《深入分析JavaWeb技术内幕》之读书笔记(篇二)
深入分析ClassLoader工作机制
1.1 哪些情况常需要实现自己的ClassLoader
- 在自定义路径下查找自定义的class类文件,该文件可能并不在ClassPath下面。
- 对我们要加载的类进行特殊处理。
- 定义类的实现机制,如类被修改了自动重加载(热部署)。
1.2 loadClass、findClass、defineClass
- loadClass:它是遵循双亲委派机制的,先检查是否加载过,如果未加载且指定了父类加载器,则委托父类加载器加载,否则委托bootstrap加载器加载。如果仍然没有加载到,则通过自己的findClass()方法加载。
- findClass:具体实现仅仅抛出
throw new ClassNotFoundException(name);,需要我们自己去重写。 - defineClass:常用格式
defineClass(String name, byte[] b, int off, int len),即将字节流数组b生成为指定全限定名name的class文件。
JVM体系结构与工作方式
2.1 体系结构
组成部分:
-
类加载器:每个被装载的类型都有一个对应的实例来表示该类型,该实例可唯一表示被JVM装载的class类,要求这个实例和其他类的实例一样都存放在JVM的堆中。
-
执行引擎:作用即是解析JVM字节码指令,得到执行结果。每个线程就是一个执行引擎,有些执行引擎执行用户程序,有些执行JVM内部程序(如垃圾回收器)。
-
内存区:其中方法区和堆是所有线程共享的,即可被所有执行引擎实例访问。而栈和PC寄存器:每个执行引擎(线程)被创建时,会为其创建一个Java栈和PC寄存器(程序计数器),PC寄存器指向其第一行可执行代码。
每调用一个新方法,则会在这个栈上创建一个新的**栈帧**,栈帧会保留这个方法的一些元信息,如局部变量、返回值、方法参数等等。
JVM在调用指令时可能需要用到常量池中的一些常量或一些实例化的对象,这时就可能去访问方法区或Java堆。
方法执行完后,局部变量区所有值被释放,PC寄存器被销毁,Java栈中于这个方法相关的栈帧将消失。
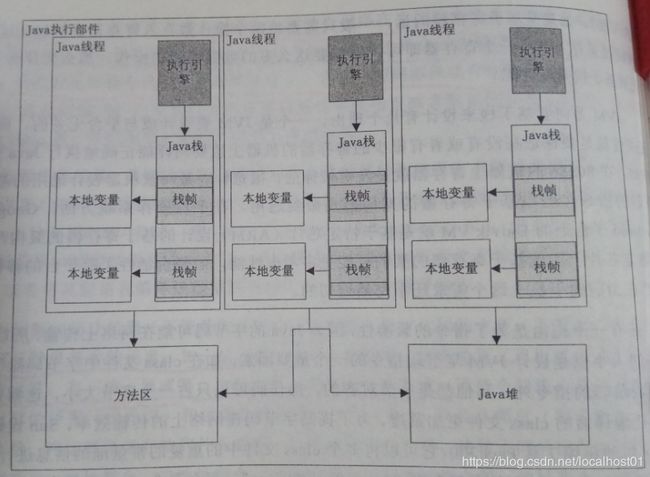
- 本地方法调用:调用c或c++实现的本地方法并返回结果。
2.2 工作机制
2.2.1 普通实体机执行代码
例如:linux平台下,安装一个软件,我们一般需要经过:configure、make、make install、make clean这四个步骤。
configure:为这个程序在当前操作系统环境下选择合适的编译器来编译这个程序代码,也就是为这个程序代码选择合适的编译器和一些环境参数;
make:对程序代码进行编译操作,将源码编译成可执行目标文件;
make install:将已经编译好的可执行文件安装到操作系统指定的或默认的安装目录下;
make clean:用于删除编译时产生的临时文件或目录。
JVM内存管理
3.1 内核空间与用户空间
为保证稳定性和安全性,用户程序不能访问操作系统所使用的内存空间(内核空间),如果用户程序需要访问硬件资源(如网络连接),可以调用操作系统提供的接口来实现(即系统调用),每一次系统调用都会存在两个内存空间的切换。通常网络传输也是一种系统调用,通过网络传输的数据先从内核空间接受到,然后再从内核空间复制到用户空间,供用户程序使用。效率的浪费就在这儿,所以出现了直接IO、内存映射等技术。Win32默认内核空间和用户空间比例是1:1;而Linux32默认是1:3
3.2 NIO
NIO使用java.nio.ByteBuffer.allocateDirect()方法分配内存,这个方式就是常说的NIO direct memory(直接IO访问文件方式)。ByteBuffer.allocateDirect()分配的内存使用的是本机的内存而不是Java堆中的内存。它避免了Java堆和本机堆间的数据复制。
3.3 JVM内存分配
一个Java应用唯一对应一个JVM实例,每个实例对应一个堆,每个线程对应一个栈,每个方法对应一个栈帧,对象存于堆,对象引用存入栈。
- 栈:存取速度比堆快,仅次于寄存器,栈数据可共享。缺点是存在于栈中的数据大小与生存周期必须确定
- 堆:优势是可以动态分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的(如new一个对象),垃圾收集器也会自动收走不再使用的数据。但缺点是,由于要在运行时动态分配内存,导致存取速度较慢。
附:内存泄漏排查
系统swap区突增、内存使用陡增,导致机器死机,可猜测发生了内存泄漏,内存泄漏排查可通过jstat分析jvm的堆情况和GC统计信息,JVM堆内存被耗光,那么肯定GC统计信息中,会出现多次的Full GC,如果Full GC正常,甚至没有,说明问题就不在JVM堆中了,可能出现在栈、NIO direct memory、native memory等地方。
Servlet工作原理解析
4.1 Tomcat容器

Tomcat容器分为四个等级,真正管理Servlet的容器是Context容器,一个Context对应一个Web工程,在Tomcat的配置文件中就可以很容易发现这一点:
<Context path="/project" docBase="D:\workspace\project" reloadable="true" />
Tomcat7开始支持嵌入式功能,即增加一个启动类org.apache.catalina.startup.Tomcat。创建一个该启动类的实例,并调用start()就可以很容易地启动Tomcat,另外还可以通过这个对象来配置和修改Tomcat参数,如动态增加Context(Web应用)、Servlet等。添加一个Web应用时,将会创建一个StandardContext容器,并给这个容器设置必要的参数,url和path分别代表这个应用在Tomcat中的访问路径和实际物理路径,还需配置一个很重要的ContextConfig。最后将这个Context容器添加到父容器Host中。
Tomcat的启动基于观察者模式,上面图中四个等级的容器都会继承Lifecycle接口,它管理着容器的整个生命周期,所有容器的修改和状态的改变都由它去通知已经注册的观察者。
4.2 Web应用初始化
初始化工作是在ContextConfig的configureStart()方法中实现的,初始化主要就是解析Web.xml,这个文件描述了一个Web应用的关键信息,也是Web应用的入口。
Tomcat首先寻找globalWebXml,这个文件是engine容器的工作目录下的某一位置,接着去找hostWebXml,然后就是寻找web项目的web.xml。并把各个配置项解析到WebXml对象中。
将WebXml对象的属性设置到Context容器中,这里包括创建Servlet对象(Servlet对象将被包装为StandardWrapper)、filter、listener等。
一个Web应用对应一个Context容器,容器的配置属性由应用的Web.xml指定,这样就理解了Web.xml到底是起什么作用了。
4.3 门面模式
-
StandardWrapper的门面类:StandardWrapperFacade
StandardWrapper和StandardWrapperFacade都实现了ServletConfig接口。所以传给Servlet的是StandardWrapperFacade对象,这个类保证了从StandardWrapper中拿到的ServletConfig所规定的数据,而不把ServerConfig不关心的数据暴露给Servlet,对数据起到封装的作用。 -
ServletContext的门面类:ApplicationContextFacade
该门面类同样保证了ServletContext只能从容器中拿到它该拿的数据,对数据起到封装的作用。 -
Request/Response的门面类:RequestFacade/ResponseFacade
目的一样,都是为了封装容器的数据。 -
StandardSession的门面类:StandardSessionFacade
request.getSession()获取的就是StandardSessionFacade。
一次请求对应的request和response转化流程:
Tomcat接受到请求先创建`org.apache.coyote.Request`和`org.apache.coyote.Response`,它们是轻量级类,作用是服务器接受到请求后,经过简单解析将这个请求快速分配给后续线程处理,其对象很小,易回收。
接下来当交给一个用户线程去处理时,创建`org.apache.catalina.connector.Request`和`org.apache.catalina.connector.Response`对象,这两个对象一直贯穿整个Servlet容器直到传给Servlet。
传给Servlete的是Request和Response的门面类:RequestFacade和ResponseFacade。

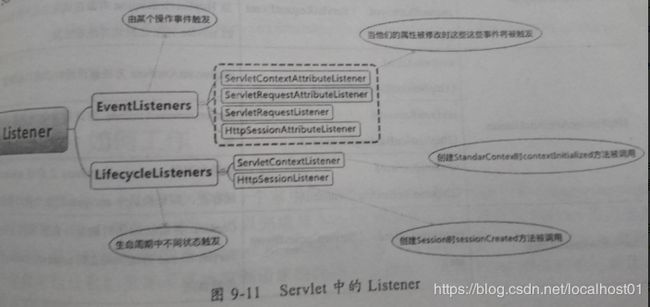
4.4 观察者模式
- Listener:Servlet提供六种两类事件的观察者接口。
4.5 Filter
Filter的核心即是传递FilterChain对象(其实现类为:ApplicationFilterChain),这个对象保存了到最终Servlet所经过的所有Filter对象,存于ApplicationFilterChain对象的filters数组中。因此ApplicationFilterChain类把多个Filter串联起来了,组成了一个链。FilterChain链上每执行一个Filter,数组计数+1,直到计数等于数组长度(即执行完了所有Filter),才会执行最终的Servlet。
深入理解Session和Cookie
5.1 Cookie
5.1.1 Cookie介绍
目前cookie分为两个版本,Version1和Version0,设置Vsersion0:Set-Cookie:userName="zhangsan";Expires=[过期时间],设置Version1:Set-Cookie2:username="zhangsan";Max-Age=1000
Java后端操作Cookie注意:
所创建的Cookie的NAME不能和Set-Cookie或Set-Cookie2的属性项一样,否则抛出IllegalArgumentException异常;
所创建的Cookie的NAME和VALUE值不能设置为非ASSIC字符,如需使用中文,可先URLEncoder编码,否则抛出IllegalArgumentException异常;
当NAME和VALUE值出现一些TOKEN字符(如“\”、“,”等),构建HTTP响应头会将该Cookie的Version自动设置为1;
当Cookie的属性项中出现Version1的属性项时,构建HTTP响应头同样会将该Cookie的Version自动设置为1。
`response.addCookie()`方法每次创建Cookie,都是一个以NAME为Set-Cookie的单独创建一个Header,最后请求返回构造HTTP响应头时再将每个Header合并。
浏览器对与Cookie大小和数量的限制:
| 浏览器版本 | Cookie数量限制 | Cookie总大小限制 |
|---|---|---|
| IE6 | 20个/每个域名 | 4095个字节 |
| IE7 | 50个/每个域名 | 4095个字节 |
| IE8 | 50个/每个域名 | 4095个字节 |
| IE9 | 50个/每个域名 | 4095个字节 |
| Chrome | 50个/每个域名 | >80000个字节 |
| Firefox | 50个/每个域名 | 4095个字节 |
5.1.2 Cookie压缩
由于Cookie在HTTP的头部,故通常的gzip和deflate针对HTTP Body的压缩不能压缩Cookie。Cookie的压缩方式可以是:将多个K/V看成普通文本,同样使用gzip或deflate做文本压缩。由于Cookie中不能包含控制字符,只能是ASCII码,所以再对结果进行base32或base64编码。如2KB左右的Cookie,压缩后大概字节数减少20%。
5.2 Session
5.2.1 Session介绍
Cookie中的默认JSESSIONID即是服务器对该客户端的唯一标识,客户端只需记住JSESSIONID,每次请求携带该值,服务器就能知道该用户是谁,并对其用session保持住状态,当然,JSESSIONID除了放于Cookie,也可以放于URL后的参数,服务器可从参数中拿到用户配置的SessionCookieName。
两种方法可以配置这个SessionCookieName:
- 参数名就是默认的JSESSIONID
- 在web.xml中配置session-config配置项,其cookie-config下的name属性即配置为参数名。
所有的Session的管理类为:org.apache.catalina.Manager,其实现类为:org.apache.catalina.session.StandardManager。
通过requestedSessionId从StandardManager的sessions集合中取出StandardSession对象。session过期时,StandardManager回收掉session;servlet容器重启或关闭时,StandardManager将调用unload()方法把所有的对象持久化到一个叫做SESSIONS.ser文件中,servlet容器启动时(StandardManager初始化时),会重新读取这个文件,将未过期失效的Session重新保存到自身维护的sessions集合中。
注:
- 以上所谓的servlet容器重启或关闭,需要调用servlet容器的stop和star命令,而不是强行kill,强行kill,没法进行session持久化保存。
request.getSession()调用的StandardSession对象会一直存在,即使session已过期(过期会重新创建一个新的StandardSession,只不过之前的session里的值消失了)。所以每次request.getSession()都能返回正常的session对象,但session里的值却可能已经不复存在了。
5.2.2 避免表单重复提交
可在用户请求,服务器返回“表单页面”时,生成一个token,一方面存入session中,一方面放置到form标签内(可用隐藏域),用户提交表单时,检查session中的token和表单提交上来的token是否一致,一致则无问题,否则是重复提交。