Flink流计算编程--看看别人怎么用Session Window
1、简介
流处理在实际生产中体现的价值越来越大,Apache Flink这个纯流式计算框架也正在被越来越多的公司所关注并尝试使用其流上的功能。
在2017年波兰华沙大数据峰会上,有一家叫做GetInData的公司,分享了一个关于他们内部如何使用Flink的session window的例子,并因此获评最佳演讲。PPT:STREAMING ANALYTICS BETTER THAN CLASSIC BATCH – WHEN AND WHY ?
基于此演讲,该公司后续写了一个系列blog(2篇),详细的阐述了使用session window的来龙去脉。本文基于这两篇blog,做些简要的说明,也正好参考下别人是如何从传统的批的方式(spark),转而使用现代的流处理技术(Flink)来更好的实现其业务功能的。
2、User Sessionization
该公司是一家信息技术服务公司,由前Spotify员工组建。他们的这个案例受Spotify的启发,基于user session进行实时的数据分析。
关于Spotify提供的每周歌曲推荐,可以参考InfoQ上的一篇文章:Spotify每周歌曲推荐算法解析。
首先,基于用户的session,你可以作如下事情:
1、仪表板上显示一些KPI,例如用户在每周的Discover Weekly播放列表中听了多长时间,或者连续听了多少首歌曲等。
2、通过这些指标,你可以改进你的推荐算法,并发出一些警告及时的捕获一些变化较大的信息,例如澳大利亚用户听Discover Weekly播放列表中歌曲的时间太短。
3、而且,基于当前的数据分析,我们可以根据不同的用户,做些个性化的歌曲推荐和广告推荐。
3、古典的批处理架构
许多公司使用类似于Kafka、Hadoop、Spark、Oozie来分析用户session问题。
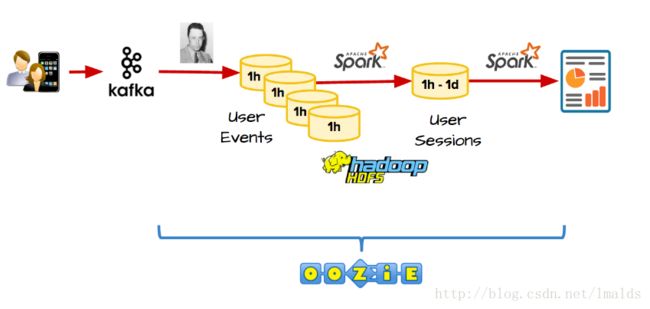
古典的批处理架构如下:用户会话的数据被实时的发送到kafka,之后使用批处理工具例如Campus(Gobblin)将kafka中的数据定时发送到HDFS,这里假设1小时抽取一次;之后由Spark来每小时进行一次批处理的Job,以计算用户session的数据分析。
但是这里有一个问题是用户可能会一直在听歌曲,因此session持续的时间很长,这样得到的结果就是不正确的。一种可选的解决方法就是通过维护一个每小时的中间结果来连接Job。关于使用古典的批处理来实现user session的问题,有一本专门的书来说明:Hadoop Application Architectures。
尽管批处理可以处理user session问题,但是依然有很多缺点:
1、首先,这条pipeline上边的组件太多,例如Gobblin,你需要部署额外的组件或者写更多的代码来维持pipeline的可用性。
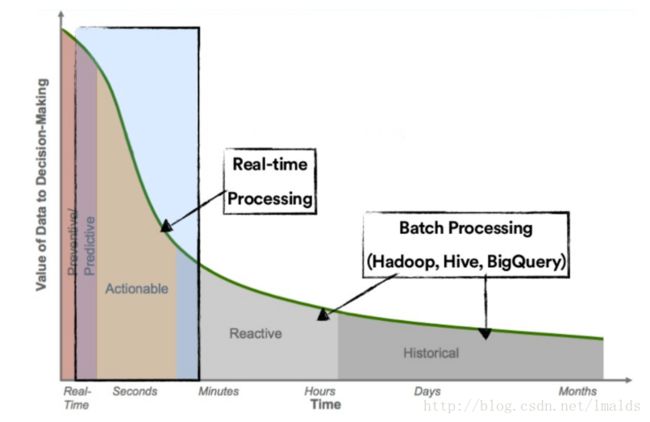
2、延迟性太高。这种架构不能实时的给出alerts,所有的结果必须等到1个小时后才能得到。4、微批架构
降低延迟并缩短结果反馈时间最简单的方式看起来就是使用类似于Spark Streaming这种微批架构了。

这种架构省去了Gobblin、Oozie、HDFS分区等组件,通过配置Spark Streaming的Job以每10分钟、5分钟或1分钟的批次,来实现更低的延迟。
但是,Spark Streaming本身没有内建支持Session问题的处理,由于其微批架构,用户不得不通过自定义的代码实现user session,同时这种方式不得不自己维持每个批次的状态信息。你可以通过mapWithState方法来维护每个user的session状态,有很多文章都提到如何构建一个user session,但是都没有提到实现过程中可能遇到的诸多问题。

5、现实世界的事件流
在现实世界,数据是无界的。有可能产生乱序、延迟现象。例如用户在飞机上是飞行模式(离线模式),此时正在听spotify的歌曲,但是直到飞机降落才上线,此时数据的产生就是乱序的数据。而且由于经过kafka,由于并行处理的网络等原因,迟到的数据也是无处不在。
因此,如果还是采用Spark Streaming这种架构,这些问题的产生很可能不能正确的处理,这样的结果就是不正确的。
6、解决流处理的问题
到这里,让我们问问我们自己,我们为什么要用传统的批处理、微批处理的方式来对待流数据呢?
在GetInData,我们找到了最简单的、最重要、最正确的流处理引擎—Apache Flink。通过使用Flink,实施起来不但十分简单,代码量很少,而且可以更快速的得到正确的结果。

7、实施案例
我们通过使用Flink很容易的解决了user session的问题,真的只有几行代码!!!
案例A表示一个用户在一个独立的session中听了多久的歌曲
案例B表示一个用户在播放列表中连续听了多少首歌曲首先,第一步我们需要从kafka中消费数据。通过Flink内部的检查点机制,可以保证exactly once的处理,这仅仅需要提供几个kafka的参数:
sEnv.addSource(new FlinkKafkaConsumer09[Event](conf.topic(),
getSerializationSchema,
kafkaProperties(conf.kafkaBroker()))
)之后,我们基于用户key,设置一个session window的gap,在同一个session window中的数据表示用户活跃的区间,假如gap的时间是15分钟:
.keyBy(_.userId)
.window(EventTimeSessionWindows.withGap(Time.minutes(15)))最后,我们应用一个window function,就可以用5行代码实现乱序问题的处理:
val sessionStream : DataStream[SessionStats] = sEnv
.addSource(new FlinkKafkaConsumer09[Event](...))
.keyBy(_.userId)
.window(EventTimeSessionWindows.withGap(Time.minutes(15)))
.apply(new CountSessionStats())8、高级的时间处理
上边这5行代码够优雅么?
答案是否定的,这里即使基于Event Time以及应用watermark来处理乱序,依然不够理想。考虑下面两种情况:
1、例如15分钟之后,突然来了一条之前5分钟数据怎么办?这时之前的session就不应该产生gap。
2、再比如假如一个用户一直在听音乐,gap一直没产生,那么这个用户的数据就一直无法及时产生。这个对于结果的反馈时间太长了。对于第一种情况,Flink提供了allowedLateness来处理延迟的数据,假设我们预计有些数据最晚会延迟1小时到来,那么我们可以通过allowedLateness设置一个参数,来处理那些延迟的数据:
.allowedLateness(Time.minutes(60))这样,当late data element到达时,我们依然可以正确的处理。
对于第二种情况,为了缩短结果的反馈时间,我们可以自定义一个early firing trigger实现每隔一段时间就触发一次计算:
.trigger(EarlyTriggeringTrigger.every(Time.minutes(10)))例如,我们每隔10分钟就触发一次窗口计算。考虑一个简单的例子,假如一个用户session持续了1个小时,那么通过这种触发器,我们就可以每10分钟便得到一个结果,之后的结果不断更新之前的结果,最终趋于正确。后边的结果相当于对前边的结果的刷新。

尽管代码相当简单,但是其背后却是Flink内援原理的支撑,例如低延迟、高吞吐、有状态的处理、简单的tasks等。
9、EarlyTriggeringTrigger的实现
class EarlyTriggeringTrigger(interval: Long) extends Trigger[Object, TimeWindow] {
//通过reduce函数维护一个Long类型的数据,此数据代表即将触发的时间戳
private type JavaLong = java.lang.Long
//这里取2个注册时间的最小值,因为首先注册的是窗口的maxTimestamp,也是最后一个要触发的时间
private val min: ReduceFunction[JavaLong] = new ReduceFunction[JavaLong] {
override def reduce(value1: JavaLong, value2: JavaLong): JavaLong = Math.min(value1, value2)
}
private val serializer: TypeSerializer[JavaLong] = LongSerializer.INSTANCE.asInstanceOf[TypeSerializer[JavaLong]]
private val stateDesc = new ReducingStateDescriptor[JavaLong]("fire-time", min, serializer)
//每个元素都会运行此方法
override def onElement(element: Object,
timestamp: Long,
window: TimeWindow,
ctx: TriggerContext): TriggerResult =
//如果当前的watermark超过窗口的结束时间,则清除定时器内容,触发窗口计算
if (window.maxTimestamp <= ctx.getCurrentWatermark) {
clearTimerForState(ctx)
TriggerResult.FIRE
}
else {
//否则将窗口的结束时间注册给EventTime定时器
ctx.registerEventTimeTimer(window.maxTimestamp)
//获取当前状态中的时间戳
val fireTimestamp = ctx.getPartitionedState(stateDesc)
//如果第一次执行,则将元素的timestamp进行floor操作,取整后加上传入的实例变量interval,得到下一次触发时间并注册,添加到状态中
if (fireTimestamp.get == null) {
val start = timestamp - (timestamp % interval)
val nextFireTimestamp = start + interval
ctx.registerEventTimeTimer(nextFireTimestamp)
fireTimestamp.add(nextFireTimestamp)
}
//此时继续等待
TriggerResult.CONTINUE
}
//这里不基于processing time,因此永远不会基于processing time 触发
override def onProcessingTime(time: Long,
window: TimeWindow,
ctx: TriggerContext): TriggerResult = TriggerResult.CONTINUE
//之前注册的Event Time Timer定时器,当watermark超过注册的时间时,就会执行onEventTime方法
override def onEventTime(time: Long,
window: TimeWindow,
ctx: TriggerContext): TriggerResult = {
//如果注册的时间等于maxTimestamp时间,清空状态,并触发计算
if (time == window.maxTimestamp()) {
clearTimerForState(ctx)
TriggerResult.FIRE
} else {
//否则,获取状态中的值(maxTimestamp和nextFireTimestamp的最小值)
val fireTimestamp = ctx.getPartitionedState(stateDesc)
//如果状态中的值等于注册的时间,则删除此定时器时间戳,并注册下一个interval的时间,触发计算
//这里,前提条件是watermark超过了定时器中注册的时间,就会执行此方法,理论上状态中的fire time一定是等于注册的时间的
if (fireTimestamp.get == time) {
fireTimestamp.clear()
fireTimestamp.add(time + interval)
ctx.registerEventTimeTimer(time + interval)
TriggerResult.FIRE
} else {
//否则继续等待
TriggerResult.CONTINUE
}
}
}
//上下文中获取状态中的值,并从定时器中清除这个值
private def clearTimerForState(ctx: TriggerContext): Unit = {
val timestamp = ctx.getPartitionedState(stateDesc).get()
if (timestamp != null) {
ctx.deleteEventTimeTimer(timestamp)
}
}
//用于session window的merge,判断是否可以merge
override def canMerge: Boolean = true
override def onMerge(window: TimeWindow,
ctx: OnMergeContext): TriggerResult = {
ctx.mergePartitionedState(stateDesc)
val nextFireTimestamp = ctx.getPartitionedState(stateDesc).get()
if (nextFireTimestamp != null) {
ctx.registerEventTimeTimer(nextFireTimestamp)
}
TriggerResult.CONTINUE
}
//删除定时器中已经触发的时间戳,并调用Trigger的clear方法
override def clear(window: TimeWindow,
ctx: TriggerContext): Unit = {
ctx.deleteEventTimeTimer(window.maxTimestamp())
val fireTimestamp = ctx.getPartitionedState(stateDesc)
val timestamp = fireTimestamp.get
if (timestamp != null) {
ctx.deleteEventTimeTimer(timestamp)
fireTimestamp.clear()
}
}
override def toString: String = s"EarlyTriggeringTrigger($interval)"
}
//类中的every方法,传入interval,作为参数传入此类的构造器,时间转换为毫秒
object EarlyTriggeringTrigger {
def every(interval: Time) = new EarlyTriggeringTrigger(interval.toMilliseconds)
}10、Flink中的ContinuousEventTimeTrigger
Flink中,其实已经实现了一个early trigger的功能,即ContinuousEventTimeTrigger,其实现方式大致相同:
/**
* A {@link Trigger} that continuously fires based on a given time interval. This fires based
* on {@link org.apache.flink.streaming.api.watermark.Watermark Watermarks}.
*
* @see org.apache.flink.streaming.api.watermark.Watermark
*
* @param The type of {@link Window Windows} on which this trigger can operate.
*/
@PublicEvolving
public class ContinuousEventTimeTrigger<W extends Window> extends Trigger<Object, W> {
private static final long serialVersionUID = 1L;
private final long interval;
/** When merging we take the lowest of all fire timestamps as the new fire timestamp. */
private final ReducingStateDescriptor stateDesc =
new ReducingStateDescriptor<>("fire-time", new Min(), LongSerializer.INSTANCE);
private ContinuousEventTimeTrigger(long interval) {
this.interval = interval;
}
@Override
public TriggerResult onElement(Object element, long timestamp, W window, TriggerContext ctx) throws Exception {
if (window.maxTimestamp() <= ctx.getCurrentWatermark()) {
// if the watermark is already past the window fire immediately
return TriggerResult.FIRE;
} else {
ctx.registerEventTimeTimer(window.maxTimestamp());
}
ReducingState fireTimestamp = ctx.getPartitionedState(stateDesc);
if (fireTimestamp.get() == null) {
long start = timestamp - (timestamp % interval);
long nextFireTimestamp = start + interval;
ctx.registerEventTimeTimer(nextFireTimestamp);
fireTimestamp.add(nextFireTimestamp);
}
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception {
if (time == window.maxTimestamp()){
return TriggerResult.FIRE;
}
ReducingState fireTimestamp = ctx.getPartitionedState(stateDesc);
if (fireTimestamp.get().equals(time)) {
fireTimestamp.clear();
fireTimestamp.add(time + interval);
ctx.registerEventTimeTimer(time + interval);
return TriggerResult.FIRE;
}
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public void clear(W window, TriggerContext ctx) throws Exception {
ReducingState fireTimestamp = ctx.getPartitionedState(stateDesc);
Long timestamp = fireTimestamp.get();
if (timestamp != null) {
ctx.deleteEventTimeTimer(timestamp);
fireTimestamp.clear();
}
}
@Override
public boolean canMerge() {
return true;
}
@Override
public void onMerge(W window, OnMergeContext ctx) throws Exception {
ctx.mergePartitionedState(stateDesc);
Long nextFireTimestamp = ctx.getPartitionedState(stateDesc).get();
if (nextFireTimestamp != null) {
ctx.registerEventTimeTimer(nextFireTimestamp);
}
}
@Override
public String toString() {
return "ContinuousEventTimeTrigger(" + interval + ")";
}
@VisibleForTesting
public long getInterval() {
return interval;
}
/**
* Creates a trigger that continuously fires based on the given interval.
*
* @param interval The time interval at which to fire.
* @param The type of {@link Window Windows} on which this trigger can operate.
*/
public static extends Window> ContinuousEventTimeTrigger of(Time interval) {
return new ContinuousEventTimeTrigger<>(interval.toMilliseconds());
}
private static class Min implements ReduceFunction<Long> {
private static final long serialVersionUID = 1L;
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return Math.min(value1, value2);
}
}
} 实现细节上省略了clearTimerForState(ctx)方法,同时增加了内部类Min实现求最小值的reduce方法。
11、后续的问题
尽管实现user session window很简单,但是这仅仅是一个系统的第一步,还有后续的问题需要考虑:
(1)如何重新处理数据?
假如我改了程序,想用以前的数据测试对比下两套程序的结果,Flink流上也可以实现么?答案是可以的。你可以通过“savepoints”功能实现。例如每天夜里12点定时产生savepoint,当你想重新消费数据时,就从那个savepoint开始重新消费kafka中的数据,相当于将时间回拨到了保存点的时间。
但这也有负面的影响,就是下游的输出可能已经落地了,但是如何处理他们是系统外部的事情了,但这一点也不容忽视。
(2)如果kafka中的数据没了怎么办?
这是个好问题,kafka具有持久化的能力,但大都由于磁盘限制,通过保留策略来保留一段时间的数据。假如我们想重新处理1年前的数据怎么办?一种可行的办法是将kafka的数据抽取到HDFS上,然后通过重写SourceFunction来重新消费这些数据。
但是这里引入另外一个问题–乱序。因为HDFS中的数据不保证是严格按事件发生的顺序存放的,消费时就可能产生乱序。
还有一点问题未解决,即在kafka和HDFS之间切换来消费数据,但这对于维护offset信息太难了。
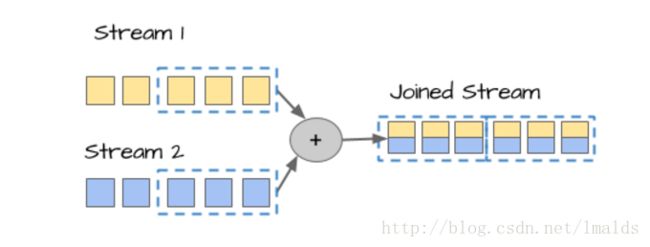
(3)一个流如何和其他的data Sets/stream进行join?
第一种情况是DataStream join DataStream,这个很简单,双流join的问题之前的blog中已经讲过:
第二种情况是DataStream join DataSet。这个通常的做法是DataStream通过实现RichXXXFunction,重写open方法,在open方法中将dataSet信息写入一个集合容器,然后对DataStream中的每个元素去匹配这个集合。

(4)我能用Flink做批处理么?
当然可以,Flink支持批和流的处理,你甚至可以用Apache Beam或Flink的Table API来进行批处理。
(5)什么时候适合用批处理?
批处理在很多场景下依然是非常好的选择,例如ad-hoc查询,像Hive、Spark-SQL、Presto、Kylin、Spark + R等就是非常好的工具。
当你要处理大量的HDFS上的数据时,也非常适合批处理。
而一些library的支持也仅仅在批处理上比较成熟,例如机器学习和图计算。
12、最重要的建议
流处理并不仅仅是为了触发某些警告或者以更低的延迟获得结果。
流处理通常是许多现实问题很自然的表达呈现形式,你可以在流上实现实时的ETL、统计一些KPI的指标、增强业务报告等。
像Flink这种现代的流处理框架,你可以用它很容易的、不断的处理并获得正确的结果。
总结起来就是:
当数据不断产生时,不要以批的方式去处理流!!!当数据不断产生时,不要以批的方式去处理流!!!当数据不断产生时,不要以批的方式去处理流!!!
参考:
http://getindata.com/blog/streaming-analytics-better-than-classic-batch-when-and-why-part-1
http://getindata.com/blog/streaming-analytics-better-than-classic-batch-when-and-why-part-2