为什么使用SpringBoot
1、web工程分层设计,表现层、业务逻辑层、持久层,按照技术职能分为这几个内聚的部分,从而促进技术人员的分工
2、需要各种XML配置,还需要搭建Tomcat或者jetty作为容器来运行,每次构建项目,都需要经历此流程
3、一个整合良好的项目框架不仅仅能实现技术、业务的分离,还应该关注并满足开发人员的“隔离”
springBoot是什么
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架致力于实现免XML配置,提供便捷,独立的运行环境,实现“一键运行”满足快速应用开发的需求。从而使开发人员不再需要定义样板化的配置。
从根本上讲,Spring Boot就是一些库的集合,它能够被任意项目的构建系统所使用。
它的优点
使编码变得简单
spring boot采用java config的方式,对spring进行配置,并且提供了大量的注解,极大地提高了工作效率。
使配置变得简单
spring boot提供许多默认配置,当然也提供自定义配置。但是所有spring boot的项目都只有一个配置文件:application.properties/application.yml。用了spring boot,再也不用担心配置出错找不到问题所在了。
使部署变得简单
spring boot内置了三种servlet容器:tomcat,jetty,undertow。
所以,你只需要一个java的运行环境就可以跑spring boot的项目了。spring boot的项目可以打成一个jar包,然后通过java -jar xxx.jar来运行。(spring boot项目的入口是一个main方法,运行该方法即可。 )
使监控变得简单
spring boot提供了actuator包,可以使用它来对你的应用进行监控。它主要提供了以下功能:
构建
整合spark

Scala版本demo
object WordCount {
def main(args: Array[String]): Unit = {
/**
- 第一步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息
- 例如说通过setMaster来设置程序要连接的Spark集群的Master的URL
- 如果设置为local,则代表Spark程序在本地运行,特别适合于配置条件的较差的人
*/
val conf = new SparkConf()
//设置应用程序的名称,在程序运行的监控界面可以看到名称
conf.setAppName("MyFirstSparkApplication")
//此时程序在本地运行,无需安装Spark的任何集群
conf.setMaster("local")
/** - /创建SparkContext对象,通过传入SparkConf实例来定制Spark运行的具体参数和配置信息
*/
val sc = new SparkContext(conf)
/** - 第三步:根据具体的数据来源(HDFS,HBase,Local FS(本地文件系统) ,DB,S3(云上)等)通过SparkContext来创建RDD
- RDD的创建基本有三种方式,根据外部的数据来源(例如HDFS),根据Scala集合,由其他的RDD操作产生
-
数据会被RDD划分成为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴
*///文件的路径,最小并行度(根据机器数量来决定)
val lines= sc.textFile("D://hadoop//spark-2.2.0-bin-hadoop2.7//README.md", 1)
//读取本地文件,并设置Partition = 1 //类型推导得出lines为RDD
/** - 第四步:对初始的RDD进行Transformation级别的处理,例如map,filter等高阶函数等的编程,来进行具体的数据计算
- 4.1:将每一行的字符串拆分成单个的单词
- 4.2:在单词拆分的基础上对每个单词的实例计数为1,也就是word =>(word,1)
-
4.3:在每个单词实例计数为1基础之上统计每个单词在文件出现的总次数
*///对每一行的字符串进行单词的拆分并把所有行的拆分结果通过flat合并成为一个大的单词集合
val words = lines.flatMap { line => line.split(" ") } //words同样是RDD类型
val pairs = words.map { word => (word,1) }
//对相同的key,进行value的累加(包括Local和Reducer级别同时Reduce)
val wordCounts = pairs.reduceByKey(+)
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + " : " + wordNumberPair._2))
//注意一定要将SparkContext的对象停止,因为SparkContext运行时会创建很多的对象
sc.stop()
}
}
注意的地方
spark版本自带scala包,需要使用对应的scala sdk版本编译。不要使用maven仓库作为下载pom文件依赖的java包,因为spark对应的scala包版本有误。
整合Elasticsearch
引入相关jar包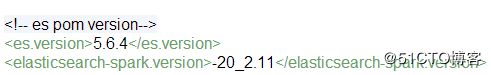
Scala版本demo
将数据写入es,自动创建es索引
object ESDemo {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("ESDemo").setMaster("local")
//在spark中自动创建es中的索引
conf.set("es.index.auto.creaete","true")
val numbers = Map("one" -> 1, "two" -> 2, "three" -> 3)
val airports = Map("arrival" -> "Otopeni", "SFO" -> "San Fran")
sc.makeRDD(Seq(numbers,airports)).saveToEs("spark/docs")
}
}
读取es中的数据,使用来org.elasticsearch.spark.sql读取索引中的数据
object ESDemo1 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("ESDemo").setMaster("local")
val sc = new SparkContext(conf)
//创建sqlContext
val sqlContext = new SQLContext(sc)
import sqlContext.implicits.
val options = Map("pushdown" -> "true", "es.nodes" -> "localhost", "es.port" -> "9200")
val spark14DF = sqlContext.read.format("org.elasticsearch.spark.sql").options(options).load("spark/docs")
spark14DF.select("one","two","three").collect().foreach(println())
//将数据注册到临时表
spark14DF.registerTempTable("docs")
val results = sqlContext.sql("SELECT one FROM docs")
results.map(t => "one:"+t(0)).collect().foreach(println)
sc.stop()
}
}
注意的地方
项目中引入的版本需要与安装的easticsearch的版本一致,且需使用对应的elasticsearch-spark包。
整合Kafka
引入相关jar包

Kafka读取数据写入ES demo
def main(args: Array[String]): Unit = {
import org.apache.spark.SparkConf
val conf = new SparkConf().setMaster("local").setAppName("KafkaToESDemo")
//在spark中自动创建es中的索引
conf.set("es.index.auto.creaete","true")
val ssc = new StreamingContext(conf, Seconds(10))
var topics = Array("orders_four");//kafka topic名称
var group = "" //定义groupID
val kafkaParam = Map( //申明kafka相关配置参数
"bootstrap.servers" -> "XXX.XXX.XX.XX:XXXXX", //kafka 集群IP及端口
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> group, //定义groupID
"auto.offset.reset" -> "earliest",//设置丢数据模式 有 earliest,latest, none
"enable.auto.commit" -> (false: java.lang.Boolean)
);
val offsetRanges = Array()
var stream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParam))//从kafka读取数据 获取数据流
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //获取offset
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) //存储offset
val wordsDataFrame = rdd.map(record=>record.value().split(","))
.map(temp=>Record(temp(0).toLong,temp(1),temp(2).trim().toInt,temp(3).trim().toInt,temp(4).trim().toInt,temp(5).trim().toInt,temp(6),temp(7),temp(8),temp(9),temp(10),temp(11).toDouble,temp(12).toDouble,temp(13),temp(14).toDouble,temp(15).toDouble,temp(16),temp(17),temp(18),temp(19),temp(20),temp(21),temp(22),temp(23).toInt,temp(24),temp(25).toInt,temp(26).toDouble,temp(27).toDouble,temp(28).toDouble,temp(29).toDouble,temp(30).toDouble,temp(31),temp(32),temp(33).toDouble,temp(34).toInt,temp(35).toDouble,temp(36).toDouble,temp(37).toDouble,temp(38),temp(39),temp(40).toInt,temp(41).toDouble,temp(42).toDouble,temp(43).toDouble,temp(44).toDouble,temp(45).toDouble,temp(46).toDouble,temp(47).toDouble,temp(48)))
.saveToEs("spark/kafkademodocs",
Map("es.mapping.id" -> "id","es.writeoperation" -> "upsert","es.update.retry.on.conflict" -> "5"))
}
ssc.start();
ssc.awaitTermination();
}
注意的地方
spark-streaming-kafka包需要与spark版本一致,也需要与scala sdk版本一致;
写入Es的api方法说明
saveToEs对应DStream type needs to be a Map (either a Scala or a Java one), a JavaBean or a Scala case class.
saveJsonToEs 对应JSON字符串
saveToEsWithMeta 对应pair DStream
整合mybatis
引入相关jar包
使用mybatis-spring-boot包,使mybatis配置变的简单。使用druid数据连接池,性能强大,并提供了sql监控,便于运维管理。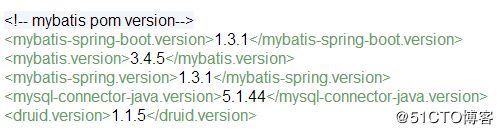
application.yml 配置信息:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://tdsql-4b9a8yqj.gz.cdb.myqcloud.com:23/test?serverTimezone=Hongkong&characterEncoding=utf8&useUnicode=true&useSSL=false
username:
password:
type: com.alibaba.druid.pool.DruidDataSource
max-active: 20
initial-size: 1
min-idle: 3
max-wait: 60000
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
test-while-idle: true
test-on-borrow: false
test-on-return: false
poolPreparedStatements: true
maxOpenPreparedStatements: 20
validationQuery: select 'x'
注册datasource
@Configurationbr/>@EnableTransactionManagement
public class DruidDataSourceConfig implements EnvironmentAware {
private static Logger logger = LoggerFactory.getLogger(DruidDataSourceConfig.class);
private RelaxedPropertyResolver propertyResolver;
public void setEnvironment(Environment env) {
this.propertyResolver = new RelaxedPropertyResolver(env, "spring.datasource.");
}
@Bean
public DataSource dataSource() {
logger.info("***开始注入druid***");
DruidDataSource datasource = new DruidDataSource();
datasource.setUrl(propertyResolver.getProperty("url"));
datasource.setDriverClassName(propertyResolver.getProperty("driver-class-name"));
datasource.setUsername(propertyResolver.getProperty("username"));
datasource.setPassword(propertyResolver.getProperty("password"));
datasource.setInitialSize(Integer.valueOf(propertyResolver.getProperty("initial-size")));
datasource.setMinIdle(Integer.valueOf(propertyResolver.getProperty("min-idle")));
datasource.setMaxWait(Long.valueOf(propertyResolver.getProperty("max-wait")));
datasource.setMaxActive(Integer.valueOf(propertyResolver.getProperty("max-active")));
datasource.setMinEvictableIdleTimeMillis(Long.valueOf(propertyResolver.getProperty("min-evictable-idle-time-millis")));
datasource.setValidationQuery(propertyResolver.getProperty("validationQuery"));
try {
datasource.setFilters("stat,wall");
} catch (SQLException e) {
e.printStackTrace();
}
logger.info("***成功注入druid***");
return datasource;
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean() throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource());
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();sqlSessionFactoryBean.setMapperLocations(resolver.getResources("classpath:/mybatis/*.xml"));
return sqlSessionFactoryBean.getObject();
}
}
简单的mapper
兼容两种模式,注解和xml方式写sql
@Mapper
public interface UserMapper {
public User findUserInfo();
public User findUserById(Integer id);
@Select("SELECT * FROM USER WHERE NAME = #{name}")
User findByName(@Param("name") String name);
@Insert("insert into user(name,age) value(#{name},#{age})")
int insert(@Param("name") String name,@Param("age") Integer age);}
对应的xml
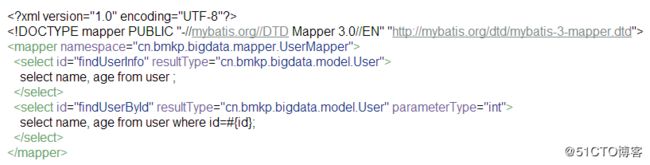
注意:mapper接口方法名称,为id,注解方式和xml中不能重名。
总结
独立运行的Spring项目
Spring Boot可以以jar包的形式进行独立的运行,使用:java -jar xx.jar 就可以成功的运行项目,或者在应用项目的主程序中运行main函数即可;
内嵌的Servlet容器
默认使用内置的tomcat服务器。
提供starter简化Manen配置
spring boot提供各种starter,其实就是一些spring bao的集合,只不过spring boot帮我们整合起来了而已。
上图只是其中的一部分,还有很多其他的。通过这些starter也可以看得出来,spring boot可以和其他主流的框架无缝集成,比如mybatis等。所以,不需要担心你想用的技术spring boot不支持。
自动配置Spring,无xml文件
Spring Boot会根据我们项目中类路径的jar包/类,为jar包的类进行自动配置Bean,这样一来就大大的简化了我们的配置。当然,这只是Spring考虑到的大多数的使用场景,在一些特殊情况,我们还需要自定义自动配置(就在那唯一的配置文件里,而且它不是xml文件!)。
应用监控
Spring Boot提供了基于http、ssh、telnet对运行时的项目进行监控。
后续扩展
Springboot开启应用监控
Spring Boot Admin 用于监控基于 Spring Boot 的应用。官方文档在这里(v1.3.4):《Spring Boot Admin Reference Guide》。
Springboot集成任务调度Quartz
Springboot集成Elasticsearch
Spring Boot为Elasticsearch提供基本的自动配置,Spring Data Elasticsearch提供在它之上的抽象,还有用于收集依赖的spring-boot-starter-data-elasticsearch'Starter'。
提供简单的restful操作elasticsearch.
Springboot集成Neo4J
Neo4j是一个开源的NoSQL图数据库,它使用图(graph)相关的概念来描述数据模型,把数据保存为图中的节点以及节点之间的关系。相比传统rdbms(关系管理系统)的方式,Neo4j更适合大数据关系分析。Spring Boot为使用Neo4j提供很多便利,包括spring-boot-starter-data-neo4j‘Starter’。
Springboot集成redis
Redis是一个缓存,消息中间件及具有丰富特性的键值存储系统。Spring Boot为Jedis客户端library提供基本的自动配置,Spring Data Redis提供了在它之上的抽象,spring-boot-starter-redis'Starter'收集了需要的依赖。