻距离
int min_subscript = 0;//最近邻点在点集中的下标
//优先级队列,查找点到当前点确定的分割超平面距离越小优先级越大
priority_queue pri_queue;
//priorityInfo类型包含了如下信息:
//(1)当前的结点指针,指向kdNode类型
//(2)当前点到查找点的欧式距离
//(3)以及查找点到当前点确定的分割超平面的距离
pri_queue.push(priorityInfo(p,calcDistance(point,root->data),
fabs(point.data[root->sort_dim]-root->data.data[root->sort_dim])));
int t = 0;//这里没有记录时间,使用t记录尝试更新最近邻的次数
while (!pri_queue.empty())
{
t++;
priorityInfo tmp = pri_queue.top();
pri_queue.pop();
int sort_dim = tmp.ptr->sort_dim;
//如果最近邻距离小于查找点到当前点确定的分割超平面的距离则不访问该点的分支
if (min_dis < fabs(point.data[sort_dim] - tmp.ptr->data.data[sort_dim]))
continue;
//记录当前点到查找点的欧式距离
float tmp_dis = calcDistance(point, tmp.ptr->data);
//判断是否更新最近邻、次近邻距离
if (tmp_dis < min_dis)
{
sec_min_dis = min_dis;
min_dis = tmp_dis;
min_subscript = tmp.ptr->data.subscript;
}
else if (tmp_dis == min_dis || tmp_dis < sec_min_dis)
{
sec_min_dis = tmp_dis;
}
kdNode* q = tmp.ptr;
//遍历以当前点为根的子树,直到叶子节点
while (q->right != NULL || q->left != NULL)
{
t++;
int s_d = q->sort_dim;
if (point.data[s_d] <= q->data.data[s_d])//查找点在分割维的大小小于当前点分割维的大小
{
if (q->left != NULL)//进入左孩子之前判断左孩子是否为空
{
if (q->right != NULL)//把右孩子加入节点时判断右孩子是否为空
{
float distance = calcDistance(point, q->right->data);
int s_t = q->right->sort_dim;
pri_queue.push(priorityInfo(q->right, distance,
fabs(point.data[s_t]-q->right->data.data[s_t])));
}
q = q->left;
}
else
break;
}
else
{
if (q->right != NULL)
{
if (q->left != NULL)
{
float distance = calcDistance(point, q->left->data);
int s_t = q->left->sort_dim;
pri_queue.push(priorityInfo(q->left, distance,
fabs(point.data[s_t]-q->left->data.data[s_t])));
}
q = q->right;
}
else
break;
}
//更新最近邻
float dis = calcDistance(point, q->data);
if (dis < min_dis)
{
sec_min_dis = min_dis;
min_dis = dis;
min_subscript = q->data.subscript;
}
else if (dis == min_dis || dis < sec_min_dis)
sec_min_dis = dis;
}
if (t > 600)//如果更新次数超过600次则直接退出循环,返回当前最近邻结果
break;
}
nearestNodeInfo result(min_dis, sec_min_dis, min_subscript);
return result;
}