深度学习总结(lecture 11)Capsules Networks(CapsNet)
lecture 11:Capsules Networks(CapsNet)
目录
- lecture 11:Capsules Networks(CapsNet)
- 目录
- 1、胶囊网络
- 1.1 CNN有重要的缺点
- 1.2 将3D世界硬编码为神经网络:逆向图形方法
- 2、动态路由规划
- 2.1 背景
- 2.2 解决路由问题
- 2.3 网络构建
- 3、代码
- 1、胶囊网络
1、胶囊网络


1.1 CNN有重要的缺点
CNN(卷积神经网络)真棒。这是今天深度学习如此受欢迎的原因之一。他们可以做出令人惊叹的人们曾经认为计算机长期以来都无法做到的事情。尽管如此,它们有其局限性,有根本的缺陷。
让我们考虑一个非常简单和非技术性的例子。想象一张脸。组件是什么? 我们有椭圆形的脸,两只眼睛,一个鼻子和一个嘴巴。对于一个CNN来说,这些对象的存在可以成为认定图像中有一张脸的一个非常有力的指标。这些组件之间的定向关系和相对空间关系对CNN来说并不重要。

对CNN来说两幅图是相似的,因为它们包含相似的元素。
CNN如何工作?
- CNN的主要组成部分是一个卷积层 它的工作是检测图像像素中的重要特征。
- 较深层(接近输入)将学习检测诸如边缘和颜色渐变等简单特征
- 而更高层将简单特征组合成更复杂的特征。
- 最后,网络顶部的密集层将结合非常高级的特征并产生分类预测。
需要了解的重要一点是,更高级别的特征以加权和的方式将较低级特征组合:
(1)前一层的激活与下一层神经元的权重相乘并相加,然后传递到非线性激活。
(2)在这个设置中,没有任何地方在构成更高级特征的简单特征之间存在姿态(平移和旋转)关系。
(3)CNN解决这个问题的方法是使用最大池化或连续卷积层来减少流经网络的数据的空间大小,从而增加高层神经元的“视野”,从而允许他们检测输入图像的较大区域的高阶特征。
(4)最大的池化是一个使卷积网络工作得非常好的拐杖,在许多领域实现了超人的表现。
但是不要被它的表现所迷惑:
- 虽然CNN比之前的任何模式都要好,但是最大池化会失去有价值的信息。
- Hinton:“卷积神经网络中使用的池化操作是一个很大的错误,它运行得很好的事实是一场灾难。”
- 当然,你可以用传统的CNNs来替代最大的池化,但是仍然不能解决关键问题:
- 卷积神经网络的内部数据表示不考虑简单和复杂对象之间的重要空间层次。
在上面的例子中,图片中仅存在2只眼睛1张嘴巴和1只鼻子并不意味着有一张脸,我们也需要知道这些物体相对于彼此处于怎样的位置。
1.2 将3D世界硬编码为神经网络:逆向图形方法
计算机图形学涉及从几何数据的内部分层表示来构造可视图像。请注意,这种表示的结构需要考虑对象的相对位置。该内部表示作为表示这些对象的相对位置和方向的几何对象,以矩阵的阵列形式存储在计算机的存储器中。然后,特殊软件将该表示转换成屏幕上的图像。这就是所谓的渲染。





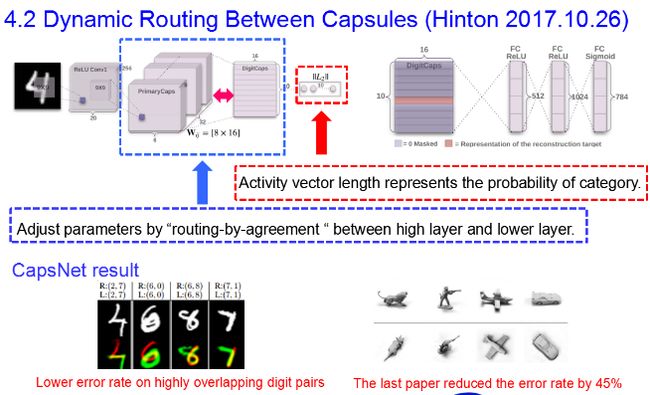
胶囊网络比其他模型要好得多,可以告诉上下行的图像是同一类,视角不同。 最新的论文使错误率降低了45%。
2、动态路由规划
2.1 背景
目前的神经网络中,每一层的神经元都做的是类似的事情,比如一个卷积层内的每个神经元都做的是一样的卷积操作。
- 而Hinton坚信,不同的神经元完全可以关注不同的实体或者属性,比如在一开始就有不同的神经元关注不同的类别(而不是到最后才有归一化分类)。
- 具体来说,有的神经元关注位置、有的关注尺寸、有的关注方向。这类似人类大脑中语言、视觉都有分别的区域负责,而不是分散在整个大脑中。
为了避免网络结构的杂乱无章,Hinton提出把关注同一个类别或者同一个属性的神经元打包集合在一起,好像胶囊一样。
- 在神经网络工作时,这些胶囊间的通路形成稀疏激活的树状结构(整个树中只有部分路径上的胶囊被激活),从而形成了他的Capsule理论。Capsule也就具有更好的解释性。
- 值得一提的是,同在谷歌大脑(但不在同一个办公室)的Jeff Dean也认为稀疏激活的神经网络是未来的重要发展方向,不知道他能不能也提出一些不同的实现方法来。
Capsule这样的网络结构在符合人们“一次认知多个属性”的直观感受的同时,也会带来另一个直观的问题,那就是不同的胶囊应该如何训练、又如何让网络自己决定胶囊间的激活关系。Hinton这篇论文解决的重点问题就是不同胶囊间连接权重(路由)的学习。
2.2 解决路由问题
- 首先,每个层中的神经元分组形成不同的胶囊,每个胶囊有一个“活动向量”activity vector,它是这个胶囊对于它关注的类别或者属性的表征。
- 树结构中的每个节点就对应着一个活动的胶囊。
- 通过一个迭代路由的过程,每个活动的胶囊都会从高一层网络中的胶囊中选择一个,让它成为自己的母节点。
- 对于高阶的视觉系统来说,这样的迭代过程就很有潜力解决一个物体的部分如何层层组合成整体的问题。
对于实体在网络中的表征,众多属性中有一个属性比较特殊,那就是它出现的概率(网络检测到某一类物体出现的置信度)。
- 一般典型的方式是用一个单独的、输出0到1之间的回归单元来表示,0就是没出现,1就是出现了。
- 在这篇论文中,Hinton想用活动向量同时表示一个实体是否出现以及这个实体的属性。
- 他的做法是用向量不同维度上的值分别表示不同的属性,然后用整个向量的模表示这个实体出现的概率。
- 为了保证向量的长度,也就是实体出现的概率不超过1,向量会通过一个非线性计算进行标准化,这样实体的不同属性也就实际上体现为了这个向量在高维空间中的方向。
采用这样的活动向量有一个很大的好处,就是可以帮助低层级的胶囊选择自己连接到哪个高层级的胶囊。具体做法是:
- 一开始低层级的胶囊会给所有高层级的胶囊提供输入;
- 然后这个低层级的胶囊会把自己的输出和一个权重矩阵相乘,得到一个预测向量。
- 如果预测向量和某个高层级胶囊的输出向量的标量积更大,就可以形成从上而下的反馈,提高这两个胶囊间的耦合系数,降低低层级胶囊和其它高层级胶囊间的耦合系数。
- 进行几次迭代后,贡献更大的低层级胶囊和接收它的贡献的高层级胶囊之间的连接就会占越来越重要的位置。
在论文作者们看来,这种“一致性路由”(routing-by-agreement)的方法要比之前最大池化之类只保留了唯一一个最活跃的特征的路由方法有效得多。
2.3 网络构建
作者们构建了一个简单的CapsNet。除最后一层外,网络的各层都是卷积层,但它们现在都是“胶囊”的层,其中用向量输出代替了CNN的标量特征输出、用一致性路由代替了最大池化。与CNN类似,更高层的网络观察了图像中更大的范围,不过由于不再是最大池化,所以位置信息一直都得到了保留。对于较低的层,空间位置的判断也只需要看是哪些胶囊被激活了。

这个网络中最底层的多维度胶囊结构就展现出了不同的特性,它们起到的作用就像传统计算机图形渲染中的不同元素一样,每一个胶囊关注自己的一部分特征。这和目前的计算机视觉任务中,把图像中不同空间位置的元素组合起来形成整体理解(或者说图像中的每个区域都会首先激活整个网络然后再进行组合)具有截然不同的计算特性。在底层的胶囊之后连接了PrimaryCaps层和DigitCaps层。
3、代码
capsulelayers.py
import keras.backend as K
import tensorflow as tf
from keras import initializers, layers
class Length(layers.Layer):
"""
Compute the length of vectors. This is used to compute a Tensor that has the same shape with y_true in margin_loss.
Using this layer as model's output can directly predict labels by using `y_pred = np.argmax(model.predict(x), 1)`
inputs: shape=[None, num_vectors, dim_vector]
output: shape=[None, num_vectors]
"""
def call(self, inputs, **kwargs):
return K.sqrt(K.sum(K.square(inputs), -1))
def compute_output_shape(self, input_shape):
return input_shape[:-1]
class Mask(layers.Layer):
"""
Mask a Tensor with shape=[None, num_capsule, dim_vector] either by the capsule with max length or by an additional
input mask. Except the max-length capsule (or specified capsule), all vectors are masked to zeros. Then flatten the
masked Tensor.
For example:
```
x = keras.layers.Input(shape=[8, 3, 2]) # batch_size=8, each sample contains 3 capsules with dim_vector=2
y = keras.layers.Input(shape=[8, 3]) # True labels. 8 samples, 3 classes, one-hot coding.
out = Mask()(x) # out.shape=[8, 6]
# or
out2 = Mask()([x, y]) # out2.shape=[8,6]. Masked with true labels y. Of course y can also be manipulated.
```
"""
def call(self, inputs, **kwargs):
if type(inputs) is list: # true label is provided with shape = [None, n_classes], i.e. one-hot code.
assert len(inputs) == 2
inputs, mask = inputs
else: # if no true label, mask by the max length of capsules. Mainly used for prediction
# compute lengths of capsules
x = K.sqrt(K.sum(K.square(inputs), -1))
# generate the mask which is a one-hot code.
# mask.shape=[None, n_classes]=[None, num_capsule]
mask = K.one_hot(indices=K.argmax(x, 1), num_classes=x.get_shape().as_list()[1])
# inputs.shape=[None, num_capsule, dim_capsule]
# mask.shape=[None, num_capsule]
# masked.shape=[None, num_capsule * dim_capsule]
masked = K.batch_flatten(inputs * K.expand_dims(mask, -1))
return masked
def compute_output_shape(self, input_shape):
if type(input_shape[0]) is tuple: # true label provided
return tuple([None, input_shape[0][1] * input_shape[0][2]])
else: # no true label provided
return tuple([None, input_shape[1] * input_shape[2]])
def squash(vectors, axis=-1):
"""
The non-linear activation used in Capsule. It drives the length of a large vector to near 1 and small vector to 0
:param vectors: some vectors to be squashed, N-dim tensor
:param axis: the axis to squash
:return: a Tensor with same shape as input vectors
"""
s_squared_norm = K.sum(K.square(vectors), axis, keepdims=True)
scale = s_squared_norm / (1 + s_squared_norm) / K.sqrt(s_squared_norm + K.epsilon())
return scale * vectors
class CapsuleLayer(layers.Layer):
"""
The capsule layer. It is similar to Dense layer. Dense layer has `in_num` inputs, each is a scalar, the output of the
neuron from the former layer, and it has `out_num` output neurons. CapsuleLayer just expand the output of the neuron
from scalar to vector. So its input shape = [None, input_num_capsule, input_dim_capsule] and output shape = \
[None, num_capsule, dim_capsule]. For Dense Layer, input_dim_capsule = dim_capsule = 1.
:param num_capsule: number of capsules in this layer
:param dim_capsule: dimension of the output vectors of the capsules in this layer
:param routings: number of iterations for the routing algorithm
"""
def __init__(self, num_capsule, dim_capsule, routings=3,
kernel_initializer='glorot_uniform',
**kwargs):
super(CapsuleLayer, self).__init__(**kwargs)
self.num_capsule = num_capsule
self.dim_capsule = dim_capsule
self.routings = routings
self.kernel_initializer = initializers.get(kernel_initializer)
def build(self, input_shape):
assert len(input_shape) >= 3, "The input Tensor should have shape=[None, input_num_capsule, input_dim_capsule]"
self.input_num_capsule = input_shape[1]
self.input_dim_capsule = input_shape[2]
# Transform matrix
self.W = self.add_weight(shape=[self.num_capsule, self.input_num_capsule,
self.dim_capsule, self.input_dim_capsule],
initializer=self.kernel_initializer,
name='W')
self.built = True
def call(self, inputs, training=None):
# inputs.shape=[None, input_num_capsule, input_dim_capsule]
# inputs_expand.shape=[None, 1, input_num_capsule, input_dim_capsule]
inputs_expand = K.expand_dims(inputs, 1)
# Replicate num_capsule dimension to prepare being multiplied by W
# inputs_tiled.shape=[None, num_capsule, input_num_capsule, input_dim_capsule]
inputs_tiled = K.tile(inputs_expand, [1, self.num_capsule, 1, 1])
# Compute `inputs * W` by scanning inputs_tiled on dimension 0.
# x.shape=[num_capsule, input_num_capsule, input_dim_capsule]
# W.shape=[num_capsule, input_num_capsule, dim_capsule, input_dim_capsule]
# Regard the first two dimensions as `batch` dimension,
# then matmul: [input_dim_capsule] x [dim_capsule, input_dim_capsule]^T -> [dim_capsule].
# inputs_hat.shape = [None, num_capsule, input_num_capsule, dim_capsule]
inputs_hat = K.map_fn(lambda x: K.batch_dot(x, self.W, [2, 3]), elems=inputs_tiled)
# Begin: Routing algorithm ---------------------------------------------------------------------#
# The prior for coupling coefficient, initialized as zeros.
# b.shape = [None, self.num_capsule, self.input_num_capsule].
b = tf.zeros(shape=[K.shape(inputs_hat)[0], self.num_capsule, self.input_num_capsule])
assert self.routings > 0, 'The routings should be > 0.'
for i in range(self.routings):
# c.shape=[batch_size, num_capsule, input_num_capsule]
c = tf.nn.softmax(b, dim=1)
# c.shape = [batch_size, num_capsule, input_num_capsule]
# inputs_hat.shape=[None, num_capsule, input_num_capsule, dim_capsule]
# The first two dimensions as `batch` dimension,
# then matmal: [input_num_capsule] x [input_num_capsule, dim_capsule] -> [dim_capsule].
# outputs.shape=[None, num_capsule, dim_capsule]
outputs = squash(K.batch_dot(c, inputs_hat, [2, 2])) # [None, 10, 16]
if i < self.routings - 1:
# outputs.shape = [None, num_capsule, dim_capsule]
# inputs_hat.shape=[None, num_capsule, input_num_capsule, dim_capsule]
# The first two dimensions as `batch` dimension,
# then matmal: [dim_capsule] x [input_num_capsule, dim_capsule]^T -> [input_num_capsule].
# b.shape=[batch_size, num_capsule, input_num_capsule]
b += K.batch_dot(outputs, inputs_hat, [2, 3])
# End: Routing algorithm -----------------------------------------------------------------------#
return outputs
def compute_output_shape(self, input_shape):
return tuple([None, self.num_capsule, self.dim_capsule])
def PrimaryCap(inputs, dim_capsule, n_channels, kernel_size, strides, padding):
"""
Apply Conv2D `n_channels` times and concatenate all capsules
:param inputs: 4D tensor, shape=[None, width, height, channels]
:param dim_capsule: the dim of the output vector of capsule
:param n_channels: the number of types of capsules
:return: output tensor, shape=[None, num_capsule, dim_capsule]
"""
output = layers.Conv2D(filters=dim_capsule*n_channels, kernel_size=kernel_size, strides=strides, padding=padding,
name='primarycap_conv2d')(inputs)
outputs = layers.Reshape(target_shape=[-1, dim_capsule], name='primarycap_reshape')(output)
return layers.Lambda(squash, name='primarycap_squash')(outputs)
capsulenet.py
import numpy as np
from keras import layers, models, optimizers
from keras import backend as K
from keras.utils import to_categorical
import matplotlib.pyplot as plt
from utils import combine_images
from PIL import Image
from capsulelayers import CapsuleLayer, PrimaryCap, Length, Mask
K.set_image_data_format('channels_last')
from resnets_utils import *
def CapsNet(input_shape, n_class, routings):
"""
A Capsule Network on MNIST.
:param input_shape: data shape, 3d, [width, height, channels]
:param n_class: number of classes
:param routings: number of routing iterations
:return: Two Keras Models, the first one used for training, and the second one for evaluation.
`eval_model` can also be used for training.
"""
x = layers.Input(shape=input_shape)
# Layer 1: Just a conventional Conv2D layer
conv1 = layers.Conv2D(filters=32, kernel_size=5, strides=1, padding='valid', activation='relu', name='conv1')(x)
# Layer 2: Conv2D layer with `squash` activation, then reshape to [None, num_capsule, dim_capsule]
primarycaps = PrimaryCap(conv1, dim_capsule=8, n_channels=16, kernel_size=9, strides=2, padding='valid')
# Layer 3: Capsule layer. Routing algorithm works here.
digitcaps = CapsuleLayer(num_capsule=n_class, dim_capsule=12, routings=routings,
name='digitcaps')(primarycaps)
# Layer 4: This is an auxiliary layer to replace each capsule with its length. Just to match the true label's shape.
# If using tensorflow, this will not be necessary. :)
out_caps = Length(name='capsnet')(digitcaps)
# Decoder network.
y = layers.Input(shape=(n_class,))
masked_by_y = Mask()([digitcaps, y]) # The true label is used to mask the output of capsule layer. For training
masked = Mask()(digitcaps) # Mask using the capsule with maximal length. For prediction
# Shared Decoder model in training and prediction
decoder = models.Sequential(name='decoder')
decoder.add(layers.Dense(64, activation='relu', input_dim=12*n_class))
decoder.add(layers.Dense(32, activation='relu'))
decoder.add(layers.Dense(np.prod(input_shape), activation='sigmoid'))
decoder.add(layers.Reshape(target_shape=input_shape, name='out_recon'))
# Models for training and evaluation (prediction)
train_model = models.Model([x, y], [out_caps, decoder(masked_by_y)])
eval_model = models.Model(x, [out_caps, decoder(masked)])
# manipulate model
noise = layers.Input(shape=(n_class, 12))
noised_digitcaps = layers.Add()([digitcaps, noise])
masked_noised_y = Mask()([noised_digitcaps, y])
manipulate_model = models.Model([x, y, noise], decoder(masked_noised_y))
return train_model, eval_model, manipulate_model
def margin_loss(y_true, y_pred):
"""
Margin loss for Eq.(4). When y_true[i, :] contains not just one `1`, this loss should work too. Not test it.
:param y_true: [None, n_classes]
:param y_pred: [None, num_capsule]
:return: a scalar loss value.
"""
L = y_true * K.square(K.maximum(0., 0.9 - y_pred)) + \
0.5 * (1 - y_true) * K.square(K.maximum(0., y_pred - 0.1))
return K.mean(K.sum(L, 1))
def train(model, data, args):
"""
Training a CapsuleNet
:param model: the CapsuleNet model
:param data: a tuple containing training and testing data, like `((x_train, y_train), (x_test, y_test))`
:param args: arguments
:return: The trained model
"""
# unpacking the data
(x_train, y_train), (x_test, y_test) = data
# callbacks
log = callbacks.CSVLogger(args.save_dir + '/log.csv')
tb = callbacks.TensorBoard(log_dir=args.save_dir + '/tensorboard-logs',
batch_size=args.batch_size, histogram_freq=int(args.debug))
checkpoint = callbacks.ModelCheckpoint(args.save_dir + '/weights-{epoch:02d}.h5', monitor='val_capsnet_acc',
save_best_only=True, save_weights_only=True, verbose=1)
lr_decay = callbacks.LearningRateScheduler(schedule=lambda epoch: args.lr * (args.lr_decay ** epoch))
# compile the model
model.compile(optimizer=optimizers.Adam(lr=args.lr),
loss=[margin_loss, 'mse'],
loss_weights=[1., args.lam_recon],
metrics={'capsnet': 'accuracy'})
"""
# Training without data augmentation:
model.fit([x_train, y_train], [y_train, x_train], batch_size=args.batch_size, epochs=args.epochs,
validation_data=[[x_test, y_test], [y_test, x_test]], callbacks=[log, tb, checkpoint, lr_decay])
"""
# Begin: Training with data augmentation ---------------------------------------------------------------------#
def train_generator(x, y, batch_size, shift_fraction=0.):
train_datagen = ImageDataGenerator(width_shift_range=shift_fraction,
height_shift_range=shift_fraction) # shift up to 2 pixel for MNIST
generator = train_datagen.flow(x, y, batch_size=batch_size)
while 1:
x_batch, y_batch = generator.next()
yield ([x_batch, y_batch], [y_batch, x_batch])
# Training with data augmentation. If shift_fraction=0., also no augmentation.
model.fit_generator(generator=train_generator(x_train, y_train, args.batch_size, args.shift_fraction),
steps_per_epoch=int(y_train.shape[0] / args.batch_size),
epochs=args.epochs,
validation_data=[[x_test, y_test], [y_test, x_test]],
callbacks=[log, tb, checkpoint, lr_decay])
# End: Training with data augmentation -----------------------------------------------------------------------#
model.save_weights(args.save_dir + '/trained_model.h5')
print('Trained model saved to \'%s/trained_model.h5\'' % args.save_dir)
from utils import plot_log
plot_log(args.save_dir + '/log.csv', show=True)
return model
def test(model, data, args):
x_test, y_test = data
y_pred, x_recon = model.predict(x_test, batch_size=32)
print('-'*30 + 'Begin: test' + '-'*30)
print('Test acc:', np.sum(np.argmax(y_pred, 1) == np.argmax(y_test, 1))/y_test.shape[0])
img = combine_images(np.concatenate([x_test[:50],x_recon[:50]]))
image = img * 255
Image.fromarray(image.astype(np.uint8)).save(args.save_dir + "/real_and_recon.png")
print()
print('Reconstructed images are saved to %s/real_and_recon.png' % args.save_dir)
print('-' * 30 + 'End: test' + '-' * 30)
plt.imshow(plt.imread(args.save_dir + "/real_and_recon.png"))
plt.show()
def manipulate_latent(model, data, args):
print('-'*30 + 'Begin: manipulate' + '-'*30)
x_test, y_test = data
index = np.argmax(y_test, 1) == args.digit
number = np.random.randint(low=0, high=sum(index) - 1)
x, y = x_test[index][number], y_test[index][number]
x, y = np.expand_dims(x, 0), np.expand_dims(y, 0)
noise = np.zeros([1, 6, 12])
x_recons = []
for dim in range(16):
for r in [-0.25, -0.2, -0.15, -0.1, -0.05, 0, 0.05, 0.1, 0.15, 0.2, 0.25]:
tmp = np.copy(noise)
tmp[:,:,dim] = r
x_recon = model.predict([x, y, tmp])
x_recons.append(x_recon)
x_recons = np.concatenate(x_recons)
img = combine_images(x_recons, height=12)
image = img*255
Image.fromarray(image.astype(np.uint8)).save(args.save_dir + '/manipulate-%d.png' % args.digit)
print('manipulated result saved to %s/manipulate-%d.png' % (args.save_dir, args.digit))
print('-' * 30 + 'End: manipulate' + '-' * 30)
def load_mnist():
# the data, shuffled and split between train and test sets
# the data, shuffled and split between train and test sets
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
# 将数据归一化,标签one-hot
x_train = X_train_orig/255.
x_test = X_test_orig/255.
y_train = convert_to_one_hot(Y_train_orig, 6).T
y_test = convert_to_one_hot(Y_test_orig, 6).T
print(x_train.shape, y_train.shape)
return (x_train, y_train), (x_test, y_test)
if __name__ == "__main__":
import os
import argparse
from keras.preprocessing.image import ImageDataGenerator
from keras import callbacks
# setting the hyper parameters
parser = argparse.ArgumentParser(description="Capsule Network on MNIST.")
parser.add_argument('--epochs', default=20, type=int)
parser.add_argument('--batch_size', default=32, type=int)
parser.add_argument('--lr', default=0.001, type=float,
help="Initial learning rate")
parser.add_argument('--lr_decay', default=0.9, type=float,
help="The value multiplied by lr at each epoch. Set a larger value for larger epochs")
parser.add_argument('--lam_recon', default=0.392, type=float,
help="The coefficient for the loss of decoder")
parser.add_argument('-r', '--routings', default=3, type=int,
help="Number of iterations used in routing algorithm. should > 0")
parser.add_argument('--shift_fraction', default=0.1, type=float,
help="Fraction of pixels to shift at most in each direction.")
parser.add_argument('--debug', action='store_true',
help="Save weights by TensorBoard")
parser.add_argument('--save_dir', default='./result')
parser.add_argument('-t', '--testing', action='store_true',
help="Test the trained model on testing dataset")
parser.add_argument('--digit', default=5, type=int,
help="Digit to manipulate")
parser.add_argument('-w', '--weights', default=None,
help="The path of the saved weights. Should be specified when testing")
args = parser.parse_args()
print(args)
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
# load data
(x_train, y_train), (x_test, y_test) = load_mnist()
# define model
model, eval_model, manipulate_model = CapsNet(input_shape=x_train.shape[1:],
n_class=len(np.unique(np.argmax(y_train, 1))),
routings=args.routings)
model.summary()
# train or test
if args.weights is not None: # init the model weights with provided one
model.load_weights(args.weights)
if not args.testing:
train(model=model, data=((x_train, y_train), (x_test, y_test)), args=args)
else: # as long as weights are given, will run testing
if args.weights is None:
print('No weights are provided. Will test using random initialized weights.')
manipulate_latent(manipulate_model, (x_test, y_test), args)
test(model=eval_model, data=(x_test, y_test), args=args)