ABCNN基于注意力的卷积神经网络用于句子建模--模型介绍篇
本文是Wenpeng Yin写的论文“ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs”的阅读笔记。其实该作者之前还发过一篇“Convolution Neural Network for Paraphrase Identification”。ABCNN是基于之前发的这篇论文加入了注意力机制。说到基于注意力的CNN,我们之前介绍过一篇Multi-Perspective CNN的论文。该论文也是在别的论文的基础上加入了注意力机制,但其实Attentin机制一般用于RNN模型会有比较好的效果,CNN的话也可以用==
相比这两篇Attention-based的论文,会发现,ABCNN提出了三个层面的Attention方法,有助于更加全面的理解attention在不同层面所能带来的不同作用。下面我们就来介绍一下该论文的模型。
BCNN
BCNN就是ABCNN模型的基础,即没有添加Attention的模型结构。如下图所示:
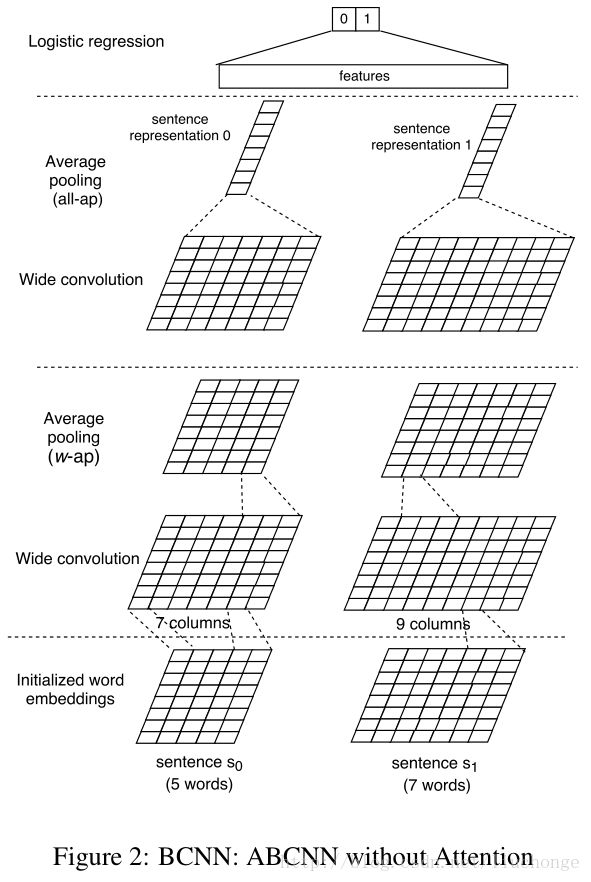
1, 输入层:
就是将输入句子进行padding后转化成词向量即可。
2,卷积层:
当一开始看到这张结构图的时候我以为采用的是per-dim的卷积方法,可是后来发现这样做的话最后一层的sentence representation维度会非常大(15000维),并不适合作为特征输入给全连接层(逻辑斯特回归)。所以又仔细看了一下论文中对卷积层的描述,如下图所示。可以看到,这里使用的应该是Yoon Kim论文中所提出的卷积方式,即一个窗口最后只生成一个卷积值,然后再句子长度上进行滑动,得到一个长度为sent_len+ws-1的向量(wide conv)。而图中为什么是一个方阵呢,我们可以看一下Pi的秩为d1,我们这里可以把d1理解为输出的channels。这样就可以把wide convolution层的纵深解释为channel,只不过这里将其画在了一个平面上而已。

3,pooling层
论文中提到了两种pooling层,一种是最后一个pooling层–all-ap,还有一种是中间卷积层所用的pooling层–w-ap。区别就是池化时的窗口大小不同。
all-ap:将卷积之后的结果在句长维度上进行Average Pooling, 得到一个列向量,如上图中最上面的pooling层所示。
w-ap:使用滑动窗口的形式,以窗口宽度w对卷积输出进行Average Pooling。因为输入层经过宽卷积后会变成sent_len+w-1,之后经过窗口大小为w的pooling层后仍然会变回sent_len。这样的话,conv-pooling层就可以无限叠加起来。
4,输出层
因为我们的任务是一个2分类,所以论文中使用的是logistic 回归层。不过这里需要注意的是,最后一层的输入特征除了最后一个conv层的输出之外,还额外添加了对每个conv层做all-ap得到的特征也将作为其输入。这么做是为了是逻辑回归可以观察到不同层面的抽象信息。
ABCNN-1
上面介绍了BCNN的基础模型,加下来分别介绍三种加入Attention的方式。首先是在输入层加入Attention,其示意图如下:
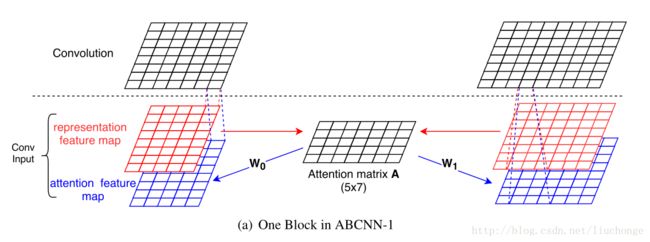
其原理就是将输入拓展成双通道,类似于图片的RGB模式。而添加的通道便是attention feature map,即上图中的蓝色部分。其计算方式如下:
1,计算attention矩阵A,其每个元素Aij代表句子1中第i个单词对句子二中第j个单词的match_score,这里使用Euclidean距离计算。如下图:

2,分别计算两个句子的attention map。如图所示,使用两个矩阵W0,W1分别和A还有 A的转置相乘即可获得与原本feature尺寸相同的特征图了。这里W0和W1都是模型参数,我们可以使用相同的W,即共享两个矩阵。这样我们就将原始的输入拓展成了两个通道。剩下的与BCNN保持不变即可。
ABCNN-2
ABCNN-1直接在输入层加Attention,目的是为了改善卷积层的输出,现在提出ABCNN-2,其目的是为了在卷积层输出的结果上进行改善。其示意图如下:
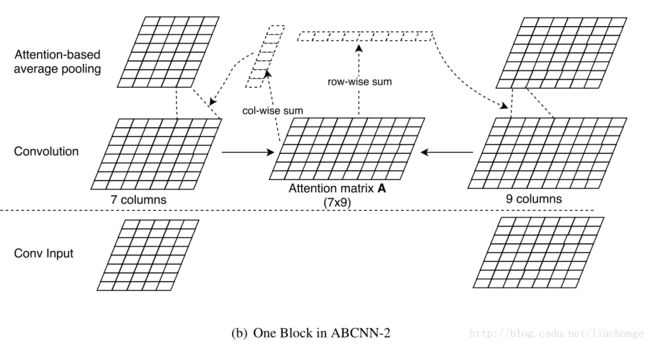
Attention矩阵A的计算方法与上述相同,计算完A,需要分别为两个句子计算两个Attention权重向量,如上图中的两个虚线部分。得到的两个向量中的每个元素分别代表了相应单词在做Average Pooling时的权重。即ABCNN-2模型中修改了pooling方法,不再是简单的Average Pooling,而是根据计算出的Attention权重向量计算。公式如下:

相比ABCNN-1而言,2是为了通过对conv卷积输出结果过进行赋权重改善pooling的结果,使获得的高层次抽象特征(短短语,长短语。。)中不同词按照不同的权重进行叠加。而且2添加的参数更少,更不易过拟合。
ABCNN-3
ABCNN-3其实就是将前面两个模型融合在一起组成一个新的模型,示意图如下所示:

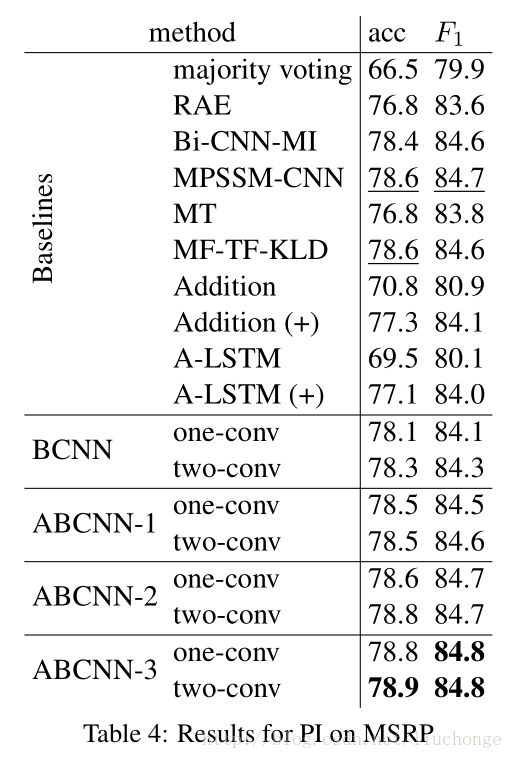
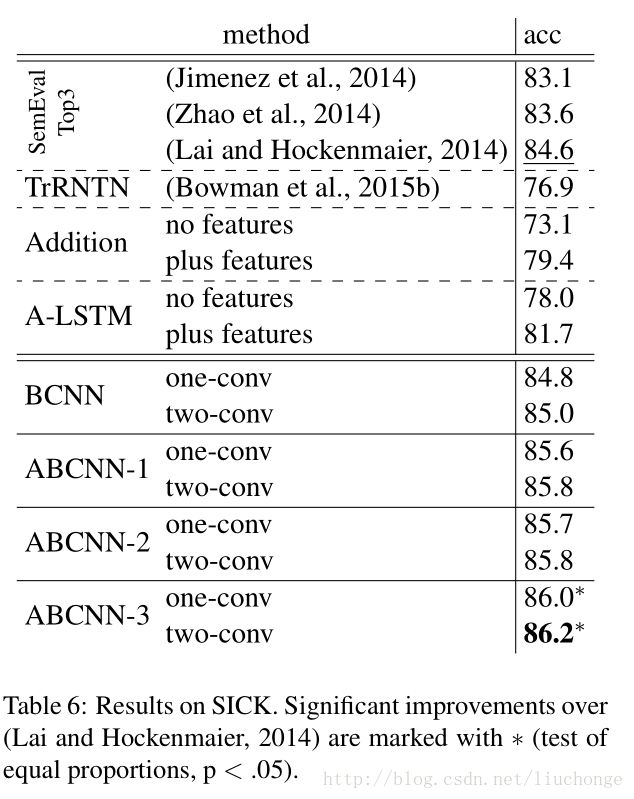
实验结果
论文为了证明模型的普适性,对三个不同领域的数据集做了实验,都达到了很好的实验效果。这三个数据集分别是:answer selection(AS)领域的WiKiQA,paraphrase identification(PI)领域的MSRP,Textual Entailment(TE)领域的SenEval 2014 Task。实验结果分别如下图所示: