深度网络模型压缩 - CNN Compression
一. 技术背景
一般情况下,CNN网络的深度和效果成正比,网络参数越多,准确度越高,基于这个假设,ResNet50(152)极大提升了CNN的效果,但inference的计算量也变得很大。这种网络很难跑在前端移动设备上,除非网络变得简洁高效。
基于这个假设,有很多处理方法,设计层数更少的网络、更少的卷积和、每个参数占更少的字节,等等。
前面讲过的 PVANet、MobileNet、ShuffleNet 是网络设计层面的思路,这里我们不展开,本节主要讲的是基于 已训练网络的简化方法。
首先来看网络压缩的经典文献,ICLR 2016 的Best Paper,来自 Song Han 大神的 Deep Compression:
论文下载:Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman coding
这篇文章必须要读一遍,先看示意图:
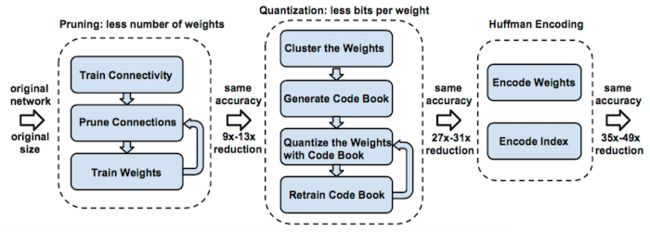
作者提出从三个方面进行网络压缩:
1)Pruning
最常用的剪枝方法,即剔除对于网络贡献比较低的权值连接,这个比较好理解,通过Pruning使得网络变得稀疏,带来更少的计算量。
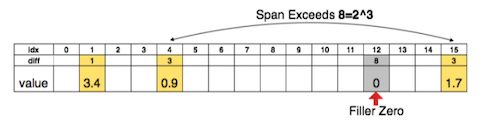
上图是基于稀疏矩阵的索引表示,用3bits 来表示索引的相对位置,其中黄色部分为有效权值区域,当相对位置的diff 超过8(3bits)的时候,中间插入了一个0权值来防止溢出。
事实上,稀疏矩阵对于计算量来讲并没有太多的效率优化,远不如将整个的卷积和剔除来得更实在,这也是 Pruning 接下来聚焦的方向。
2)Quantization
量化,包括两个方向:
a)通过聚类的方式实现权值共享;
这种方法误差很大,后续研究的也并不是很多,知道下就好了。
b)采用更少的字节表示权值,比如 16bit、8bit;
这里面还有 著名的 BinaryNet,XNOR-Net,不过对于效果影响比较大,我最多能接受 int8 所以没怎么看,当然大家有兴趣可以看一下。
3)Huffman 编码
通过对权值、索引进行编码,减少字节占用;
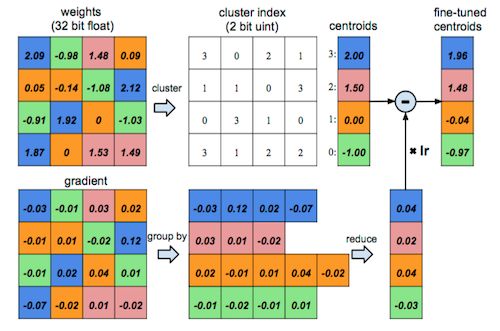
其中 (2)(3) 对系统的优化主要聚焦在节约内存占用,我对这方面兴趣不是很大,下面可能会不怎么涉及。
二. 进一步改进
估计是被 Deep Compression 打了鸡血,ICLR 2017 大家都搞模型压缩,没办法,发顶会的诱惑太大(偷偷说一句,俺也想),大部分的思路都是基于这篇文章的改进,这里面有几篇文章还是值得看一下的:
- Pruning
Pruning Convolutional Neural Networks for Resource Efficient Inference
Faster CNNs with Direct Sparse Convolutions and Guided Pruning
- Quantization
Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights
Towards the Limit of Network Quantization
先来看下第一篇文章,来自 NVidia 的迭代 Pruning 的方法。
>> NVIDIA: Iteration Pruning
该方法的核心思路:
1)基于Kernel Filter进行 Pruning,不考虑更细的Weight 层面;
文中给出了原因,Weight 层面的 Pruning 能减少计算量,但稀疏的卷积核并不能带来效率的提升(缺少专用硬件)。
2)迭代删除 Least important Kernel,并进行 FineTuning;
3)提供了一个 Pruning 的准则;
通过目标函数来说明 Pruning 的目标:
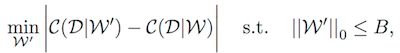
这个公式描述的是 从权值序列W中 选择一个子集W‘,该子集对应的 Cost与初始序列W最为接近。当然最后添加了一个 subject to,个数不超过B。
完整的 Pruning 过程可以描述为(NVIDIA 标准的颜色,流程图都不例外,呵呵了):
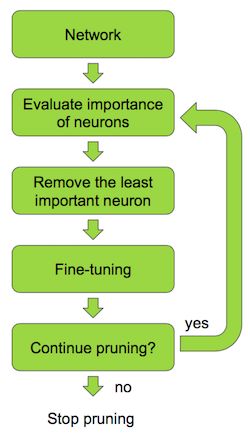
可以看到,这里面只有一个关键点,那就是 找出最不重要的那个 Neuron,其他都是浮云,那么如何评估重要性呢?
1)Minimum weights
删除权值最小的,这是最常用的一种判断依据,这样做的假设是 权值小的 conv kernel 检测 less important features。
可以对应公式中的 w、b,需要借助一个 L2 正则化处理:
2)Activation
统计激活层结果(对应上面公式 Z),通常采用均值或者标准差来进行描述:
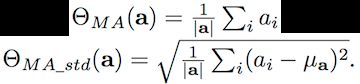
对应激活值 (输出特征图) 越小,对于Predict 来讲 特征检测器越没什么用。
3)Mutual information
互信息是指一个变量中包含的另一个变量的信息量,可以看作是两个变量相互依赖的程度,文中通过信息增益表示为:
4)Taylor expansion
将 Pruning 描述为一个优化问题,Pruning前后Cost的差异可以描述为:
hi=0 表示 pruning 后的 Cost,通过引入泰勒展开,
去掉高阶项(ReLU激活层包含了高阶信息,同时规避复杂的计算),并代入上面公式,得到:
将特征图看作 变量的向量表示,M个变量可以描述为:
5)Relation To optimal Brain Damage
与原始的OBD相比,作者做了一些改进,在训练后期梯度趋近于0的情况下,变化贡献量比较小,在这种情况下,OBD采用的是二阶泰勒展开,或者是简化的对角Hessian矩阵。文中采用了近似的方式,直接用 |y| 来代替,并进行了效率对比,对这块感兴趣的可以再细看下原文。
6)Average Percentage of Zeros(APoZ)
由于 ReLU 提供了负激活(变为0值),对于一个特征图来讲,非0值的比例可以衡量该特征图的重要性,这是显而易见的。
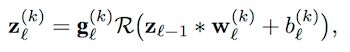
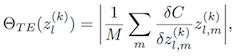
除了度量标准,接下来就是归一化,作者提出了两种归一化处理,不同层参数的 L2-norm 和 FLOPs正则化。
实验结果:
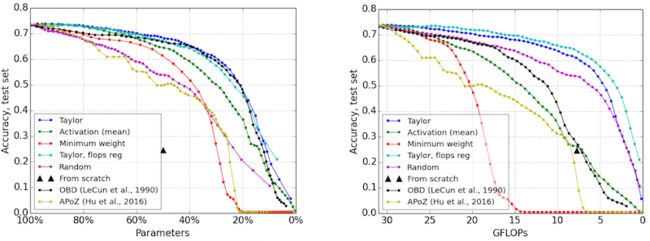
不同评估标准对于 Pruning 精度的影响曲线(基于VGG16网络 & Birds-200数据集):
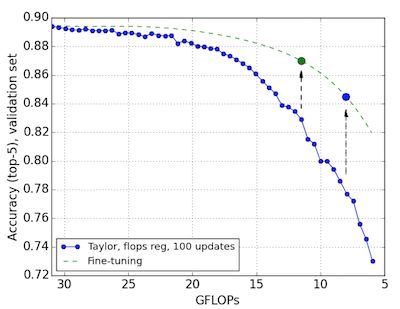
基于 ImageNet 的 Pruning:
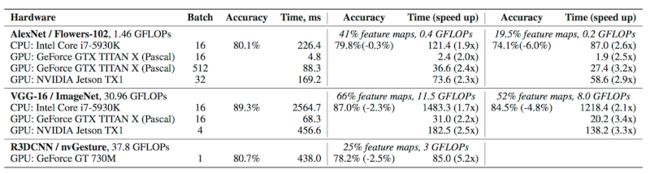
基于 FLOPs 度量,Pruning 对于精度的影响统计表格:
>> Intel: Direct Sparse Conv
Conv 层对于CNN网络的效率影响很大,与前面 Pruning 整个 Kernel 的方法不同,这篇文章主要是 Pruning 连接。
核心思想是 通过一种乘法(向量展开),实现 Dense Matrix(特征) 和 Sparse Matrix(Kernel) 之间的高效计算。同时提出了一种评价模型,预测不同网络下 稀疏程度的最佳值。
作者在 AlexNet上进行Conv层压缩,获得了3.1~7.3倍的加速。
代码下载:【Github】
先来看架构图:
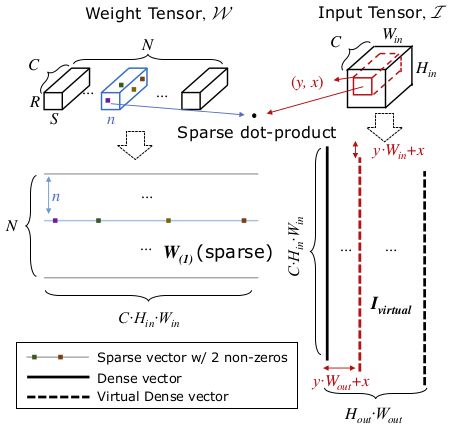
原理比较简单,即把每个 Kernel 展开成一个 Sparse 向量 W(对应左边一行),把 Feature 合并展开成一个列向量(右边列),少说话,多上图:
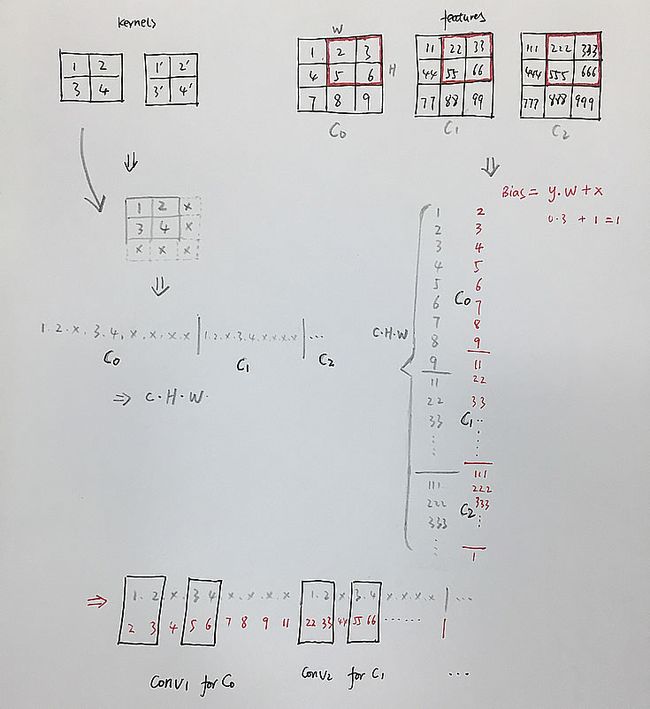
展开成列向量乘法,就是这么简单,在 NVIDIA 显卡上为了加速计算,都是这么做的。
- 评价模型
先看公式:
![]()
> 其中 C为原始 Kernel FLOP的数量,F为设备的 FLOP数量, t(dense) 为 dense 状态下的比例参数。
> α为稀疏表示带来的额外计算开销,x为非0元素的密度,t(sparse_compute) 表示稀疏卷积的时间开销。
> SA表示 Feature(Activation)的size,Sw表示权值 w的size,β表示稀疏表示带来的额外的存储开销。
B表示内存带宽,t(sparse_bw)表示稀疏卷积用band width来衡量的时间开销。
作者发现 α=3,β=2 在 Xeon E5-2697 v4 上比较合适。
一般情况下,存在一个有效的稀疏上界,上界可通过解 t(sparse_compute)= t(sparse_bw)得到,在 AlexNet on Xeon 的上界为x=0.02。也有一个稀疏下界,稀疏度太低速度并不一定快,当x>1/α时,t((sparse_compute) > t(dense)。
- GSL
Guided Sparsity Learning,如何引导?比如第一层作为浅层信息提取,比较重要,这种情况下一般很少Pruning。
GSL 通过每个元素的正则化进行 Pruning,描述为 Guided Element-wise Sparsity Learning (GESL),相对于岭回归和LASSO回归,GSL可以应用于更复杂的正则化。
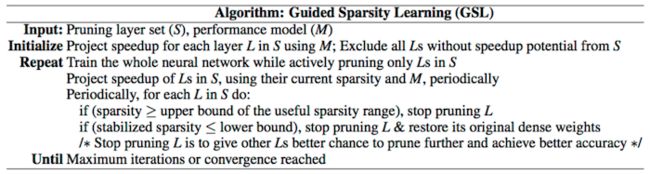
虽然GSL主要定位于推理加速,但能够对推理速度、精确度和模型尺寸 进行平衡,要做到这一点,可以有选择的为GSL设置一些约束,以便优先 pruning 网络的不同层,比如对conv层和FC层设置不同的正则化强度,在速度和模型尺寸的优先级上进行微调。
- 实验结果
基于 AlexNet 和 GoogLetNet, Layer-by-layer sparsity from element-wise sparsity learning (ESL),guided ESL, dynamic network surgery (DNS), guided DNS, and structured sparsity learning (SSL). The accuracies shown in percentage are top-1 accuracy measured with the ImageNet test set.
