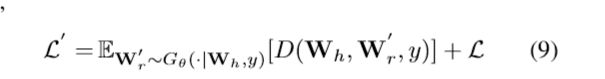半监督vae用于情感分类的论文汇总阅读:Variational Autoencoder
1.AAAI-2017-Variational Autoencoder for Semi-Supervised Text Classification
摘要:
虽然半监督变分自动编码器 (SemiVAE) 在图像分类任务中工作, 但如果使用vanilla LSTM作为解码器, 则在文本分类任务中失败。从强化学习的角度出发, 验证了解码器区分不同分类标签的能力是必不可少的。因此, 提出了半监督顺序变分自动编码器 (SSVAE), 通过在每个时间步长向其解码器 RNN 输入标签来提高其性能。研究了两种特定的解码器结构, 并验证了这两种结构的有效性。此外, 为了降低训练中的计算复杂度, 提出了一种新的优化方法, 即通过采样估计未标记目标函数的梯度, 并采用两种方差约简技术。在大型电影评论数据集 (IMDB) 和 AG 的新闻语料库上的实验结果表明, 与纯监督分类器相比, 该方法显著提高了分类精度, 并在竞争性能方面取得了更高的竞争力。以前的高级方法。通过整合其他基于预引导的方法, 可以获得最先进的结果。
主要贡献如下:
1)vanilla LSTM将误导解码器忽略标签输入,从而忽视y,在序列输入分类中失败。我们使用在每个step接收标签的 conditional LSTM 使 SSVAE 有效, 并从 RL 的角度给出解释。对两个似是而非的 conditional Lstm 进行了调查。
2)提出了一种优化方法, 通过采样降低 SSVAE 的计算复杂度。并提出了两种不同的基线方法来减小优化方差。通过使用这些基线进行采样, 可以更快地训练模型, 而不会丢失准确性。
3)我们通过在 IMDB 数据集和 AG 的新闻语料库上提供具有竞争力的结果来展示我们方法的性能。我们的模型能够实现非常强劲的性能与当前的模型。

与图像数据的实现不同, 在我们的模型中, 序列数据是由递归网络来建模的。具体而言, 编码器 fenc (·) 和分类器 q (y x) 被 LSTM 网络所取代。
对我自己的帮助:
1)指出如果将y和z 串行连接(concatenated)来初始化lstm的话,模型有忽视y的趋势,然而y又是非常重要的。于是通过在每个时间步中feed标签y来提高y对模型的影响,简单有效 ;
2)对于第一点的方法,本文用了两个结构,一个是在每个时间步串联了词嵌入和标签SSVAE-1。 另一个是直接让标签信息不经过四个门单元直接通过记忆单元SSVAE-2
3)SemiVAE的一个限制是数据集的类的规模,因此用蒙特卡洛方法采样可以减少计算复杂度,提出了两种采样方法,S1,S2是指不同 的采样基准, SSVAE-1,2是指 不同的条件LST M实现。
数据集上:
IMDB,AG’s News,无标签数据是从有标签数据转化来的,同时确保数据是平衡的。
2.arXiv.org -2018-Data Augmentation for Spoken Language Understanding via Joint Variational Generation
摘要:
数据稀缺是语言理解 (SLU) 领域适应的主要障碍之一, 因为创建手动标记的 SLU 数据集的成本很高。最近在神经文本生成模型, 特别是潜在的变量模型, 如变分自动编码器 (VAE) 的工作, 已显示出很有希望的结果, 在生成似是而非和自然的句子。在本文中, 我们提出了一个新的生成架构, 利用潜在变量模型的生成能力, 共同合成完全注释的话语。我们的实验表明, 现有的 SLU 模型在其他合成示例上进行了训练, 从而实现了性能提升。我们的方法不仅有助于缓解许多数据集在 SLU 任务中的数据稀缺问题, 而且在广泛的实验和严格的统计测试的支持下, 不加区别地提高了各种 SLU 模型的语言理解性能.
主要贡献:
1. The Generative DA(数据增强) Framework:我们专门为 SLU 任务开发了一个生成数据增强的通用框架。在配方过程中, 我们假设了先验逼近在生成采样中的重要性, 并提出了一种基于蒙特卡罗的方法。实验表明, 与其它近似方法相比, 基于蒙特卡罗的估计是优越的。
2.A Novel Model for Labeled Language Generation:我们提出了一个新的生成模型, 共同合成口语及其语义注释 (插槽标签和意图)。我们表明, 从模型生成的合成样本不仅是自然的, 准确的注释, 但他们提高 SLU 性能在生成数据增强框架中的显著优势。我们还表明, 我们的模式比以前的作品要好
3. Substantiation with Extensive Experimentation: :我们通过对各种 SLU 模型和数据集的实验和统计测试来证实生成数据增强的一般好处。结果表明, 我们的方法为 ATIS 数据集中的现有 SLU 模型产生了极具竞争力的性能。我们的烧蚀研究还带来了一些重要的见解, 如最佳合成数据集尺寸
对我自己的启发:
1.这里解释了如 果一个分布与 真实分布足够相 似,那么从这个 分布中采样的样 本就足以拿来当 作真实数据的样 本,即n+m
2.提出wb,wd。wd可以把扭曲的分布还原为与真实分布足够接近,如下图所示流程。
我自己理解这个wd是训练出来的一个参数(或者网络层),流程如下,真实数据p(x)由于采样或者噪音加入了扭曲函数wb,变成了p*(x),然后我们用这个p*(x)生成(我理解的这一步是能直接得到的样本数据集)数据集D,用这个数据集D训练得到p^(x),然后又经过wd的恢复函数还原成真实的数据分布p^*(x),然后就可以用这个真实的分布生成增强的数据集D^,以及数据重复后的D‘

3.指出标准VAE的不足,首先是用前面的 p (z), 即标准的多变量高斯来近似潜在变量的边际概率。然而, 由于潜在变量空 间的过度简化, 这种近似值很可能会产生均匀和无趣的话语。在现实场景中, 方程2中的 kld 损失 项在收敛后仍然很大。理想的方法应该是无偏但方差大的,因为这样才能得到真实又多样化的生成语句(蒙特卡洛方法可以得到每个语句样本w的无偏估计)
ps:不用考虑了。。。。请教了师兄大佬关于distort的wd怎么算的问题后。。。。作者好像根本就没有实现这个东西。
3.Knowledge-Based Systems(期刊)-2019-Semi-supervised dimensional sentiment analysis with variational autoencoder
摘要:
维度情绪分析 (DSA) 旨在计算从价和唤醒等多个维度中文本的实值情绪分数。现有的DSA 方法通常以监督学习为基础。但是, 为培训添加足够的示例是昂贵和耗时的。本文提出了一种基于变分自动编码器模型的 DSA 半监督方法。我们的模型由三个模块组成: 一个编码模块将句子编码为隐藏的向量, 一个情绪预测模块来预测句子的情绪分数, 以及一个解码模块, 它将前两个模块的输出作为输入和重新构造输入句子。在我们的方法中, 我们鼓励情绪预测模块准确地预测标记和未标记文本的情绪分数, 以帮助解码模块更准确地重建此类文本。因此, 我们的方法可以利用未标记数据中的有用信息。在三个基准数据集上的实验结果表明, 该方法可以有效地提高 DSA 的性能, 标记数据少得多
多维情绪分析是指综合情绪极性 (例如, 积极的, 消极的和中性的) 或情绪类别 (例如, 喜悦, 悲伤和愤怒)等维度。
对我的帮助:文章的开源代码
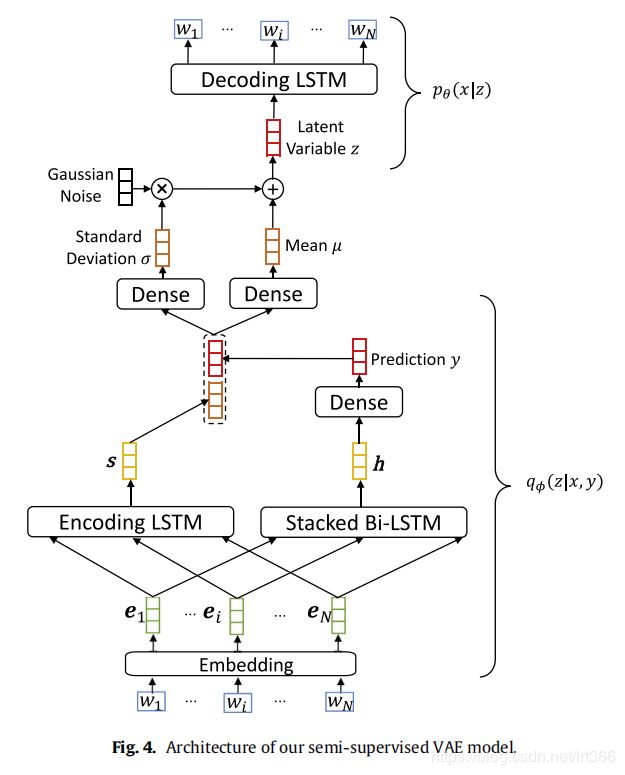
1)模型结构图如下所示,非常清楚,对于embedding层而言,要先得到pos标注的嵌入以及word的嵌入,然后把他们用一个concatenated层连接起来,作为embedding的输入。然后embedding层的输出作为分类器的输入(双向lstm有利于捕获分类信息),也作为编码器的输入,然后编码器的输出s和分类器的y用concatenated层连接起来,作为隐变量z。
2)
3)对于中文数据记得化繁为简,
4)情感极性不平衡会导致 kl的额外散 度
4.corr-2018-Variational Semi-supervised Aspect-term Sentiment Analysis via Transformer
摘要:
表观期情绪分析 (ATSA) 是自然语言理解中的一个长期挑战。它要求对文本中出现的目标实体进行细粒度的语义推理。由于对各方面的人工注释既费力又耗时, 因此, 对监督学习的标记数据数量是有限的。本文提出了一种基于变压器 (VAET) 的变分自动编码器对 ATSA 问题进行半监督的方法, 该方法通过变分推理对潜在分布进行建模。通过将潜在的表象分解为特定的情感和词汇语境, 我们的方法对未标记的数据进行潜在的情感预测, 从而有利于 ATSA 分类器。我们的方法是分类无关的, 即分类器是一个独立的模块, 可以集成各种先进的监督模型。在 2014年 Semval 任务4上获得了实验结果, 表明该方法在四个经典分类器中是有效的。该方法优于两种一般的半虚拟方法, 并达到了最先进的性能。
对自己的帮助:
这篇文章貌似就是换了一种vae的实现方法,用transformer来实现vae用于情感分析,没细看。。。下面是文中的结构图

5.ICML-2017-Toward Controlled Generation of Text
这是一篇偶然看到的论文,感觉对我之前担心的点有很大的帮助,他的模型结构也许能和S-vae结合一下?
对自己的帮助:
1.要是解决了我担心生成的样本噪声太大不能起到数据增强的作用(提出了一个约束);
2.模型的训练方式也可以借鉴(睡眠唤醒训练方法)
3.定向的控制生成文本的情感标签
可以改进的点:
1.更长的文本生成(文章限制了只有15词以内的训练数据以及生成数据)
2.更细粒度的属性生成
6.ACL-2018-A Structured Variational Autoencoder for Contextual Morphological Inflection
摘要:统计形态变化通常是在完全监督的类型级数据上进行训练的。一个尚未解决的研究问题是: 我们如何有效地利用原始的令牌级数据来提高其性能?为此, 我们引入了一种新的生成后变量模型, 用于拐点生成的半监督学习。为了实现对潜在变量的后验推理, 我们推导出了一种基于唤醒睡眠算法的有效变分推理过程。我们在23种语言上进行了实验, 在模拟的低资源设置中使用了通用依赖项语料库, 并在某些情况下发现绝对精度提高了10% 以上。
这篇文章主要是讲了对于词语形态变化的生成模型(do->doing->done->did),比如下面这个生成过程,我不是很感兴趣。。。所以就没细看,没有看到有明显的VAE结构。
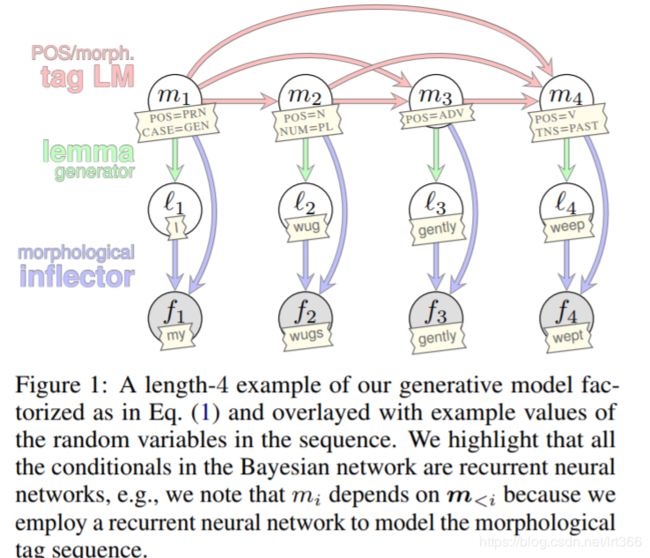
7.ACL-2018-Unsupervised Discrete Sentence Representation Learning for Interpretable Neural Dialog Generation
摘要:编码器-解码器对话模型是在复杂域中构建对话系统的最突出的方法之一。然而, 它是有限的, 因为它不能像传统系统那样输出可解释的行动, 这阻碍了人类理解其生成过程。我们提出了一种无监督的离散句子表示学习方法, 该方法可以与任何现有的编码解码器对话框模型集成, 用于可解释响应生成。在变分自动编码器 (Vae) 的基础上, 我们提出了两种新的模型, DI-VAE 和 DI-VST, 它们改进了 Vae, 可以通过自动编码或上下文预测发现可解释的语义。我们的方法已在实际对话数据集中进行了验证, 以发现语义表示, 并使用可解释的生成增强编码器解码器模型。
这一篇主要是引用了2017年icml那篇Toward Controlled Generation of Text论文的一个损失函数:

8.2018-arxiv-Semi-supervisedTarget-level Sentiment Analysis via Variational Autoencoder
摘要:
基于目标的表象分析 (TABSA) 是一个长期存在的挑战, 它需要对某个方面进行细粒度的语义推理。由于手动注释在很短的时间和时间上, 标记的数据量是有限的监督学习。本文提出了一种基于变分自编器 (VAE) 的TABSA问题的半监督方法。VAE 是一种强大的深层生成模型, 它通过变分推理来模拟潜在分布。该方法将潜在的表示分离到特定的情绪和语境中, 隐式地归纳出非标记数据的潜在情绪预测, 从而有利于 TABSA 分类器。我们的方法是分类器无关的, 即分类器是一个独立的模块, 可以集成各种高级监督模型。在2014年学期任务4上得到了实验结果, 结果表明, 四类分类器具有可见效的方法。该方法优于两种一般的半监督方法, 达到了最先进的性能
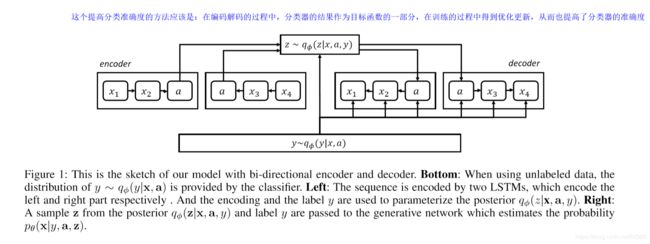
这个文章把ssvae应用在了aspect的情感分类上面,解释怎么学习aspect内容的如下所述

另外还有一些笔记:




9.2019-arxiv-An Adversarial Approach to High-Quality, Sentiment-Controlled Neural Dialogue Generation
摘要:在这项工作中, 我们提出了一种神经对话响应生成的方法, 它不仅允许根据对话历史生成语义上合理的响应, 而且还通过情绪标签明确控制响应的情绪。我们提出的模型是基于有条件的对抗性学习范式;一个对抗性的歧视者协助训练一个情绪控制的对话生成器, 该识别器评估从对话历史和特定情感标签中产生的反应的流畅性和可行性。由于我们框架的灵活性, 生成器可以是标准的序列到序列 (SEQ2SEQ) 模型, 也可以是基于 SEQ2SEQ 的复杂的序列化模型。利用自动评价和人工评价的实验结果表明, 我们提出的框架能够产生语义上合理和有感觉控制的对话反应
这篇文章把CVAE和CGAN结合起来生成可控的对话,损失函数是CVAE和CGAN的损失函数加起来,如下面损失函数第一项是CGAN的,第二项是CVAE的。我没有细看