TensorFlow:实战Google深度学习框架第二版——第六章
第六章——图像识别与卷积神经网络
6.1 图像识别问题简介及经典数据集
第五章用到的MNIST手写体识别数据集。
CIFAR 数据集就是一个影响力很大的图像分类数据集。CIFAR 数据集分为了 CIFAR-10 和 CIFAR-100 两个问题,它们都是图像词典项目(Visual Dictionary)中 800 万张图片的一个子集。 CIFAR 数据集中的图片为 32×32 的彩色图片,每张图片仅包含一个种类的物体。
CIFAR-10 问题收集了来自 10 个不同种类的 60000 张图片。和 MNIST 相比, CIFAR 数据集最大的区别在于图片由黑白变成的彩色, 且分类的难度也相对更高。CIFAR 官网 ht叩s://www.cs.toronto.edu/~kriz/ cifar.html 提供了不同格式的 CIF1忧 数据集下载, 具体的数据格式这里不再赘述。
无论是 MNIST 数据集还是 CIFAR 数据集,相比真实环境下的图像识别问题, 有 2 个 最大的问题。第一,现实生活中的图片分辨率要远高于 32× 32,而且图像的分辨率也不会 是同定的。第二,现实生活中的物体类别很多,无论是 10 种还是 100 种都远远不够,而且 一张图片中不会儿出现一个种类的物体。为了更加贴近真实环境下的图像识别问题,由斯 坦福大学(Stanford University)的李飞飞(Feifei Li)教授带头整理的 ImageNet 很大程度 地解决了这两个问题。
ImageNet 是一个基于 WordNet®的大型图像数据库。在 ImageNet 中,将近 1500 万图片 被关联到了 WordNet 的大约 20000 个名词同义词集上。目前每一个与 ImageNet 相关的 WordNet 同义词集都代表了现实世界中的一个实体,可以被认为是分类问题中的一个类别。ImageNet 中的图片都是从互联网上爬取下来的,井且通过亚马逊的人工标注服务(Amazon Mechanical Turk)将图片分类到 WordNet 的同义词集上。 在 ImageNet 的图片中, 一张图片中可能出现多个同义词集所代表的实体。
在物体识别问题中 , 一般将用于框出实体的矩形称为 bounding box
ImageNet 每年都举办图像识别相关的竞赛 ClmageNet Large Scale Visual Recognition Challenge, ILSVRC),而且每年的竞赛都会有一些不同的问题,这些问题基本涵盖了图像识别的主要研究方向。 ImageNet 的官网 http://www.image-net.org/challenges/LSVRC 列出了历届 ILSVRC 竞赛的题目和数据集。不同年份的 ImageNet 比赛提供了不同的数据集,本书 将着重介绍使用得最多的 ILSVRC2012 图像分类数据集。
注:ImageNet数据集中根据任务种类不同有不同的数据集,这里主要使用的是分类数据集。
top-N 正确率指 的是图像识别算法给出前 N 个答案中有一个是正确的概率。在图像分类问题上,很多学术论文都将前 N 个答案的正确率作为比较的方法,其中 N 的取值一般为 3 或 5。
6.2 卷积神经网络简介
第五章使用的神经网络是全连接神经网络,所使用的是FC全连接层。即相邻两层之间各个节点之间都有连接。
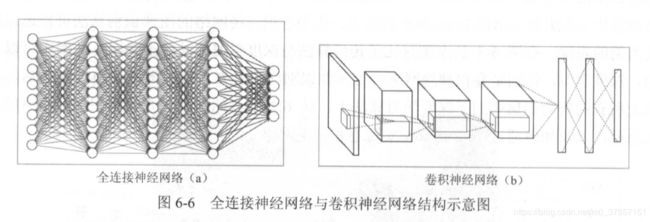
一般有三种网络:全连接神经网络,卷积神经网络(CNN),循环神经网络(RNN)
对于卷积神经网络,相邻两层之间只有部分节点相连,为了展示每一层神经元的维度,一般会将每一层卷积层的节点组织成一个三维矩阵。在TensorFlow中训练一个卷积神经网络的流程和训练一个全连接神经网络没有任何区别。二者的唯一区别就是层与层之间连接方式不同,导致了层间计算方式不同。
全连接网络处理图片的最大问题在于全连接层的参数太多。比如第n层有500个隐藏节点,n-1层输出是28*28=784,784即为n-1层的节点数,也是n层的输入,那么n层需要参数量为:28*28*500+500,后面的500为偏置量b,即WX+b中W与b的参数和。(W=(500,784))参数过多,会导致计算速度变慢,同时网络容易过拟合。所以需要有一个更合理的网络结构来有效减少神经网络中参数个数,卷积神经网络CNN就可以达到这个目的。
下面是一个很普通的卷积神经网络结构图:
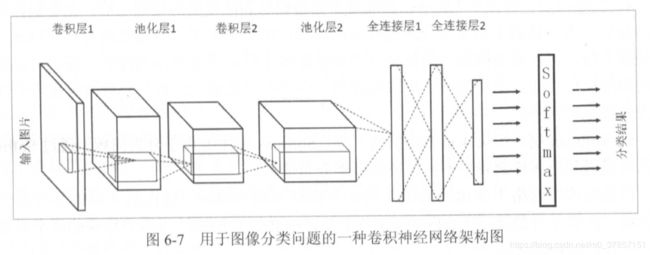
一张RGB图像,假如为(28,28,3),对于全连接网络来说,整合为28*28*3=2352的一维矩阵作为输入,而对于卷积神经网络来说,就直接整合为(28,28,3)的三维矩阵形式作为输入(之后直接用28*28*3代表这个三维矩阵)。
一个卷积神经网络(Convolutional Neural Network, CNN)主要由以下五种结构组成:输入层,卷积层,池化层,全连接层,输出层。
6.3 卷积神经网络常用结构
6.3.1卷积层
重要概念:
filter:过滤器,可以将当前网络层上的一个子结点矩阵转化为下一层上的一个单位节点矩阵。
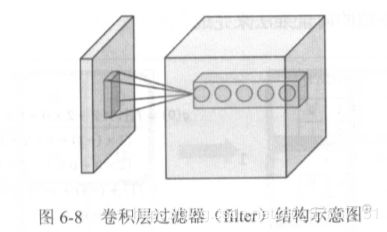
一般某层的过滤器只需要指定两个参数,过滤器尺寸s以及深度(数量)
假如某层输入矩阵为n*n*3,过滤器尺寸为s,那么每一个过滤器都是f*f*3,数量有num个,则该层过滤器维度为:f*f*3*num,该层输出应该为x*x*num。
有关卷积运算的概念,如何计算等,请自行百度搜索。或者通过吴恩达的深度学习工程师这门课来学习,同理关于池化pooling的概念及运算,因为这部分内容需要连续的一幅幅图来连接起来讲解才容易明白,不然初学者容易混乱。
简单理解就是将一个过滤器,即f*f*3放于输入的n*n*3左上角开始,通过滑动步长s来滑动,每次对上一个位置,就会将对应区域的f*f*3与过滤器的f*f*3上每一个对应元素相乘然后想加,得到输出中的一个值。这样下来,一个过滤器会通过与输入进行这样的卷积运算得到一张平面x*x。然后有num个过滤器,最后有num个平面,组合在一起就得到输出x*x*num。
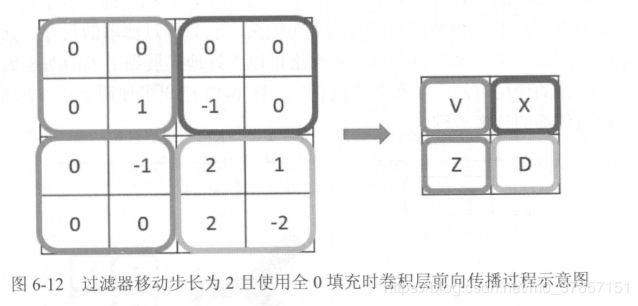
按照上面举例,一个卷积层的过滤器参数相当于全连接网络中的w,一个卷积层的所有参数数量为:f*f*3*num+num,+的是偏置b。注意,这里的偏置,是一个过滤器和输入进行卷积操作后,加一个偏置。一共num个过滤器,所以有num个偏置。每一个偏置属于一个过滤器。
TensorFlow对卷积神经网络的支持很好,如下代码实现了一个卷积层的前向传播过程:
#通过tf.get_variable()的方式创建过滤器的权重变量和偏置项变量。
#上面介绍的卷积层的参数个数只和过滤器#的尺寸,深度,以及当前层输入矩阵的深度有关,
#所以这里生命的参数变量是一个四维矩阵,前两个维度代表了
#过滤器的尺寸,第三个维度代表了输入矩阵的深度,最后一个维度代表了过滤器深度(数量),
#构成f*f*3*num的形式
fileter_weight=tf.get_variable(
'weights',[5,5,3,16],
initializer=th.truncated_normal_initializer(stddev=0.1)
)
#和卷积层的权重类似,当前层矩阵上不同位置的偏置项也是共享的,
#所以总共有下一层深度个不同的偏置项,本样例代码中16为过滤器的深度,
#也是神经网络下一层的节点矩阵的深度(下一层的输入矩阵的深度)
biases=tf.get_variable(
'biases',[16],initializer=tf.constant_initializer(0.1)
)
#tf.nn.conv2d()提供了一个非常方便的函数来实现卷积层的前向传播算法。
#这个函数第一个输入为当前层的节点矩阵,即当前层输入矩阵,为四维矩阵,第一维为batch_size
#第二个参数提供了卷积层的权重w,第三个参数为不同维度上的步长
#注意,虽然第三个参数步长是长度为4的数组,但是第一维和最后一维的数字要求一定是1,
#因为只有水平步长和垂直步长,步长仅对长宽有效。
#第四个参数为padding填充的方式,仅可选择SAME(全零填充)或者VALID(不填充,有效卷积)
conv=tf.nn.conv2d(
input,filter_weight,strides=[1,1,1,1],padding='SAME'
)
#tf.nn.bias_add()提供了一个方便的函数给每一个节点加上偏置项。
#注意这里不能直接用加法,请思考python的广播机制。
#使用上面函数是因为矩阵(一面)的不同位置的节点需要加上相同的数
bias=tf.nn.bias_add(conv,biases)
#将计算结果通过ReLU激活函数完成去线性化
actived_conv=tf.nn.relu(bias)6.3.2 池化层
池化层(pooling layer)可以有效的缩小矩阵的尺寸。一般常用的是最大池化和平均池化,最常用的是最大池化。池化和卷积的计算方式类似,区别在于卷积的过滤器是横跨整个深度进行计算,而池化使用的过滤器单次只影响一个深度的节点,然后通过在深度维度上的移动来横跨整个输入矩阵。
#tf.nn.max_pool()实现了最大池化层的前向传播过程,它的参数和tf.nn.conv2d()函数类似
#ksize提供了过滤器的尺寸,strides提供了步长,padding提供了是否使用全0填充
pool=tf.nn.max_pool(
actived_conv,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME'
)第一个参数为输入,四维矩阵,第一维是batch_size,第二个参数是filter尺寸,虽然是四维,但第一维和第四维必须为1。因为池化层计算方式的原因,所以过滤器就是一个面,只有长宽。TensorFLOW还提供了tf.nn.avg_pool()来实现平均池化层,参数同tf.nn.max_pool()函数。
6.4 经典卷积网络模型
6.4.1 LeNet-5模型
下面是LeNet-5模型的结构图,然后代码连接可以查看代码,给出的是一个完整的LeNet-5模型(因为使用的MNIST数据集,所以每层的尺寸略有不同,但是整体网络结构基本一样,该代码是在第五章末所给出的TensorFlow最佳实践样例程序上所改而成),通过这个模型,给出了卷积神经网络结构设计的一个通用模式。
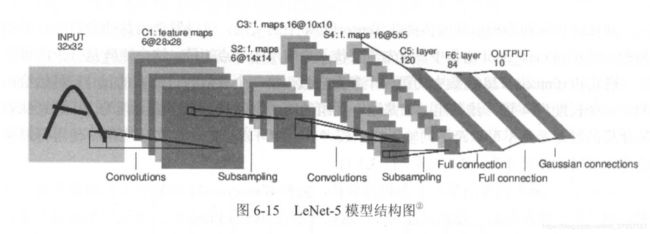 代码链接:LeNet-5
代码链接:LeNet-5
6.4.2 Inception模型
在LeNet-5中,不同卷积层使用串联的方式连接,而Inception-v3模型中的Inception模块结构是将不同的卷积层通过并联的方式结合在一起。Inception模块同时使用不同尺寸的过滤器(过滤器尺寸不同则提取到的特征不同),然后将得到的结果矩阵拼接起来。如下为一个Inception模块的结构示意图:

虽然过滤器尺寸不同,按理说卷积后矩阵的尺寸不同,无法直接拼接。但是若所有的卷积计算均使用全0的SAME方式填充,步长控制好,那么可以使得不同尺寸的过滤器进行卷积后得到相同的长宽,不同的深度,这样的话就可以进行深度拼接了。
Inception-v3模型的结构图:
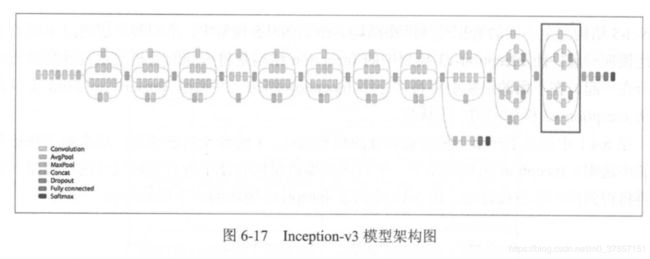
上图中标注的方框内就是一个Inception模块,Inception-v3模型共46层,由11个Inception模块组成。在Inception-v3中一共有96个卷积层,按照6.4.1的LeNet-5实现卷积层的方式来实现的话,一个卷积层要5行代码,则共需要480行代码来实现所有的卷积层,则代码可读性很差。
为了实现Inception-v3这种复杂的卷积神经网路,一般使用一些高层封装API。
#直接用TensorFlow原始API来实现卷积层
with tf.variable_scope(scope_name):
weight=tf.get_variable(name,shape四维(f*f*c*n),initializer)
biases=tf.get_variable(name,shape(n),initializer)
conv=tf.nn.conv2d(input,weight,strides=[1,x,x,1],padding)
relu=tf.nn.relu(tf.nn.bias_add(conv,biases))
#使用TensorFlow-Slim实现卷积层
#slim.conv2d()三个参数必须,第一个为输入,第二个为当前层卷积层的深度,即过滤器个数,
#第三个为过滤器尺寸f*f,可选的参数有过滤器移动步长s,padding,激活函数选择以及命名空间等
net=slim.conv2d(input,32,[3,3])通过TensorFlow的高级封装中的slim工具(共四种高层封装,分别是TensorFlow-Slim,TFLearn,keras和Estimator),实现谷歌提出的Inception-v3模型中的一个模块(实现的是图6-17中框中的那个模块)。
代码链接:Inception-v3中的一个Inception模块示例代码
6.5 卷积神经网络迁移学习
迁移学习(Transfer Learning),就是将一个问题上训练好的模型通过简单的调整,使其适用于另一个新的问题。一般用于数据量不太充足的情况,当数据量很充足时,从头开始训练效果优于迁移学习,但是迁移学习所需要的训练时间和训练样本数要远远小于训练完整的模型。fine-tune是迁移学习的一种。一般迁移学习是前面的卷积层不变,只换最后的全连接层,则最后的全连接层之前的网络称之为瓶颈层(bottleneck)
本节给出一个完整的TensorFlow程序来介绍如何通过TensorFlow实现迁移学习,下面的代码给出了如何下载这一节中将要用到的数据集:
wget http://download.tensorflow.org/example_images/flower_photos.tgz
tar xzf flower_photos.tgz上述第二条语句为解压命令,解压后的文件夹包含五个子文件夹,每一个子文件夹的名称为一种花的名称,代表不同的类别。平均每一种花有734张图片,每一张图片都是RGB色彩模式,大小也不相同。和之前的样例不同,这一节中给出的程序将直接处理没有整理过的图像数据。以下代码给出了如何将原始图像数据整理成模型需要的输入数据:
代码链接:make_data
运行上面代码可以将图片划分为训练,验证和测试三部分,并且将图片从原始的jpg格式转化为inception-v3模型需要的299*299*3的数字矩阵,保存再npy文件中。
下面的代码可以下载谷歌提供的训练好的inception-v3模型。
wget http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
#解压后可以得到训练好的模型文件inception_v3.ckpt
tar xzf inception_v3_2016_08_28.tar.gz现在,数据有了,预训练模型文件也有了,可以进行迁移学习了,具体代码如下链接中所示:
代码链接:fine_tune
本章内容到此为止,实际工程应用中还会有各种各样问题,这里仅仅是基础,任重而道远,且行且珍惜~~