ELK集群搭建(一)
ELK集群部署(一)
ELK 是 elastic 公司旗下三款产品ElasticSearch、Logstash、Kibana的首字母组合,也即Elastic Stack包含ElasticSearch、Logstash、Kibana、Beats。ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统。
ElasticSearch 一个基于 JSON 的分布式的搜索和分析引擎,作为 ELK 的核心,它集中存储数据,
用来搜索、分析、存储日志。它是分布式的,可以横向扩容,可以自动发现,索引自动分片
Logstash 一个动态数据收集管道,支持以 TCP/UDP/HTTP 多种方式收集数据(也可以接受 Beats 传输来的数据),
并对数据做进一步丰富或提取字段处理。用来采集日志,把日志解析为json格式交给ElasticSearch
Kibana 一个数据可视化组件,将收集的数据进行可视化展示(各种报表、图形化数据),并提供配置、管理 ELK 的界面
Beats 一个轻量型日志采集器,单一用途的数据传输平台,可以将多台机器的数据发送到 Logstash 或 ElasticSearch
X-Pack 一个对Elastic Stack提供了安全、警报、监控、报表、图表于一身的扩展包,不过收费
官网:https://www.elastic.co/cn/ ,中文文档:https://elkguide.elasticsearch.cn/
下载elk各组件的旧版本:
https://www.elastic.co/downloads/past-releases
环境准备
- 角色划分:
系统:CentOS 7
es主节点/es数据节点/kibana/head 192.168.30.128
es主节点/es数据节点/logstash 192.168.30.129
es主节点/es数据节点/filebeat 192.168.30.130
- 全部关闭防火墙和selinux:
# systemctl stop firewalld && systemctl disable firewalld
# sed -i 's/=enforcing/=disabled/g' /etc/selinux/config && setenforce 0
- 全部配置系统环境:
# vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
# vim /etc/sysctl.conf
vm.max_map_count=655360
# sysctl -p
- 全部安装Java环境:
# mkdir /software && cd /software #将所有安装包放到该目录下
# tar zxf jdk-8u191-linux-x64.tar.gz && mv jdk1.8.0_191/ /usr/local/jdk
# vim /etc/profile
JAVA_HOME=/usr/local/jdk
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib
export JAVA_HOME PATH CLASSPATH
# source !$
# java -version
# ln -s /usr/local/jdk/bin/java /usr/local/bin/java
- 安装node.js:
192.168.30.128
因为head插件是用node.js开发的,所以需要此环境。官网下载
# tar -Jxf node-v10.15.3-linux-x64.tar.xz && mv node-v10.15.3-linux-x64/ /usr/local/node
# vim /etc/profile
export NODE_HOME=/usr/local/node
export PATH=$NODE_HOME/bin:$PATH
export NODE_PATH=$NODE_HOME/lib/node_modules:$PATH
# source !$
# node -v
- 安装head插件:
192.168.30.128
# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
# unzip master.zip && mv elasticsearch-head-master/ /usr/local/elasticsearch-head
# cd /usr/local/elasticsearch-head
# npm install -g cnpm --registry=https://registry.npm.taobao.org
# cnpm install -g grunt-cli
# cnpm install -g grunt
# cnpm install grunt-contrib-clean
# cnpm install grunt-contrib-concat
# cnpm install grunt-contrib-watch
# cnpm install grunt-contrib-connect
# cnpm install grunt-contrib-copy
# cnpm install grunt-contrib-jasmine #若报错就再执行一遍
# vim /usr/local/elasticsearch-head/Gruntfile.js
#找到下面connect属性,新增 hostname: '0.0.0.0',
connect: {
server: {
options: {
hostname: '0.0.0.0', #不要忘了后面的逗号
port: 9100,
base: '.',
keepalive: true
}
}
}
后台启动grunt server
# cd /usr/local/elasticsearch-head
# nohup grunt server &
# eval "cd /usr/local/elasticsearch-head/ ; nohup npm run start >/dev/null 2>&1 & "
打开浏览器访问192.168.30.128:9100,可以看到head页面
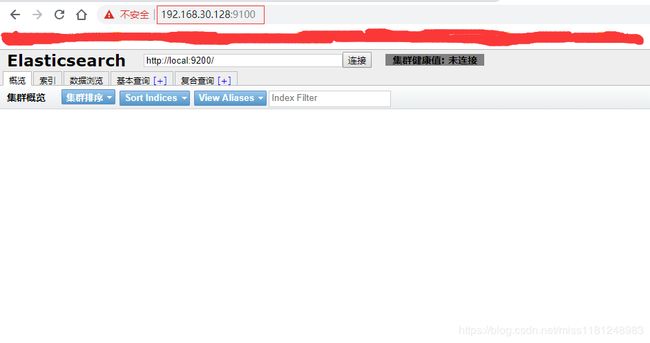
因为还没有部署elasticsearch集群,所以没有任何数据。
- 启动脚本:
为了后续方便,给head做个启动脚本。
# vim /usr/bin/elasticsearch-head
#!/bin/bash
#chkconfig: 2345 55 24
#description: elasticsearch-head service manager
data="cd /usr/local/elasticsearch-head/ ; nohup npm run start >/dev/null 2>&1 & "
START() {
eval $data
}
STOP() {
ps -ef | grep grunt | grep -v "grep" | awk '{print $2}' | xargs kill -s 9 >/dev/null
}
case "$1" in
start)
START
;;
stop)
STOP
;;
restart)
STOP
sleep 2
START
;;
*)
echo "Usage: elasticsearch-head (|start|stop|restart)"
;;
esac
# chmod +x /usr/bin/elasticsearch-head
elasticsearch
- 全部创建用户elk:
# useradd elk
- 全部安装elasticsearch:
# cd /software
# tar zxf elasticsearch-6.7.1.tar.gz && mv elasticsearch-6.7.1 /usr/local/elasticsearch
# mkdir /usr/local/elasticsearch/data
# chown -R elk:elk /usr/local/elasticsearch
- 全部修改配置:
192.168.30.128
# vim /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: elk #集群名,同一集群必须相同
node.name: elk-128 #指定节点主机名
node.master: true #允许成为主节点
node.data: true #数据节点
path.data: /usr/local/elasticsearch/data #数据存放路径
path.logs: /usr/local/elasticsearch/logs #日志路径
bootstrap.memory_lock: false #关闭锁定内存,设置为true会报错
network.host: 192.168.30.128 #监听ip
http.port: 9200 #http端口
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.30.128", "192.168.30.129", "192.168.30.130"] #初始主机列表
discovery.zen.minimum_master_nodes: 2 # n/2+1
http.enabled: true #使用http协议对外提供服务
http.cors.enabled: true #允许head插件访问es
http.cors.allow-origin: "*"
192.168.30.129
# vim /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: elk
node.name: elk-129
node.master: true
node.data: true
path.data: /usr/local/elasticsearch/data
path.logs: /usr/local/elasticsearch/logs
bootstrap.memory_lock: false
network.host: 192.168.30.129
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.30.128", "192.168.30.129", "192.168.30.130"]
discovery.zen.minimum_master_nodes: 2
http.enabled: true
http.cors.enabled: true
http.cors.allow-origin: "*"
192.168.30.130
# vim /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: elk
node.name: elk-130
node.master: true
node.data: true
path.data: /usr/local/elasticsearch/data
path.logs: /usr/local/elasticsearch/logs
bootstrap.memory_lock: false
network.host: 192.168.30.130
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.30.128", "192.168.30.129", "192.168.30.130"]
discovery.zen.minimum_master_nodes: 2
http.enabled: true
http.cors.enabled: true
http.cors.allow-origin: "*"
尽量将所有机器设置为允许成为主节点和数据节点,除非机器负载很高。
- 解决
bootstrap.memory_lock: true报错:
# vim /etc/security/limits.conf
baoshan soft memlock unlimited
baoshan hard memlock unlimited
# vim /etc/sysctl.conf
vm.swappiness=0
# reboot
生产环境建议设置该项为true
- 全部启动elasticsearch:
# su - elk -c "/usr/local/elasticsearch/bin/elasticsearch -d"
# tail -f /usr/local/elasticsearch/logs/elk.log #查看日志,是否正常启动
- 查看集群健康状态:
# curl '192.168.30.128:9200/_cluster/health?pretty'
{
"cluster_name" : "elk",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
# curl '192.168.30.129:9200/_cluster/health?pretty'
# curl '192.168.30.130:9200/_cluster/health?pretty' #返回结果与上面一致
- 查看master节点:
# curl '192.168.30.130:9200/_cat/master?v'
id host ip node
iytvSXOIRIKBwYMAKd6EAg 192.168.30.129 192.168.30.129 elk-129
# curl '192.168.30.129:9200/_cat/master?v'
# curl '192.168.30.128:9200/_cat/master?v' #返回结果与上面一致
- 查看集群详细信息:
# curl '192.168.30.128:9200/_cluster/state?pretty'
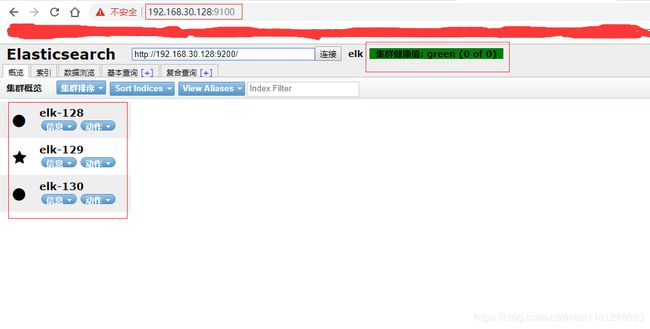
打开head页面,连接集群任一节点地址,如192.168.30.128:9200,查看集群
- 配置elasticsearch服务:
服务配置文件
# vim /etc/sysconfig/elasticsearch
################################
# Elasticsearch
################################
# Elasticsearch home directory
#ES_HOME=/usr/share/elasticsearch
ES_HOME=/usr/local/elasticsearch
# Elasticsearch Java path
#JAVA_HOME=
JAVA_HOME=/usr/local/jdk
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib
# Elasticsearch configuration directory
#ES_PATH_CONF=/etc/elasticsearch
ES_PATH_CONF=/usr/local/elasticsearch/config
# Elasticsearch PID directory
#PID_DIR=/var/run/elasticsearch
PID_DIR=/usr/local/elasticsearch/run
# Additional Java OPTS
#ES_JAVA_OPTS=
# Configure restart on package upgrade (true, every other setting will lead to not restarting)
#RESTART_ON_UPGRADE=true
################################
# Elasticsearch service
################################
# SysV init.d
#
# The number of seconds to wait before checking if Elasticsearch started successfully as a daemon process
ES_STARTUP_SLEEP_TIME=5
################################
# System properties
################################
# Specifies the maximum file descriptor number that can be opened by this process
# When using Systemd, this setting is ignored and the LimitNOFILE defined in
# /usr/lib/systemd/system/elasticsearch.service takes precedence
#MAX_OPEN_FILES=65535
# The maximum number of bytes of memory that may be locked into RAM
# Set to "unlimited" if you use the 'bootstrap.memory_lock: true' option
# in elasticsearch.yml.
# When using systemd, LimitMEMLOCK must be set in a unit file such as
# /etc/systemd/system/elasticsearch.service.d/override.conf.
#MAX_LOCKED_MEMORY=unlimited
# Maximum number of VMA (Virtual Memory Areas) a process can own
# When using Systemd, this setting is ignored and the 'vm.max_map_count'
# property is set at boot time in /usr/lib/sysctl.d/elasticsearch.conf
#MAX_MAP_COUNT=262144
服务文件
# vim /usr/lib/systemd/system/elasticsearch.service
[Unit]
Description=Elasticsearch
Documentation=http://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
RuntimeDirectory=elasticsearch
PrivateTmp=true
Environment=ES_HOME=/usr/local/elasticsearch
Environment=ES_PATH_CONF=/usr/local/elasticsearch/config
Environment=PID_DIR=/usr/local/elasticsearch/run
EnvironmentFile=-/etc/sysconfig/elasticsearch
WorkingDirectory=/usr/local/elasticsearch
User=elk
Group=elk
ExecStart=/usr/local/elasticsearch/bin/elasticsearch -p ${PID_DIR}/elasticsearch.pid --quiet
# StandardOutput is configured to redirect to journalctl since
# some error messages may be logged in standard output before
# elasticsearch logging system is initialized. Elasticsearch
# stores its logs in /var/log/elasticsearch and does not use
# journalctl by default. If you also want to enable journalctl
# logging, you can simply remove the "quiet" option from ExecStart.
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65535
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
# Built for packages-6.7.1 (packages)
- 管理服务:
# chmod +x /usr/lib/systemd/system/elasticsearch.service
# mkdir /usr/local/elasticsearch/run
# touch /usr/local/elasticsearch/run/elasticsearch.pid && chown -R elk:elk /usr/local/elasticsearch
# systemctl daemon-reload
# systemctl enable elasticsearch
# systemctl start elasticsearch #先kill之前的elasticsearch进程
# yum install -y bash-completion && source /etc/profile #命令自动补全
kibana
192.168.30.128
- 安装kibana:
# tar zxf kibana-6.7.1-linux-x86_64.tar.gz && mv kibana-6.7.1-linux-x86_64 /usr/local/kibana
- 修改配置:
# vim /usr/local/kibana/config/kibana.yml
server.port: 5601 #监听端口
server.host: "0.0.0.0" #监听IP
elasticsearch.hosts: ["http://192.168.30.128:9200","http://192.168.30.129:9200","http://192.168.30.130:9200"] #集群es地址
logging.dest: /usr/local/kibana/logs/kibana.log #日志路径
kibana.index: ".kibana" #默认索引
# mkdir /usr/local/kibana/logs && touch /usr/local/kibana/logs/kibana.log
- 启动kibana:
# /usr/local/kibana/bin/kibana &
- 配置成kibana服务:
服务配置文件
# vim /etc/default/kibana
user="elk"
group="elk"
chroot="/"
chdir="/"
nice=""
# If this is set to 1, then when `stop` is called, if the process has
# not exited within a reasonable time, SIGKILL will be sent next.
# The default behavior is to simply log a message "program stop failed; still running"
KILL_ON_STOP_TIMEOUT=0
服务文件
# vim /etc/systemd/system/kibana.service
[Unit]
Description=Kibana
StartLimitIntervalSec=30
StartLimitBurst=3
[Service]
Type=simple
User=elk
Group=elk
# Load env vars from /etc/default/ and /etc/sysconfig/ if they exist.
# Prefixing the path with '-' makes it try to load, but if the file doesn't
# exist, it continues onward.
EnvironmentFile=-/etc/default/kibana
EnvironmentFile=-/etc/sysconfig/kibana
ExecStart=/usr/local/kibana/bin/kibana "-c /usr/local/kibana/config/kibana.yml"
Restart=always
WorkingDirectory=/
[Install]
WantedBy=multi-user.target
- 管理服务:
# chown -R elk:elk /usr/local/kibana
# systemctl daemon-reload
# systemctl enable kibana
# systemctl start kibana #先kill之前的kibana进程
- kibana汉化:
github地址:kibana汉化
# unzip Kibana_Hanization-master.zip
# cp -r Kibana_Hanization-master/translations/ /usr/local/kibana/src/legacy/core_plugins/kibana/
# vim /usr/local/kibana/config/kibana.yml #更改配置
i18n.locale: "zh_CN"
# systemctl restart kibana
这里针对tar包安装的kibana路径,yum安装应该是/usr/share/kibana/src/legacy/core_plugins/kibana/目录。
访问网页192.168.30.128:5601,可以看到汉化之后的kibana页面

logstash
192.168.30.129
- 安装logstash:
# tar zxf logstash-6.7.1.tar.gz && mv logstash-6.7.1/ /usr/local/logstash
# mkdir /usr/local/logstash/conf.d
- 修改配置:
# vim /usr/local/logstash/config/logstash.yml
http.host: "192.168.30.129"
http.port: 9600
- 以收集nginx 访问日志为例:
# yum install -y nginx
# vim /etc/nginx/nginx.conf
log_format main2 '$http_host $remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$upstream_addr" $request_time';
# vim /etc/nginx/conf.d/elk.conf
server {
listen 80;
server_name elk.test.com;
location / {
proxy_pass http://192.168.30.128:5601;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
access_log /var/log/nginx/elk_access.log main2;
}
# vim /usr/local/logstash/conf.d/nginx_access.conf
input {
file {
path => "/var/log/nginx/elk_access.log" #设置为nginx访问日志的路径
start_position => "beginning"
type => "nginx"
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:http_host} %{IPORHOST:clientip} - %{USERNAME:remote_user} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:http_verb} %{NOTSPACE:http_request}(?: HTTP/%{NUMBER:http_version})?|%{DATA:raw_http_request})\" %{NUMBER:response} (?:%{NUMBER:bytes_read}|-) %{QS:referrer} %{QS:agent} %{QS:xforwardedfor} %{NUMBER:request_time:float}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.30.129:9200"] #也可以为集群内其它机器的地址
index => "nginx-test-%{+YYYY.MM.dd}"
}
}
- 启动logstash:
# systemctl start nginx
# nohup /usr/local/logstash/bin/logstash --path.settings /usr/local/logstash/ -f /usr/local/logstash/conf.d/nginx_access.conf &
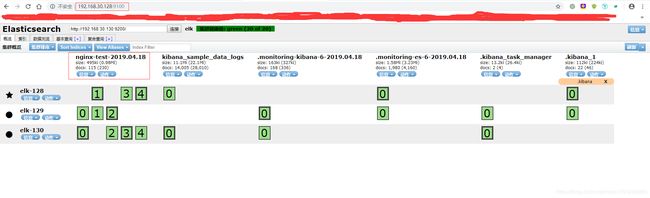
查看elasticsearch-head页面
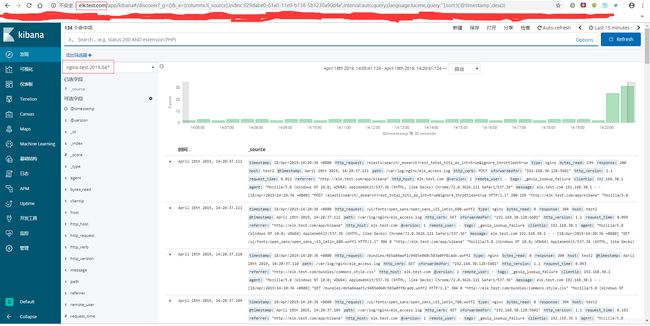
到kibana页面创建索引,查看访问日志
- 配置logstash服务:
服务配置文件
# vim /etc/default/logstash
LS_HOME="/usr/local/logstash"
LS_SETTINGS_DIR="/usr/local/logstash"
LS_PIDFILE="/usr/local/logstash/run/logstash.pid"
LS_USER="elk"
LS_GROUP="elk"
LS_GC_LOG_FILE="/usr/local/logstash/logs/gc.log"
LS_OPEN_FILES="16384"
LS_NICE="19"
SERVICE_NAME="logstash"
SERVICE_DESCRIPTION="logstash"
服务文件
# vim /etc/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
Type=simple
User=elk
Group=elk
# Load env vars from /etc/default/ and /etc/sysconfig/ if they exist.
# Prefixing the path with '-' makes it try to load, but if the file doesn't
# exist, it continues onward.
EnvironmentFile=-/etc/default/logstash
EnvironmentFile=-/etc/sysconfig/logstash
ExecStart=/usr/local/logstash/bin/logstash "--path.settings" "/usr/local/logstash/config" "--path.config" "/usr/local/logstash/conf.d"
Restart=always
WorkingDirectory=/
Nice=19
LimitNOFILE=16384
[Install]
WantedBy=multi-user.target
- 管理服务:
# mkdir /usr/local/logstash/run && touch /usr/local/logstash/run/logstash.pid
# touch /usr/local/logstash/logs/gc.log && chown -R elk:elk /usr/local/logstash
# systemctl daemon-reload
# systemctl enable logstash
# systemctl start logstash #先kill之前的logstash进程
可选部分(不推荐)
- 配置logstash服务:
服务文件
# vim /usr/bin/logstash
#!/bin/bash
#chkconfig: 2345 55 24
#description: logstash service manager
#logstash配置文件
CONFIG='/usr/local/logstash/config'
#logstash配置文件
FILE='-f /usr/local/logstash/conf.d/'
#指定logstash配置文件的命令
LOGBIN='/usr/local/logstash/bin/logstash'
#用锁文件配合服务启动与关闭
LOCK='/usr/local/logstash/locks'
#日志
#LOGLOG=' -l /home/elk/logstash/logs'
LOG_LOG=' >/dev/null 2>/usr/local/logstash/logs/logstash-plain.log &'
START() {
if [ -f $LOCK ];then
echo -e "Logstash is already \033[32mrunning\033[0m, do nothing."
else
echo -e "Start logstash service.\033[32mdone\033[m"
cd /usr/local/logstash/logs
eval " nohup ${LOGBIN} --path.settings ${CONFIG} ${FILE} ${LOG_LOG} "
touch $LOCK
fi
}
STOP() {
if [ ! -f $LOCK ];then
echo -e "Logstash is already stop, do nothing."
else
echo -e "Stop logstash serivce \033[32mdone\033[m"
rm -rf $LOCK
ps -ef | grep logstash | grep -v "grep" | awk '{print $2}' | xargs kill -s 9 >/dev/null
fi
}
STATUS() {
ps aux | grep logstash | grep -v "grep" >/dev/null
if [ -f $LOCK ] && [ $? -eq 0 ]; then
echo -e "Logstash is: \033[32mrunning\033[0m..."
else
echo -e "Logstash is: \033[31mstopped\033[0m..."
fi
}
TEST(){
${LOGBIN} --path.settings ${CONFIG} ${FILE} -t
}
case "$1" in
start)
START
;;
stop)
STOP
;;
status)
STATUS
;;
restart)
STOP
sleep 2
START
;;
test)
TEST
;;
*)
echo "Usage: logstash (test|start|stop|status|restart)"
;;
esac
- 管理服务:
# chmod +x /usr/bin/logstash
# logstash start #先kill之前的logstash进程
filebeat
192.168.30.130
- 安装filebeat:
# tar zxf filebeat-6.7.1-linux-x86_64.tar.gz && mv filebeat-6.7.1-linux-x86_64 /usr/local/filebeat
- 修改配置:
# vim /usr/local/filebeat/filebeat.yml
- type: log
# enabled: false
paths:
- /var/log/messages #以系统日志为例
output.elasticsearch:
hosts: ["192.168.30.130:9200"]
- 启动filebeat:
# nohup /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml &
# curl '192.168.30.130:9200/_cat/indices?v'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_1 e3tbCkGlQJyl6HsGRYDhOQ 1 1 22 1 223.6kb 111.6kb
green open nginx-test-2019.04.18 GXOnWVKNTpq43Hk2KZ8ATQ 5 1 569 0 2.6mb 1.3mb
green open filebeat-6.7.1-2019.04.18 UR05k-apTOuFs_0-jZKeyQ 3 1 388 0 55.8kb 55.1kb
green open .monitoring-es-6-2019.04.18 MmYWIrrhTeiQqz9muZV4Ww 1 1 5879 20 7.8mb 3.9mb
green open kibana_sample_data_logs h9wLl6EORv-ptFDgFv-zrg 1 1 14005 0 22.1mb 11mb
green open .kibana_task_manager 5uM_sV5YQpGL6ZgNNxWqlw 1 1 2 0 26.4kb 13.2kb
green open .monitoring-kibana-6-2019.04.18 V_WQQSgpTOu6BK7cQTfOQg 1 1 489 0 518.6kb 259.3kb
多出来以filebeat开头的索引。
查看elasticsearch-head页面
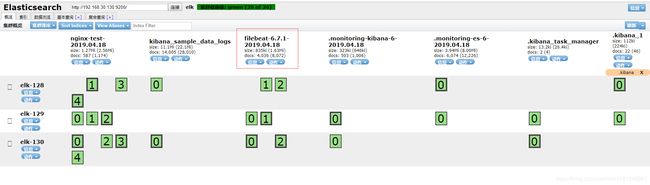
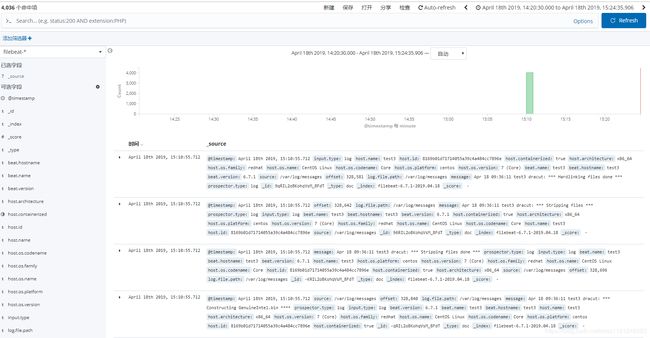
到kibana上创建索引并查看
- 配置filebeat服务:
服务文件
# vim /usr/lib/systemd/system/filebeat.service
[Unit]
Description=Filebeat sends log files to Logstash or directly to Elasticsearch.
Documentation=https://www.elastic.co/products/beats/filebeat
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml -path.home /usr/local/filebeat -path.config /usr/local/filebeat -path.data /usr/local/filebeat/data -path.logs /usr/local/filebeat/logs
Restart=always
[Install]
WantedBy=multi-user.target
- 管理服务:
# systemctl daemon-reload
# systemctl enable filebeat
# systemctl start filebeat #先kill之前的filebeat进程
以上只是简单地将ELK各组件安装,常用插件还并未安装。后续探索如何收集常用应用日志并做分析,以及收集错误日志并做Zabbix告警。