产品经理也能动手实践的AI(二)- 做个识别宠物的AI
上一篇《产品经理也能动手实践的AI(一)- FastAI介绍》,介绍了为什么选择FastAI,为什么适合产品经理,为什么值得学习这项技能。而写这篇文章的目标是,看完了之后可以更好的看懂教程中的内容。
概览
直接上例子,核心代码一共3行:
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(),size=224)learn = cnn_learner(data, models.resnet34, metrics=error_rate)learn.fit_one_cycle(4)
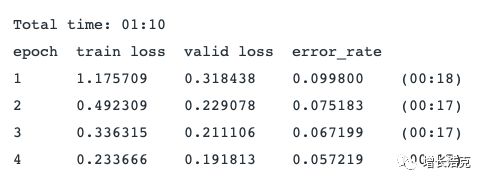
识别准确率是94.3%,在2012年,宠物识别的准确率才59%
核心步骤
创建图像数据 databunch object
创建学习对象 learn object
开始训练 fit one cycle
调试
保存之前的模型
数据纠错
找到学习率
重新训练
前3个就是训练一个神经网络必要的代码,而之后的那些都是从各个角度去发现问题,然后提高准确率。
这里还有几个重要概念:
迁移学习 transfer learning:类似于大师已经提供了一套学习方法,我们在这基础上训练自己的学习方法;
错误率 error rate:就是验证组数据,预测错误的百分比;
损失 loss:我形象的称为打脸指数,就是越自信,但是却预测错误,那loss就高
验证组 validation set:数据一般分为训练组和验证组,验证组就是用来验证训练好的模型的准确度,验证组的数据是AI没有见过的数据;
过度拟合 overfit:有点类似于牛肉吃多了,吃什么都觉得像牛肉味……我举不出更好的例子了,有想法记得给我留言;
学习率 learning rate:就类似于1个字1个字读→一个个词读→一句句话读,1个个字读就属于小的学习率,比较容易发现更细节的特征点,而大的学习率会发现更宏观的特征点;
详细讲解
这节课的重点是跑通一个模型,并且调试到比较好的效果,最终将准确率提高到了95.8%。
Jeremy专门做了很多函数,可以一键导入数据,而不是在第一节课就制造N多阻碍,所以只要在Jupyter notebook里一步步运行就一定可以跑通,但是每一步或者每一个参数代表什么,是需要在实践的过程中搞清楚的,前3个核心步骤基本看教程都很容易搞懂,不懂的查找文档也很好理解。
这里重点说下调试部分,首先需要保存一下现有训练的结果:
learn.save('stage-1')然后可以通过2种方式去调节模型,一是创建 解释器interpretation,找到异常图片,然后删掉它(下节课才讲如何删);二是找到合适的 学习率learning rate进行 微调fine-tuning。
先看解释器,提到了2个函数:plot_top_loss 和 most_confused,第一个是把错的最离谱的图片都打出来,第二个是把猜错次数最多的类别给打出来。这样就非常容易发现问题,比如把出错次数最多的打出来之后,发现这2种狗确实很接近,人的话也不是特别容易区分,这就可能需要单独的大量的图片训练。
然后是fine-tuning,这里是重点!!多强调一下,要想微调,就要搞清楚图像识别的原理,或者叫CNN(convolutional neural network)卷积神经网络的原理,作者拿出了Clarify的CEO发表的一片通过视觉化理解卷积网络的论文,详细介绍了其中的原理。

首先第一层的训练,属于学习率特别低的训练,机器找到了边缘的规律,发现这几种颜色的渐变是特别常见的。

然后第二层,基于第一层找到的边缘,发现这些边缘的连接,比如直角或者一个弧形是比较有共性的东西。
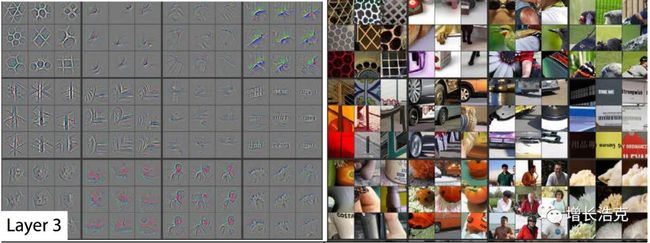
然后第三层,基于第二层发现的线条,发现了各种形状。

然后第四层第五层,感觉已经可以识别特定的形状和特定的物体了,随着层级的提高,能识别的共性图像的复杂性也在提高,是因为学习率的提高,机器会选择性的忽略细节,反而更多的关注宏观的相似。
第一次训练用的架构叫做ResNet34,是一个基于上百万张图片训练了34层之后得到的一个通用的图片识别模型。之前的训练就是在这个模型之后增加个4个层,训练之后的结果就已经非常不错了,如果想变得更好,就只能将之前的模型解冻unfreeze,然后连贯起来重新训练,并通过
learn.lr_find()learn.recorder.plot()
找到loss和lr的关系
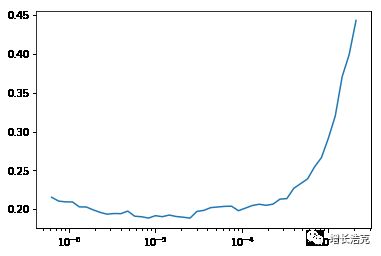
这张图可以看到当learning rate超过 10-4之后,loss明显升高,就说明之前默认的0.003的lr偏高了,所以调整lr
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4))至于为什么调到这个区间,之后的课程会将,而现在就是一个可以充分实践的机会。
最后得出的准确率94.7%,比之前的94.3%只高了一点点,而95.8%的准确率是通过ResNet50来实现的,因为这个pre-train的模型跑了50层,识别率更高,但非常占用计算机性能。
好了,草草的把介绍写完了,很多东西没法一篇文章写完,一方面得自己多动手尝试去感受,另一方面确实有些概念得逐渐理解,希望这篇文章让你对FastAI运作的模式有了一个清晰的认识。