2018“达观杯”文本智能处理挑战赛心得
达观杯是一个NLP文本处理比赛,由达观数据公司主办,具体信息参考此比赛网址。为了熟悉一下算法比赛的流程,报名并参加了这个比赛,此比赛已经结束了,但是仍然可以报名参加获取分数和排名,这个kaggle的比赛一样,我觉得对于新人练手来说还是很方便的。废话不多说,以下详述比赛流程。
环境配置
- win10
- python3.6
- pycharm
- jupyter notebook
- scikit-learn 0.19.1
- time
数据分析
下载数据
报名比赛后,才能下载比赛方提供的数据,首先查看文件格式,包括两个csv文件,均作了脱敏处理
- train_set.csv:训练集,每行对应一篇文本,首行为列名。共有四列: 第一列是文章的索引(id),第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);第三列是在“词”级别上的表示,即词语相隔正文(word_seg);第四列是这篇文章的标注(class)。列之间用英文逗号“,”隔开,article和word_seg中字/词符用空格隔开。
- test_set.csv:测试集,格式同训练集,共三列,id,article,word_seg。
打开pycharm,预览查看数据集格式,训练集部分截图如下:

明确任务
建立模型通过训练集长文本数据正文(article和word_seg),预测测试集文本对应的类别(class)
查看结果提交示例格式说明:
1) 以csv格式提交,编码为UTF-8,第一行为表头
2) 内含两列,一列为id,另一列为class
3) id对应测试集中样本的id,class为参赛者的模型预测的文本标签。
数据预处理
查看数据
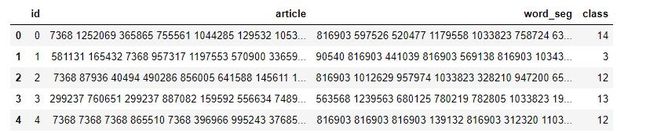
一般使用pandas能够方便地进行数据分析,打印训练集前5行数据,可以看出5列数据
IN:
import pandas as pd
df_train = pd.read_csv('./train_set.csv')
df_train.head()OUT:
打印训练集数据详情
IN:
df_train.info()OUT:
RangeIndex: 102277 entries, 0 to 102276
Data columns (total 4 columns):
id 102277 non-null int64
article 102277 non-null object
word_seg 102277 non-null object
class 102277 non-null int64
dtypes: int64(2), object(2)
memory usage: 3.1+ MB 打印测试集数据详情
IN:
df_test= pd.read_csv('./test_set.csv')
df_test.info()OUT:
RangeIndex: 102277 entries, 0 to 102276
Data columns (total 3 columns):
id 102277 non-null int64
article 102277 non-null object
word_seg 102277 non-null object
dtypes: int64(1), object(2)
memory usage: 2.3+ MB 很多比赛提供的数据文件会有部分缺失值,但是这份训练集和数据集只有文本信息,一般是不会有缺失信息,打印详情后,发现也验证了这一点,故不需要像其他比赛那样增补缺失值。
分析数据特性
查看每篇文本的长度,有多少字/词组成
IN:
def charLen(charlist):
charlist = charlist.split(' ')
return len(charlist)
df_train['char_len'] = df_train['article'].map(charLen)
df_train['word_len'] = df_train['word_seg'].map(charLen)
df_train.head()OUT:

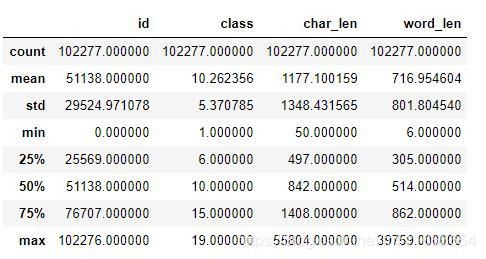
分析字/词的平均值、最大值、最小值等,可以看出:class一共19个类,文章字数平均字数1177,平均词数717
IN:
df_train.describe()OUT:
特征工程
特征工程一般有三种方法:
- 经典文本特征:TF、TF-IDF、doc2vec、word2vec
- 构造新特征:寻找可能影响分类的新特征(文章长度)、人工构造可能影响分类的新特征(特征组合
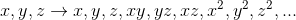 )
) - 神经网络提取:神经网络一般的输入为文本词向量,但尝试的结果只有0.72,未达到目标0.77,故使用传统机器学习方法来做比赛,神经网络相当于特征提取器加上分类器,使用隐藏层来提取特征作为算法输入
经验:
一般地,对于文本来说,十万级的数据使用传统机器学习优于深度学习,达到百万级的数据使用深度学习优于传统机器学习,但不绝对,需要具体问题具体分析。
特征选择:包裹式、嵌入式、过滤式(西瓜书)
特征降维:有监督降维(线性判别分析LDA)、无监督降维(LSA、主题分析模型lda、NMF)
分类器
一般的数据挖掘中,首先两种分类器,一种是逻辑回归,另一种是lightgbm和xgboost。
逻辑回归:简单性,可解释性,特别是对于大规模的稀疏特征时,相较其他模型,训练速度快。先使用逻辑回归测试,看看大致的效果,让自己对问题有一个大概的估计。然后再尝试其他复杂的分类器,去提高模型性能。
lightgbm和xgboost,都是基于GBDT的算法,具体可参考李航《统计学习方法》8.4.3节,通常情况下,这两种分类器比其他效果好,各大比赛的大杀器。
常用的分类器算法:
- 基于sklearn实现:逻辑回归、支持向量机、朴素贝叶斯、随机森林、bagging
- lightgbm
- xgboost
- 深度学习神经网络
比赛常用提分策略——模型融合(可参考西瓜书)
- 投票法:少数服从多数原则,多个单模型分类投票结果汇总获取票数最大的类别,对不同单模型赋予不同权重,好分类器大权重。方法简单,各个单模型需要效果好且具有差异性(模型差异性:训练集不同(随机采用)、特征不同(组合特征)、分类器不同)
- 学习法
实验评估
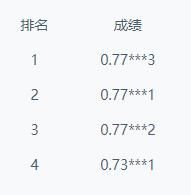
尝试采用不同特征+分类器的组合得到实验结果,耗时包括数据加载时间,特征工程,分类器学习和预测时间,result.csv数据保存时间。由于提交结果后显示的成绩是隐藏了三位小数,所以后续上传结果成绩不是top1的无法得知具体得分,top1可以通过查看排行榜得出,这里就按照分数从高到低排列结果表格。标记“设置参数”表明使用了非默认参数进行学习,并且每次实验的特征提取和学习模型的参数并不一致,略微做了调整,未标记表明使用的默认参数。
| 特征 | 生成特征并转为pkl格式时间(min) |
| tf | 14.43 |
| tf-idf | 9.86 |
| lsa | 13.34 |
| doc2vec | 54.53 |
| lda | 197.63 |
| hash | |
| lda+lsa+doc2vec(ensemble) | 0.06 |
| ensemble+tf-idf(ensemble_sparse) | 0.06 |
| 特征 | 模型 | 使用验证集及其分数 | 分数 | 耗时(min) |
| tf-idf(训练集+测试集word_seg)(设置参数) | 支持向量机LinearSVC(设置参数) SVC参数寻优(设置参数) |
3折交叉验证 C=1.0, penalty=l2, score=0.77108 |
0.77775(目前TOP1) | 312.46 |
| tf-idf(训练集word_seg)(设置参数) | 支持向量机LinearSVC k折个模型融合 |
10折交叉验证,0.77706 | 0.77***1 | 32.74 |
| ensemble_sparse | SVM(设置参数) | 否 | 0.776698 | 83.55 |
| tf-idf(训练集word_seg)(设置参数) | 支持向量机LinearSVC(设置参数) 特征寻优(设置参数) SVC参数寻优(设置参数) |
[Parallel(n_jobs=1)]: Done 270 out of 270 | elapsed: 3557.5min finished Best score: 0.771 |
0.77***7 | 3578.44(我的天呐) |
| tf-idf(训练集+测试集word_seg)(设置参数) | 支持向量机LinearSVC | 划分9:1,0.7813 | 0.77***2 | 17.94 |
| tf-idf(训练集word_seg)(设置参数) | 支持向量机LinearSVC | 否 | 0.77***7 | 16.04 |
| ensemble_sparse | 逻辑回归(设置参数) | 否 | 0.75***8 | 151.56 |
| tf(训练集word_seg)(设置参数) | 逻辑回归(设置参数) | 否 | 0.73***1 | 忘记计算了 |
| tf-idf(训练集word_seg)(设置参数) | 决策树 | 否 | 0.529679 | 80.82 |
运行一次实验至少一个小时以上,十分耗时,实验结果持续更新ing。。。