Flink检查点问题
Flink检查点问题
- 问题简介
- 扫盲
- 什么是检查点
- 如何配置检查点路径
- 如何启用检查点
- 如何使用检查点
- 解决思路
- 小结
问题简介
Cannot find meta data file '_metadata' in directory 'hdfs://nn-HA-service/flink/flink-checkpoints'
上面是本人实际工作中遇到的一个问题,于是便百度了一下问题,查无结果,可能是很低级的错误吧,毕竟本人对flink也仅限于会用的地步。但还是打算总结一下这个问题,希望能帮助到各位读者。
扫盲
首先我们来扫盲一下相关知识点。
什么是检查点
官网是这样定义的:检查点通过允许恢复状态和相应的流位置使Flink中的状态容错,从而为应用程序提供与无故障执行相同的语义。
检查点的主要目:在意外的作业失败时提供恢复机制。
Checkpoint的生命周期由Flink管理,即Flink创建,拥有和发布Checkpoint - 无需用户交互。作为一种恢复和定期触发的方法,Checkpoint实现的两个主要设计目标是:
i)创建轻量级。
ii)尽可能快地恢复。
如何配置检查点路径
有两种方式:
- 通过配置文件全局配置
这种配置方式是全局的,即默认检查点路径。
搭建过集群的同学应该知道,配置文件一般都在conf目录下。没错,flink也是一样,我们需要修改的就是 flink/conf/flink-conf.yaml 这个文件。
在配置文件里面将下面这个参数配置上:
state.checkpoints.dir: hdfs://nn-HA-service/flink/flink-checkpoints
- 通过在作业里配置
就是在每个作业里,自定义检查点路径,优先级高于默认检查点路径。
如果没有定义,就走默认检查点路径。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new RocksDBStateBackend("hdfs:///flink/flink-checkpoints/");
如何启用检查点
flink默认是不会启用检查点的,这需要我们在代码里面设置。
代码如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置检查点间隔时间
env.enableCheckpointing(60000);
对,我们只需要设置下检查点的时间间隔,单位是ms,就说明启动了了一个一分钟完成一次的检查点策略了。
如何使用检查点
使用检查点,即在意外的作业失败后恢复数据。
这时,我们只需要指定检查点路径重启任务即可。
官网给的示例:
$ bin/flink run -s :checkpointMetaDataPath [:runArgs]
checkpointMetaDataPath : 这个是检查点元数据路径,并不简单是所配置的检查点的路径。笔者遇到的问题关键就在于此。
解决思路
由报出来的错误我们不难看出,flink是希望找到_metadata这个元数据文件,可我并没有指定此文件,所以报错了。
先介绍下我用的启动命令:
flink run -d -c com.FlinkCheckpointTest \
-s hdfs://nn-HA-service/flink/flink-checkpoints/ \
-m yarn-cluster \
-yjm 1024m -ytm 1024m -ynm FlinkCheckpointTest \
/home/jar/flink_test.jar
想必这个命令知道flink的同学都很熟悉,不熟悉的可以参考下Flink官网(https://flink.apache.org/)。
因此我去检查点目录下查找了一番,终于让我找到了 _metadata 文件。
如下图所示:
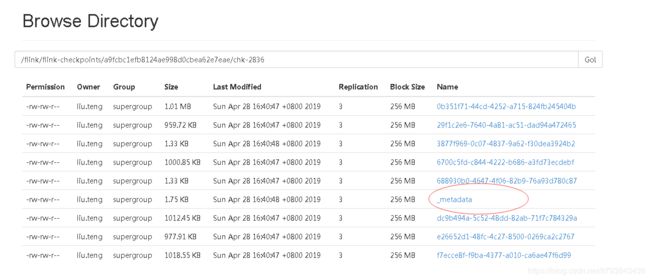
我们仔细看下这个目录:
/flink/flink-checkpoints/a9fcbc1efb8124ae998d0cbea62e7eae/chk-2836
前面两层目录是我们设置的检查点目录,后面一串像是id。
最后那个chk-2836应该就是实际检查点的目录,2836代表当前作业已经生成过2836次检查点了。最新的检查点覆盖之前的检查点。
/flink/flink-checkpoints/a9fcbc1efb8124ae998d0cbea62e7eae/ 该目录下面就一个chk开头的目录,即始终保存最新的目录,节省hdfs资源。
中间那一串id经过仔细查阅官网得知是jobID
好,那么现在主要的问题就是如何寻找对应作业的jobID
有两种情况:
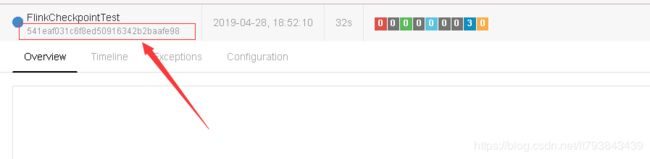
- 作业正在运行
这种情况,可以直接去flink的管理界面找到。如下图:
- 作业已经停止
这种情况,就需要去看此作业的详细日志了。如下图:
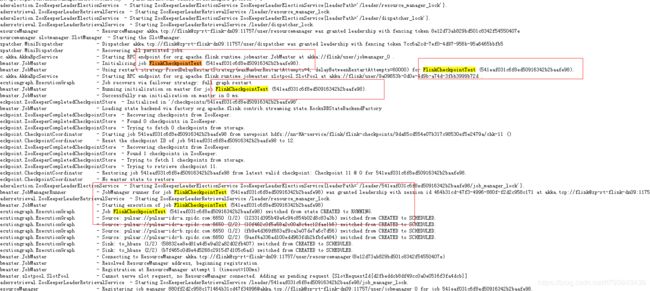
jobmanager.log 日志里面多次出现 作业名和 jobID
实际工作中,用到检查点的时候肯定是因为作业异常中断,所以大多数情况都是通过第二种方式去寻找作业对应的 jobID
修改后的提交作业命令:
flink run -d -c com.FlinkCheckpointTest \
-s hdfs://nn-HA-service/flink/flink-checkpoints/541eaf031c6f8ed50916342b2baafe98/chk-13 \
-m yarn-cluster \
-yjm 1024m -ytm 1024m -ynm FlinkCheckpointTest \
/home/jar/flink_test.jar
运行了一段时间,作业异常中断,发现是内存溢出错误,故适当调节内存,最终提交命令如下:
flink run -d -c com.FlinkCheckpointTest \
-s hdfs://nn-HA-service/flink/flink-checkpoints/541eaf031c6f8ed50916342b2baafe98/chk-13 \
-m yarn-cluster \
-yjm 4096m -ytm 4096m -ynm FlinkCheckpointTest \
/home/jar/flink_test.jar
好了,至此,问题圆满解决。
小结
这里顺便总结下flink作业异常中断的操作流程。
- 找出作业对应的jobID
- 进入hdfs对应目录,找到目录下面最新的检查点目录
- 通过指定检查点目录的方式重新启动作业
- 观察作业运行情况,如果出现内存溢出异常断开,加大内存重新启动。如果出现其他异常,欢迎留言给我,共同学习。
- 待作业运行稳定,查看作业最初异常中断的原因,记录下来并总结思考如何解决和避免。