S-Net: From Answer Extraction to Answer Synthesis for Machine Reading Comprehension 论文阅读笔记
本文发表于2018年AAAI,作者为Chuanqi Tan, Furu Wei, Nan Yang...等人,文章提出了一个新的针对MS-MARCO dataset的模型S-NET,并且在该数据集上取得了state of art的成绩。
本文的创新点在于:
- 作者提出extraction-then-synthesis框架从抽取的结果中合成答案
- 使用篇章排序的手段提高了从多篇文章中获取答案的准确性
- 使用生成模型来生成答案,更能契合数据集所提供的数据
摘要部分
作者提出一个针对于MS-MARCO的阅读理解模型,区别于SQuAD数据集,MS-MARCO数据集并没有将答案的范围在文章中标明,并且还存在答案中的词汇与原文不同的情况,作者提出了一个抽取-合成模型来形成最终的答案。特别的,答案抽取模型首先被用来从文章中预测最有可能的范围,作为答案合成模型的一个额外的特征来进一步形成最终的答案。作者使用了最优的阅读理解模型作为答案抽取模型,并且将文章排序作为一个额外的子任务来从多篇文章中抽取答案。答案生成模型基于seq2seq结构,最终取得该数据集上的最好成绩。
介绍部分
介绍部分首先对数据集进行对比,略,主要就是一个有答案范围一个没有,一个答案是抽取的一个答案是生成的,一个是单篇文章一个是10篇文章中的10个段落,现有针对于MS-MARCO数据集的方法主要继承与SQuAD数据集的方法,预测答案的开始位置和结束位置,依据MS-MARCO的描述,答案可能从多个范围生成(因此不能做10选1来抽取答案)答案呢,词汇有可能来源于文章,也有可能在文章和问题中压根没有出现(因此不能单纯使用抽取式的方法,需要生成式)。
在这篇文章中,作者提出了一个抽取-生成模型,如下图所示。一个evidence extraction 事实抽取模型用从一篇文章中预测最重要的子范围,可以理解为最重要的句子。然后生成模型使用抽取出来的信息加之文章与问题生成一个答案(注意,文章中没有提到使用问题的类型作为辅助)。

其中抽取模型使用state-of-the-art attention based neural networks来预测(evidence)关键信息的开始和结束,作者同时提出了incorporating passage ranking合并段落(文章)排序作为一个辅助任务来提高关键信息抽取的效率,整个过程是一个多任务学习,使用RNN将单词序列化,并且使用注意力机制来构建问题与篇章级别的表示,之后使用pointer network(Vinyals, Fortunato, and Jaitly 2015)来预测答案的开始和结束,此外使用attention pooling来汇总每篇文章词级别的信息,使用篇章级表示来给候选篇章排序。生成模型依据关键信息(evidence)使用seq2seq来生成答案,问题和篇章使用双向RNN编码,其中关键信息的开始和结束也作为特征输入,之后使用attention decoder来生成最终答案。评价指标使用ROUGH-L和BLEU-1。
相关工作
捡几个觉得有用的列举一下吧
- Wang and Jiang (2016b) combine match-LSTM and pointer networks to produce the boundary of the answer
- Xiong,Zhong, and Socher (2016) and Seo et al. (2016) employ variant co-attention mechanism to match the question and passage mutuall
- Xiong, Zhong, and Socher (2016) propose a dynamic pointer network to iteratively infer the answer
- summarization generation (Zhou etal. 2017) 看看最后使用的什么结构的seq2seq
我们的方法
模型包含两方面,首先是(evidence)关键信息抽取模型和答案生成模型,答案抽取模型旨在抽取与文章与问题相关的关键信息,答案生成模型旨在依据抽取的信息生成答案。因为作者提出了一个多任务学习的框架如下图所示,然是使用seq2seq和一些附加特征来生成答案。
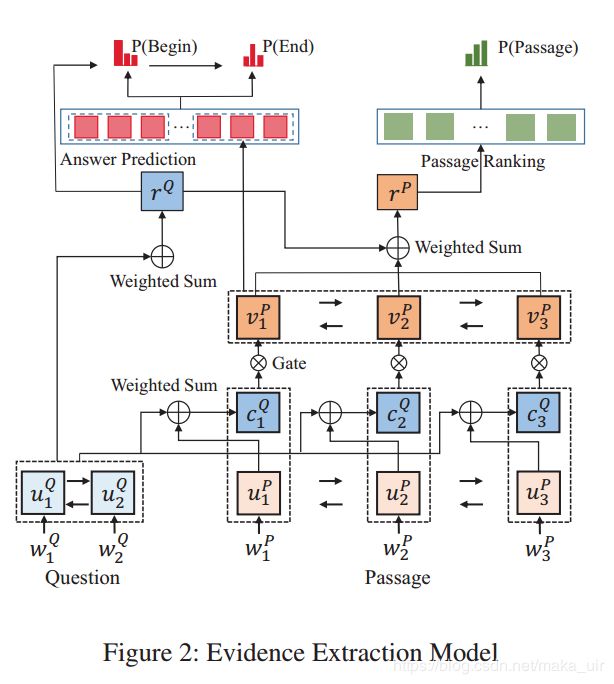
GRU
文章中的RNN使用的是GRU,公式略,解释略。。。
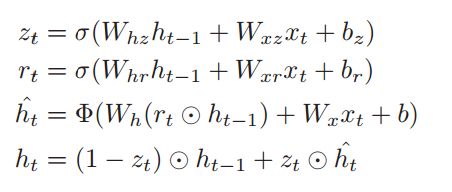
Evidence Extraction
多任务学习信息抽取框架,与SQuAD不同,MS的数据集答案来源于不同文章,此外MS的数据集还标注了哪篇文章是正确的(数据集中的 is selected),在此之上,作者提出了一个篇章排序加范围预测的模型,为了更好地预测答案范围,作者使用对候选进行段落排序,并把这个作为另外一个任务。
实现部分,公式不好打,意思就是一个问题Q由若干词W组成,同样篇章也是由若干W组成,首先对W进行embedding,然后获得character级别的embedding...这个是由一个双向GRU组成,取隐层末态作为character这一级别的表示。(这里的character代表啥。。。是字母还是。。。)应该是字母,我的理解是这样的,如下图所示:
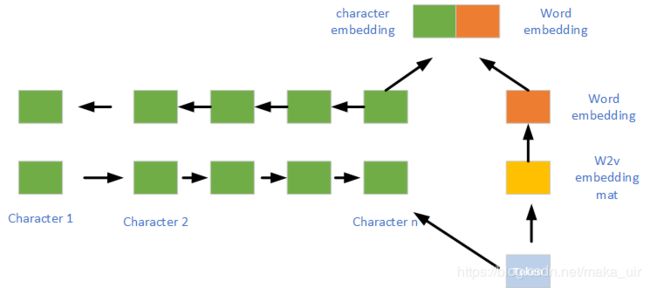
这个是我自己绘制的,与论文无关,就是将一个词向量化之后,随机初始也好,W2V,glove也好,就是上面橙色块,也就是一个word-level embedding,然后将一个单词中的所有字母初始化成向量,字典大小为26?这个可能得实验时候再做,然后将一个单词的字母过双向GRU,将最后拼接的f_w和b_w拼接形成[f_w,p_w]的形式,再与word embedding进行拼接形成最后的token embedding。
插入部分。。与原论文无关,如何实现character级别的embedding
原文链接 : http://www.aclweb.org/anthology/C14-1008
还找到一个character embedding代码https://github.com/asahi417/DocumentClassification作为参考
这个还与原文不同,这个首先使用Word2vec训练得到词级别的向量,没啥可说的,然后使用单层CNN获得character级别的表示,然后将词级别的向量和字符级别的向量相连作为一个token词条的表示。但是阅读理解中使用双向GRU的末态输出作为一个character级别的向量表示。

回到原文,使用词向量和字符向量,通过双向GRU生成问题和篇章的向量表示,如下公式:
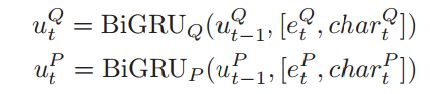
然后根据2015年Rocktaschel et al. (2015)提出的方法,通过soft-alignment,生成句子对表示,其中c是问题和篇章中句子的一个attention-pooling值:(需要找到这篇文章看看是如何做的)
![]()
其实c就是一个attention值,通过如下公式计算得到:

粗略看着就是每一句话对于问题计算一个不同的attention。
Wang and Jiang (2016a) 提出了一个match-lstm的概念(这个看原论文)本文中使用这个来判断那篇文章更重要,十选几的问题,如下公式:
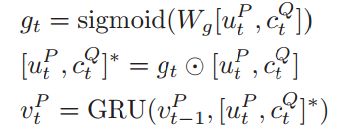
然后使用 pointer networks (Vinyals, Fortunato, and Jaitly 2015)来预测evidence关键信息的位置 Following the previous work (Wang and Jiang 2016b),这篇文章也要看。。作者将所有的篇章连接起来,来预测一个关键信息的范围。后续也是,使用attention计算,得到start和end的位置。这个还需要在想想。。。也就是得到10个文章中两个权重最高的?公式如下:
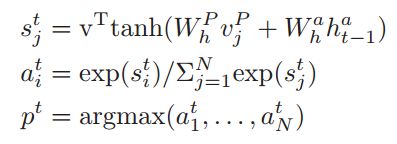
其中ht是 pointer network的末态, pointer network的输出是attention-pooling vector
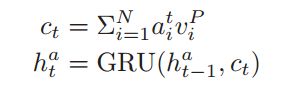
这里的公式感觉有些乱,自己顺了一下,画了个图,再把思路理一下:

首先,使用上面生成的字向量(character embedding)和 词向量 (word embedding)分别对应着上面的 e_t 和 char_t。然后这两个分别经过GRU网络生成句子基本的表示和篇章级别的表示u_Q 和 u_P,使用这两个向量计算attention:c_Q,使用这个attention值和一个sigmod组成的遗忘门选取passage里面重要的信息,经过一个GRU网络生成sentence pair : v_t。
前面的准备工作就这样,然后使用Question representation加一个attention作为answer recurrent network的初始状态,就是上面的图的绿线,然后使用answer recurrent network的每一个状态与sentence pair : v_t做attention,然后输出起点和终点的位置。整体的loss由如下公式计算:
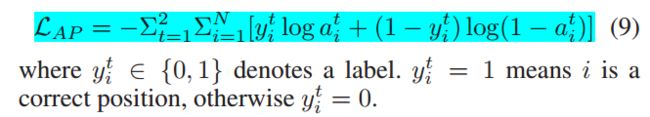
正如文章后面提到的,作者使用ROUGH-L标注了答案的开始和结束的位置。

Passage ranking
在这一节,作者从词级别到篇章级别来匹配问题和文章,首先使用问题r_Q来与篇章的每一个词进行attention计算,使用如下公式,获得新的文章表示r_P,也就是使用问题与文章中的单词做attention,将与问题相关的词汇的权重提升,做加和后是最终的文章表示r_P。

然后将问题的表示r_Q与篇章的表示r_P相连,过一个全连接层来获得一个匹配得分 :
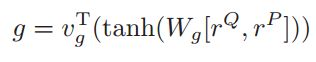
对于每一篇文章,获得一个文章匹配得分g_i,将所有的匹配得分做一个归一化,使用如下公式作为loss
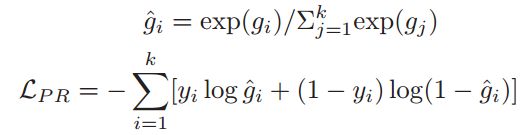
由于文章给出了是否 is_selected ,因此使用这个交叉熵作为损失函数。两个任务,一个是获得答案范围,另外一个是篇章rank,因此两个任务做一个多任务学习,因此使用一个简单的加权作为evidence extraction model的最终Loss。
![]()
接下来的一部分是答案生成模型:
Answer Synthesis
作者使用一个seq2seq model生成答案,首先使用双向GRU生成文章和问题的表示,在生成文章的表示时候加入了抽取的关键信息的特征,分别是word-embedding和开始与结束的位置,公式如下:
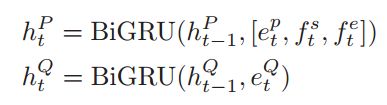
整个答案生成模型如下图所示:

作者使用GRU加decoder作为答案生成模型,在每一个解码阶段,作者使用GRU读取前一时刻的word embedding和前一时刻的生成的context vector来计算新的隐藏状态d_t,decoder部分的初始输入时使用了encoder部分问题和文章的反向末态最为输入。
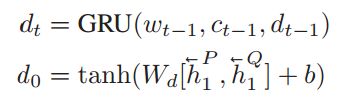
同样t时刻输出也是由一个attention机制计算出来的,使用的是上一时刻隐层状态和encoder部分的文章和问题的隐层状态的组合作为输入:
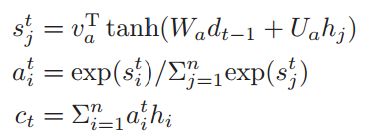
结合前一时刻的word embedding,这一时刻的输出向量和这一时刻的隐层状态,通过一个maxout隐层,在经过一个softmax来输出下一个单词:
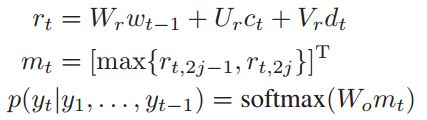
答案生成模型使用负似然对数作为损失函数:

实验部分
前面都是介绍数据的废话,从Implementation Details开始,首先为了标注答案的开始和结束,作者使用了ROUGH-L得分最高的作为答案所在范围进行训练,选择ROUGH-L分数高于0.7的作为训练集,因此最终训练集为71417条,答案生成方面使用ROUGH-L得分最高的范围作为关键信息(evidence),使用参考答案作为输出。
超参方面,使用Glove作为embedding mat,使用0作为oov words,隐层大小为150,dorpout 为0.1,r为0.8 r是啥-_-||
词典部分大小为3万,还行,未知词为
实验结果
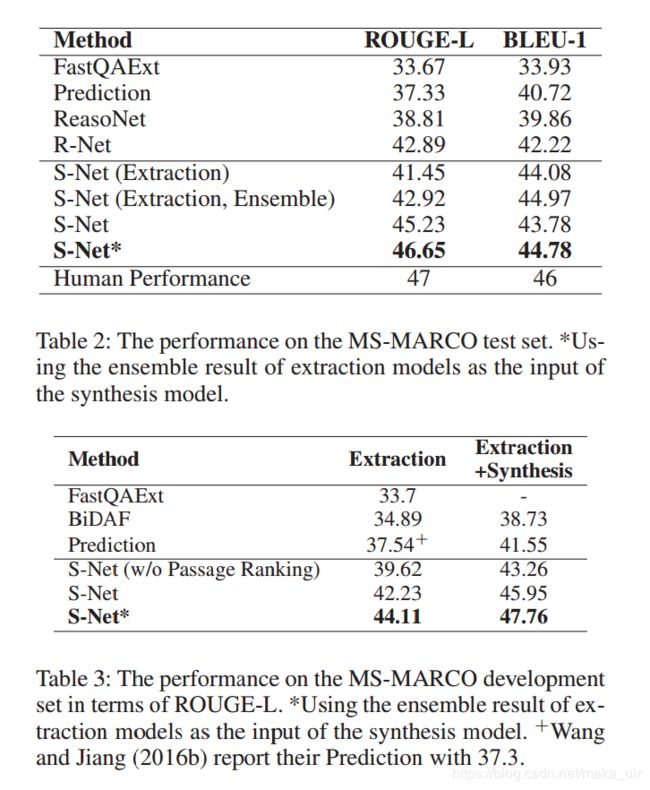
展望部分
作者认为他们只用了一个evidence作为生成模型的输入,没有组合更多的evidence,作者认为答案的开始和结束部分应该是类似的,因此希望在文章后续的发展过程中使用到这个特点