生成对抗网络 GAN 的数学原理
摘要
本文从概率分布及参数估计说起, 通过介绍极大似然估计, KL 散度, JS 散度, 详细的介绍了 GAN 生成对抗网络的数学原理.
相关
系列文章索引 :
https://blog.csdn.net/oBrightLamp/article/details/85067981
正文
无论是黑白图片或彩色图片, 都是使用 0 ~ 255 的数值表示像素. 将所有的像素值除以 255 我们就可以将一张图片转化为 0 ~ 1 的概率分布, 而且这种转化是可逆的, 乘以 255 就可以还原.
从某种意义上来讲, GAN 图片生成任务就是生成概率分布. 因此, 我们有必要结合概率分布来理解 GAN 生成对抗网络的原理.
1. 概率分布及参数估计
假设一个抽奖盒子里有45个球, 其编号是 1~9 共9个数字. 每个编号的球拥有的数量是:
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 数量 | 2 | 4 | 6 | 8 | 9 | 7 | 5 | 3 | 1 |
| 占比 | 0.044 | 0.088 | 0.133 | 0.178 | 0.200 | 0.156 | 0.111 | 0.066 | 0.022 |
占比是指用每个编号的数量除以所有编号的总数量, 在数理统计学中, 在不引起误会的情况下, 这里的占比也可以被称为 概率/频率.
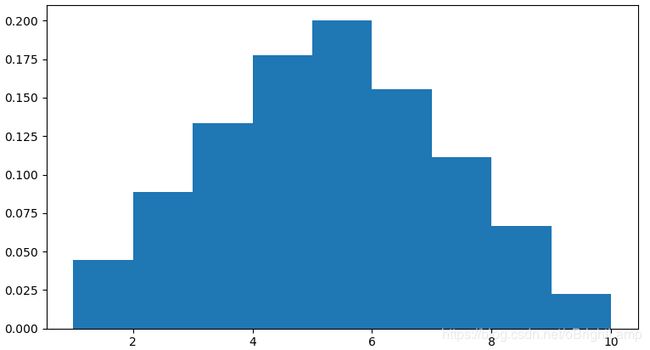
使用向量 q q q 表示上述的概率分布 :
q = ( 2 , 4 , 6 , 8 , 9 , 7 , 5 , 3 , 1 ) / 45 = ( 0.044 , 0.088 , 0.133 , 0.178 , 0.200 , 0.156 , 0.111 , 0.066 , 0.022 ) q = (2,4,6,8,9,7,5,3,1)/45 \;\\ =(0.044, 0.088, 0.133, 0.178, 0.200, 0.156, 0.111, 0.066, 0.022) q=(2,4,6,8,9,7,5,3,1)/45=(0.044,0.088,0.133,0.178,0.200,0.156,0.111,0.066,0.022)
将上述分布使用图像绘制如下 :
现在我们希望构建一个函数 p = p ( x ; θ ) p = p(x;\theta) p=p(x;θ), 以 x x x 为编号作为输入数据, 输出编号 x x x 的概率. θ \theta θ 是参与构建这个函数的参数, 一经选定就不再变化.
假设上述概率分布服从二次抛物线函数 :
p = p ( x ; θ ) = θ 1 ( x + θ 2 ) 2 + θ 3 x = ( 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ) p=p(x;\theta)=\theta_1 (x+\theta_2)^2+\theta_3\\ \;\\ x = (1,2,3,4,5,6,7,8,9) p=p(x;θ)=θ1(x+θ2)2+θ3x=(1,2,3,4,5,6,7,8,9)
使用 L2 误差作为评价拟合效果的损失函数, 总误差值为 error (标量 e) :
e = ∑ i = 1 9 ( p i − q i ) 2 e = \sum_{i=1}^{9}(p_i-q_i)^2 e=i=1∑9(pi−qi)2
我们希望求得一个 θ ∗ \theta^* θ∗, 使得 e e e 的值越小越好, 使用数学公式表达是这样子的 :
θ ∗ = a r g m i n θ ( e ) \theta^* = \underset{\theta}{argmin}(e) θ∗=θargmin(e)
argmin 是 argument minimum 的缩写.
如何求 θ ∗ \theta^* θ∗ 不是本文的重点, 这是生成对抗网络的任务. 为了帮助理解, 取其中一个可能的数值作为示例 :
θ ∗ = ( θ 1 , θ 2 , θ 3 ) = ( − 0.01 , − 5.0 , 0.2 ) p = p ( x ; θ ) = − 0.01 ( x − 5.0 ) 2 + 0.2 \theta^* = (\theta_1,\theta_2,\theta_3)=(-0.01,-5.0,0.2)\\ \;\\ p=p(x;\theta)=-0.01 (x-5.0)^2+0.2 θ∗=(θ1,θ2,θ3)=(−0.01,−5.0,0.2)p=p(x;θ)=−0.01(x−5.0)2+0.2
绘制函数图像如下 :
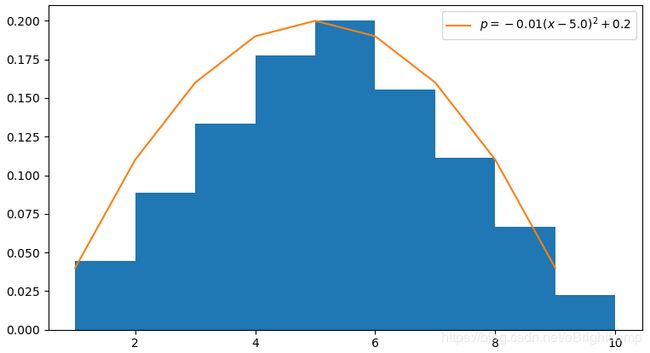
在生成对抗网络中, 本例的估计函数 p ( x ; θ ) p(x;\theta) p(x;θ) 相当于生成模型 (generator), 损失函数相当于鉴别模型 (discriminator).
2. 极大似然估计
在上例中, 我们很幸运的知道了所有可能的概率分布, 并让求解最优的概率分布估计函数 p ( x ; θ ) p(x;\theta) p(x;θ) 成为可能.
如果上例的抽奖盒子 (简称样本) 中的 45 个球是从更大的抽奖池 (简称总体) 中选择出来的, 而我们不知道抽奖池中所有球的数量及其编号. 那么, 我们如何根据现有的 45 个球来估计抽奖池的概率分布呢? 我们当然可以直接用上例求得的样本估计函数来代表抽奖池的概率分布, 但本例会介绍一种更常用的估计方法.
假设 p ( x ) = p ( x ; θ ) p(x)=p(x;\theta) p(x)=p(x;θ) 是总体的概率分布函数. 则编号 x = ( x 1 , x 2 , x 3 , ⋯ , x n ) x = (x_1,x_2,x_3,\cdots,x_n) x=(x1,x2,x3,⋯,xn) 出现的概率为 :
p = p ( x 1 ) , p ( x 2 ) , p ( x 3 ) , ⋯ , p ( x n ) p = p(x_1),p(x_2),p(x_3),\cdots,p(x_n) p=p(x1),p(x2),p(x3),⋯,p(xn)
在本例中, n = 9 n = 9 n=9, 即共 9 个编号.
设 d = ( d 1 , d 2 , d 3 , d 3 ⋯ , d m ) d=(d_1,d_2,d_3,d_3\cdots,d_m) d=(d1,d2,d3,d3⋯,dm) 是所有的抽样的编号. 在本例中, m = 45 m = 45 m=45, 即样本中共有 45 个抽样. 假设所有的样本和抽样都是独立的, 则样本出现的概率为 :
ρ = p ( d 1 ) × p ( d 2 ) × p ( d 3 ) × ⋯ × p ( d m ) = ∏ i = 1 m p ( d i ) \rho= p(d_1)\times p(d_2)\times p(d_3)\times\cdots\times p(d_m)=\prod_{i=1}^{m}p(d_i) ρ=p(d1)×p(d2)×p(d3)×⋯×p(dm)=i=1∏mp(di)
p ( x ) = p ( x ; θ ) p(x)=p(x;\theta) p(x)=p(x;θ) 的函数结构是人为按经验选取的, 比如线性函数, 多元二次函数, 更复杂的非线性函数等, 一经选取则不再改变. 现在我们需要求解一个参数集 θ ∗ \theta^* θ∗, 使得 ρ \rho ρ 的值越大越好. 即
θ ∗ = a r g m a x θ ( ρ ) = a r g m a x θ ∏ i = 1 m p ( d i ; θ ) \theta^* = \underset{\theta}{argmax}(\rho)=\underset{\theta}{argmax}\prod_{i=1}^{m}p(d_i;\theta) θ∗=θargmax(ρ)=θargmaxi=1∏mp(di;θ)
argmax 是 argument maximum 的缩写.
通俗来讲, 因为样本是实际已发生的事实, 在函数结构已确定的情况下, 我们需要尽量优化参数, 使得样本的理论估计概率越大越好.
这里有一个前提, 就是人为选定的函数结构应当能够有效评估样本分布. 反之, 如果使用线性函数去拟合正态概率分布 (normal distribution), 则无论如何选择参数都无法得到满意的效果.
连乘运算不方便, 将之改为求和运算. 由于 l o g log log 对数函数的单调性, 上面的式子等价于 :
θ ∗ = a r g m a x θ l o g ∏ i = 1 m p ( d i ; θ ) = a r g m a x θ ∑ i = 1 m l o g p ( d i ; θ ) \theta^* =\underset{\theta}{argmax}\;log\prod_{i=1}^{m}p(d_i;\theta)=\underset{\theta}{argmax}\sum_{i=1}^{m}log\;p(d_i;\theta) θ∗=θargmaxlogi=1∏mp(di;θ)=θargmaxi=1∑mlogp(di;θ)
设样本分布为 q ( x ) q(x) q(x), 对于给定样本, 这个分布是已知的, 可以通过统计抽样的计算得出. 将上式转化成期望公式 :
θ ∗ = a r g m a x θ ∑ i = 1 m l o g p ( d i ; θ ) = a r g m a x θ ∑ i = 1 n q ( x i ) l o g p ( x i ; θ ) \theta^* =\underset{\theta}{argmax}\sum_{i=1}^{m}log\;p(d_i;\theta) =\underset{\theta}{argmax}\sum_{i=1}^{n}q(x_i)\;log\;p(x_i;\theta) θ∗=θargmaxi=1∑mlogp(di;θ)=θargmaxi=1∑nq(xi)logp(xi;θ)
注意上式中的两个求和符号, m m m 变成了 n n n. 在大多数情况下, 编号数量会比抽样数量少, 转为期望公式可以显著减少计算量.
在一些教材中, 上式的写法是:
θ ∗ = a r g m a x θ E x − q ( x ) l o g p ( x ; θ ) = a r g m a x θ ∫ q ( x ) l o g p ( x ; θ ) d x \theta^*=\underset{\theta}{argmax}\; E_{x-q(x)}log\;p(x;\theta) =\underset{\theta}{argmax}\int q(x)\;log\;p(x;\theta)dx θ∗=θargmaxEx−q(x)logp(x;θ)=θargmax∫q(x)logp(x;θ)dx
E x − q ( x ) E_{x-q(x)} Ex−q(x) 表示按 q ( x ) q(x) q(x) 的分布对 x x x 求期望. 因为积分表达式比较简洁, 书写方便, 下文开始将主要使用积分表达式.
以上就是极大似然估计(Maximum Likelihood Estimation) 的理论和推导过程. 和上例的参数估计方法相比, 极大似然估计的方法, 因为无需设计损失函数, 降低了模型的复杂度, 扩大了适用范围.
本例中的估计函数 p ( x ; θ ) p(x;\theta) p(x;θ) 相当于生成对抗网络的生成模型, 样本分布 q ( x ) q(x) q(x) 相当于训练数据.
3. KL散度
结合上例, 在样本已知的情况下, q ( x ) q(x) q(x) 是一个已知且确定的分布. 则 ∫ q ( x ) l o g q ( x ) d x \int q(x)\;log\;q(x)dx ∫q(x)logq(x)dx 是一个常数项, 不影响 θ ∗ \theta^* θ∗ 求解的结果.
θ ∗ = a r g m a x θ ( ∫ q ( x ) l o g p ( x ; θ ) d x − ∫ q ( x ) l o g q ( x ) d x ) = a r g m a x θ ∫ q ( x ) ( l o g p ( x ; θ ) − l o g q ( x ) ) d x = a r g m a x θ ∫ q ( x ) l o g p ( x ; θ ) q ( x ) d x \theta^*=\underset{\theta}{argmax}(\int q(x)\;log\;p(x;\theta)dx-\int q(x)\;log\;q(x)dx)\\ \;\\ =\underset{\theta}{argmax}\int q(x)\;(log\;p(x;\theta)-log\;q(x))dx\\ \;\\ =\underset{\theta}{argmax}\int q(x)\;log\;\frac{p(x;\theta)}{q(x)}dx\\ θ∗=θargmax(∫q(x)logp(x;θ)dx−∫q(x)logq(x)dx)=θargmax∫q(x)(logp(x;θ)−logq(x))dx=θargmax∫q(x)logq(x)p(x;θ)dx
也可以写成这样 :
θ ∗ = a r g m i n θ ( − ∫ q ( x ) l o g p ( x ; θ ) d x + ∫ q ( x ) l o g q ( x ) d x ) = a r g m i n θ ∫ q ( x ) l o g q ( x ) p ( x ; θ ) d x \theta^*=\underset{\theta}{argmin}(-\int q(x)\;log\;p(x;\theta)dx+\int q(x)\;log\;q(x)dx)\\ \;\\ =\underset{\theta}{argmin}\int q(x)\;log\;\frac{q(x)}{p(x;\theta)}dx\\ θ∗=θargmin(−∫q(x)logp(x;θ)dx+∫q(x)logq(x)dx)=θargmin∫q(x)logp(x;θ)q(x)dx
KL 散度 ( Kullback–Leibler divergence ) 是一种衡量两个概率分布的匹配程度的指标, 两个分布差异越大, KL散度越大. 它还有很多名字, 比如: relative entropy, relative information.
其定义如下 :
D K L ( q ∣ ∣ p ) = ∫ q ( x ) l o g q ( x ) p ( x ) d x D_{KL}(q||p)=\int q(x)\;log\;\frac{q(x)}{p(x)}dx DKL(q∣∣p)=∫q(x)logp(x)q(x)dx
当 p ( x ) ≡ q ( x ) p(x)\equiv q(x) p(x)≡q(x) 时取得最小值 D K L ( q ∣ ∣ p ) = 0 D_{KL}(q||p) = 0 DKL(q∣∣p)=0.
我们可以将上面的公式简化为 :
θ ∗ = a r g m i n θ D K L ( q ∣ ∣ p ( x ; θ ) ) \theta^*=\underset{\theta}{argmin}\;D_{KL}(q||p(x;\theta)) θ∗=θargminDKL(q∣∣p(x;θ))
4. JS 散度
KL 散度是非对称的,即 D K L ( q ∣ ∣ p ) D_{KL}(q||p) DKL(q∣∣p) 不一定等于 D K L ( p ∣ ∣ q ) D_{KL}(p||q) DKL(p∣∣q). 为了解决这个问题, 需要引入 JS 散度.
JS 散度 ( Jensen–Shannon divergence ) 的定义如下 :
m = 1 2 ( p + q ) D J S = 1 2 D K L ( p ∣ ∣ m ) + 1 2 D K L ( q ∣ ∣ m ) m =\frac{1}{2}(p + q) \\ \;\\ D_{JS}=\frac{1}{2}D_{KL}(p||m) + \frac{1}{2}D_{KL}(q||m) m=21(p+q)DJS=21DKL(p∣∣m)+21DKL(q∣∣m)
JS 的值域是对称的, 有界的, 范围是 [0,1].
如果 p, q 完全相同, 则 JS = 0, 如果完全不相同, 则 JS = 1.
注意, KL 散度和 JS 散度作为差异度量的时候, 有一个问题:
如果两个分配 p, q 离得很远, 完全没有重叠的时候, 那么 KL 散度值是没有意义的, 而 JS 散度值是一个常数. 这在学习算法中是比较致命的, 这就意味这这一点的梯度为0, 梯度消失了.
参考上例, 对 JS 散度进行反推:
D J S ( q ∣ ∣ p ) = 1 2 D K L ( q ∣ ∣ m ) + 1 2 D K L ( p ∣ ∣ m ) = 1 2 ∫ q ( x ) l o g q ( x ) q ( x ) + p ( x ; θ ) 2 d x + 1 2 ∫ p ( x ; θ ) l o g p ( x ; θ ) p ( x ; θ ) + q ( x ) 2 d x = 1 2 ∫ q ( x ) l o g 2 q ( x ) q ( x ) + p ( x ; θ ) d x + 1 2 ∫ p ( x ; θ ) l o g 2 p ( x ; θ ) p ( x ; θ ) + q ( x ) d x D_{JS}(q||p)=\frac{1}{2}D_{KL}(q||m)+\frac{1}{2}D_{KL}(p||m)\\ \;\\ =\frac{1}{2}\int q(x)\;log\;\frac{q(x)}{\frac{q(x)+p(x;\theta)}{2}}dx+ \frac{1}{2}\int p(x;\theta)\;log\;\frac{p(x;\theta)}{\frac{p(x;\theta)+q(x)}{2}}dx\\ \;\\ =\frac{1}{2}\int q(x)\;log\;\frac{2q(x)}{q(x)+p(x;\theta)}dx+ \frac{1}{2}\int p(x;\theta)\;log\;\frac{2p(x;\theta)}{p(x;\theta)+q(x)}dx DJS(q∣∣p)=21DKL(q∣∣m)+21DKL(p∣∣m)=21∫q(x)log2q(x)+p(x;θ)q(x)dx+21∫p(x;θ)log2p(x;θ)+q(x)p(x;θ)dx=21∫q(x)logq(x)+p(x;θ)2q(x)dx+21∫p(x;θ)logp(x;θ)+q(x)2p(x;θ)dx
由于 :
∫ q ( x ) l o g 2 q ( x ) q ( x ) + p ( x ; θ ) d x = ∫ q ( x ) ( l o g q ( x ) q ( x ) + p ( x ; θ ) + l o g 2 ) d x = ∫ q ( x ) l o g q ( x ) q ( x ) + p ( x ; θ ) d x + ∫ q ( x ) ( l o g 2 ) d x = ∫ q ( x ) l o g q ( x ) q ( x ) + p ( x ; θ ) d x + l o g 2 \int q(x)\;log\;\frac{2q(x)}{q(x)+p(x;\theta)}dx\\ \;\\ =\int q(x)\;(log\;\frac{q(x)}{q(x)+p(x;\theta)}+log2)dx\\ \;\\ =\int q(x)\;log\;\frac{q(x)}{q(x)+p(x;\theta)}dx+\int q(x)(log2)dx\\ \;\\ =\int q(x)\;log\;\frac{q(x)}{q(x)+p(x;\theta)}dx+log2 ∫q(x)logq(x)+p(x;θ)2q(x)dx=∫q(x)(logq(x)+p(x;θ)q(x)+log2)dx=∫q(x)logq(x)+p(x;θ)q(x)dx+∫q(x)(log2)dx=∫q(x)logq(x)+p(x;θ)q(x)dx+log2
同理可得 :
D J S ( q ∣ ∣ p ) = 1 2 ∫ q ( x ) l o g q ( x ) q ( x ) + p ( x ; θ ) d x + 1 2 ∫ p ( x ; θ ) l o g p ( x ; θ ) p ( x ; θ ) + q ( x ) d x + l o g 2 D_{JS}(q||p)=\frac{1}{2}\int q(x)\;log\;\frac{q(x)}{q(x)+p(x;\theta)}dx+ \frac{1}{2}\int p(x;\theta)\;log\;\frac{p(x;\theta)}{p(x;\theta)+q(x)}dx+log2 DJS(q∣∣p)=21∫q(x)logq(x)+p(x;θ)q(x)dx+21∫p(x;θ)logp(x;θ)+q(x)p(x;θ)dx+log2
令 :
d ( x ; θ ) = q ( x ) q ( x ) + p ( x ; θ ) d(x;\theta)=\frac{q(x)}{q(x)+p(x;\theta)} d(x;θ)=q(x)+p(x;θ)q(x)
则 :
1 − d ( x ; θ ) = p ( x ; θ ) q ( x ) + p ( x ; θ ) 1-d(x;\theta)=\frac{p(x;\theta)}{q(x)+p(x;\theta)} 1−d(x;θ)=q(x)+p(x;θ)p(x;θ)
即 :
D J S ( q ∣ ∣ p ) = 1 2 ∫ q ( x ) l o g d ( x ; θ ) d x + 1 2 ∫ p ( x ; θ ) l o g ( 1 − d ( x ; θ ) ) d x + l o g 2 D_{JS}(q||p)=\frac{1}{2}\int q(x)\;log\;d(x;\theta)dx+ \frac{1}{2}\int p(x;\theta)\;log\;(1-d(x;\theta))dx+log2 DJS(q∣∣p)=21∫q(x)logd(x;θ)dx+21∫p(x;θ)log(1−d(x;θ))dx+log2
令 :
V ( x ; θ ) = ∫ q ( x ) l o g d ( x ; θ ) d x + ∫ p ( x ; θ ) l o g ( 1 − d ( x ; θ ) ) d x V(x;\theta) =\int q(x)\;log\;d(x;\theta)dx+ \int p(x;\theta)\;log\;(1-d(x;\theta))dx V(x;θ)=∫q(x)logd(x;θ)dx+∫p(x;θ)log(1−d(x;θ))dx
则 :
D J S ( q ∣ ∣ p ) = 1 2 V ( x ; θ ) + l o g 2 D_{JS}(q||p)=\frac{1}{2}V(x;\theta)+log2 DJS(q∣∣p)=21V(x;θ)+log2
即 :
θ ∗ = a r g m i n θ D J S ( q ∣ ∣ p ) = a r g m i n θ V ( x ; θ ) \theta^*=\underset{\theta}{argmin}\;D_{JS}(q||p)=\underset{\theta}{argmin}\;V(x;\theta) θ∗=θargminDJS(q∣∣p)=θargminV(x;θ)
此时, θ ∗ \theta^* θ∗ 是令 p ( x ; θ ) p(x;\theta) p(x;θ) 和 q ( x ) q(x) q(x) 差异最小的参数. 同样亦可通过 V ( x ; θ ) V(x;\theta) V(x;θ) 求差异最大的参数.
5. JS 散度参数求解的两步走迭代方法
从上例的讨论我们知道, 我们需要求得一个参数 θ ∗ \theta^* θ∗, 使得
θ ∗ = a r g m i n θ D J S ( q ∣ ∣ p ) = a r g m i n θ V ( x ; θ ) \theta^*=\underset{\theta}{argmin}D_{JS}(q||p)=\underset{\theta}{argmin} V(x;\theta) θ∗=θargminDJS(q∣∣p)=θargminV(x;θ)
然而, 因为涉及多重嵌套和积分, 使用起来并不方便.
首先, 我们假设 p ( x ; θ ) = p g ( x ) p(x;\theta) = p_g(x) p(x;θ)=pg(x) 为已知条件, 同时令 D = d ( x ; θ ) D=d(x;\theta) D=d(x;θ), 考虑这个式子:
W ( x ; θ ) = q ( x ) l o g d ( x ; θ ) d x + p ( x ; θ ) l o g ( 1 − d ( x ; θ ) ) W ( x ; D ) = q ( x ) l o g D + p g ( x ) l o g ( 1 − D ) V ( x ; θ ) = V ( x ; D ) = ∫ W ( x ; D ) d x W(x;\theta)=q(x)\;log\;d(x;\theta)dx+ p(x;\theta)\;log\;(1-d(x;\theta))\\ \;\\ W(x;D)=q(x)\;log\;D+p_g(x)\;log\;(1-D)\\ \;\\ V(x;\theta)=V(x;D)=\int W(x;D)dx W(x;θ)=q(x)logd(x;θ)dx+p(x;θ)log(1−d(x;θ))W(x;D)=q(x)logD+pg(x)log(1−D)V(x;θ)=V(x;D)=∫W(x;D)dx
在 x x x 已经确定的情况下, 我们关注 D D D.
W ′ = d W d D = q ( x ) 1 D − p g ( x ) 1 1 − D W ′ ′ = d W ′ d D = − q ( x ) 1 D 2 − p g ( x ) 1 ( 1 − D ) 2 W'=\frac{dW}{dD}=q(x)\frac{1}{D}-p_g(x)\frac{1}{1-D}\\ \;\\ W''=\frac{dW'}{dD}=-q(x)\frac{1}{D^2}-p_g(x)\frac{1}{(1-D)^2} W′=dDdW=q(x)D1−pg(x)1−D1W′′=dDdW′=−q(x)D21−pg(x)(1−D)21
因为 W ′ ′ < 0 W'' < 0 W′′<0, 当 W ′ = 0 W'=0 W′=0 时, W W W 取得极大值 :
W ′ = q ( x ) 1 D − p g ( x ) 1 1 − D = 0 D = q ( x ) q ( x ) + p g ( x ) W'=q(x)\frac{1}{D}-p_g(x)\frac{1}{1-D}=0\\ \;\\ D = \frac{q(x)}{q(x)+p_g(x)} W′=q(x)D1−pg(x)1−D1=0D=q(x)+pg(x)q(x)
因为 :
D < q ( x ) q ( x ) + p g ( x ) , W ′ > 0 D > q ( x ) q ( x ) + p g ( x ) , W ′ < 0 D < \frac{q(x)}{q(x)+p_g(x)},\;\;W'>0\\ \;\\ D > \frac{q(x)}{q(x)+p_g(x)},\;\;W'<0 D<q(x)+pg(x)q(x),W′>0D>q(x)+pg(x)q(x),W′<0
这表明, 当 D D D 的函数按 W ′ = 0 W'=0 W′=0 取值时, W W W 在 x x x 的每个取样点均获得最大值, 积分后的面积获得最大值, 即 :
D ∗ = q ( x ) q ( x ) + p g ( x ) = a r g m a x D ∫ W ( x ; D ) d x = a r g m a x D V ( x ; D ) D^*=\frac{q(x)}{q(x)+p_g(x)}=\underset{D}{argmax}\int W(x;D)dx=\underset{D}{argmax}V(x;D) D∗=q(x)+pg(x)q(x)=Dargmax∫W(x;D)dx=DargmaxV(x;D)
m a x D V ( x ; D ) = ∫ q ( x ) l o g D ∗ ( x ) d x + ∫ p g ( x ) l o g ( 1 − D ∗ ( x ) ) d x \underset{D}{max}\;V(x;D)=\int q(x)\;log\;D^*(x)dx+\int p_g(x)\;log\;(1-D^*(x))dx DmaxV(x;D)=∫q(x)logD∗(x)dx+∫pg(x)log(1−D∗(x))dx
在得到 V ( x ; D ) V(x;D) V(x;D) 的最大值表达式后, 我们固定 D ∗ D^* D∗, 接着对 p ( x ; θ ) = p g ( x ) p(x;\theta) = p_g(x) p(x;θ)=pg(x) 将这个最大值的按最小方向优化 :
V ( x ; θ ; D ∗ ) = ∫ q ( x ) l o g D ∗ ( x ) d x + ∫ p ( x ; θ ) l o g ( 1 − D ∗ ( x ) ) d x θ ∗ = a r g m i n θ V ( x ; θ ∗ ; D ∗ ) V(x;\theta;D^*)=\int q(x)\;log\;D^*(x)\;dx+\int p(x;\theta)\;log\;(1-D^*(x))dx\\ \;\\ \theta^*=\underset{\theta}{argmin}\;V(x;\theta^*;D^*) V(x;θ;D∗)=∫q(x)logD∗(x)dx+∫p(x;θ)log(1−D∗(x))dxθ∗=θargminV(x;θ∗;D∗)
由此, 通过两步走的方法, 经过多次先后迭代求解 D ∗ D^* D∗ 和 θ ∗ \theta^* θ∗, 我们可以逐渐得到一个趋近于 q ( x ) q(x) q(x) 的 p ( x ; θ ∗ ) p(x;\theta^*) p(x;θ∗).
6. 生成对抗网络
从上面的讨论方法可知, 我们可以得到一个和 q ( x ) q(x) q(x) 非常接近的分布函数 p ( x ; θ ) p(x;\theta) p(x;θ). 这个分布函数的构建是为了寻找已知样本数据的内在规律.
然而我们往往并不关心这个分布函数. 我们希望无中生有的构建一批数据 x ′ x' x′, 使得 p ( x ′ ; θ ) p(x';\theta) p(x′;θ) 趋近于 q ( x ) q(x) q(x).
我们设计一个输出 x ′ x' x′ 的生成器 x ′ = G ( z ; β ) x'=G(z;\beta) x′=G(z;β), 从随机概率分布中接收 z z z 作为输入, x ′ x' x′ 的概率分布为 p g ( x ′ ) p_g(x') pg(x′).
第一步, 我们固定 p g ( x ′ ) p_g(x') pg(x′) 求 D ∗ D^* D∗.
V ( x , x ′ ; D ) = ∫ q ( x ) l o g D ( x ) d x + ∫ p g ( x ′ ) l o g ( 1 − D ( x ′ ) ) d x D ∗ = a r g m a x D V ( x ; D ) V(x,x';D)=\int q(x)\;log\;D(x)\;dx+\int p_g(x')\;log\;(1-D(x'))dx\\ \;\\ D^*=\underset{D}{argmax}V(x;D) V(x,x′;D)=∫q(x)logD(x)dx+∫pg(x′)log(1−D(x′))dxD∗=DargmaxV(x;D)
第二步, 我们固定 D ∗ D^* D∗ 求 p g ( x ′ ; θ ∗ ) p_g(x';\theta^*) pg(x′;θ∗).
V ( x , x ′ , D ∗ ; θ ) = ∫ q ( x ) l o g D ∗ ( x ) d x + ∫ p g ( x ′ ; θ ) l o g ( 1 − D ∗ ( x ′ ) ) d x θ ∗ = a r g m i n θ V ( x , D ∗ ; θ ∗ ) V(x,x',D^*;\theta)=\int q(x)\;log\;D^*(x)\;dx+\int p_g(x';\theta)\;log\;(1-D^*(x'))dx\\ \;\\ \theta^*=\underset{\theta}{argmin}\;V(x,D^*;\theta^*) V(x,x′,D∗;θ)=∫q(x)logD∗(x)dx+∫pg(x′;θ)log(1−D∗(x′))dxθ∗=θargminV(x,D∗;θ∗)
然后进行多次循环迭代, 使得 p g ( x ′ ; θ ∗ ) p_g(x';\theta^*) pg(x′;θ∗) 趋近于 q ( x ) q(x) q(x).
读者可以发现, 这里求解过程和上例的是一样, 只是输入的数据并不一致.
在实际任务中, 我们并不关心 p g ( x ′ ; θ ) p_g(x';\theta) pg(x′;θ), 仅关注生成器 x ′ = G ( z ; β ) x'=G(z;\beta) x′=G(z;β) 的优化.
由此我们将算法改编如下 :
第一步, 我们固定 x ′ = G ( z ; β ) x'=G(z;\beta) x′=G(z;β) 求 D ∗ D^* D∗.
V ( x , z ; D ) = ∫ q ( x ) l o g D ( x ) d x + ∫ q ( z ) l o g ( 1 − D ( G ( z ) ) ) d z D ∗ = a r g m a x D V ( x , z ; D ) V(x,z;D)=\int q(x)\;log\;D(x)\;dx+\int q(z)\;log\;(1-D(G(z)))dz\\ \;\\ D^*=\underset{D}{argmax}V(x,z;D) V(x,z;D)=∫q(x)logD(x)dx+∫q(z)log(1−D(G(z)))dzD∗=DargmaxV(x,z;D)
第二步, 我们固定 D ∗ D^* D∗ 求 G ( z ; β ∗ ) G(z;\beta^*) G(z;β∗).
V ( x , z , D ∗ ; β ) = ∫ q ( x ) l o g D ∗ ( x ) d x + ∫ q ( z ) l o g ( 1 − D ∗ ( G ( z ; β ) ) ) d z β ∗ = a r g m i n β V ( x , z , D ∗ ; β ) V(x,z,D^*;\beta)=\int q(x)\;log\;D^*(x)\;dx+\int q(z)\;log\;(1-D^*(G(z;\beta)))dz\\ \;\\ \beta^*=\underset{\beta}{argmin}\;V(x,z,D^*;\beta) V(x,z,D∗;β)=∫q(x)logD∗(x)dx+∫q(z)log(1−D∗(G(z;β)))dzβ∗=βargminV(x,z,D∗;β)
注意, 本例的两个算法都没有给出严格的收敛证明.
由于求解形式和上例的 JS 散度的参数求解算法非常一致, 我们可以期待这种算法能够起到作用.
为简单起见, 我们记 :
V ( G , D ) = ∫ q ( x ) l o g D ( x ) d x + ∫ q ( z ) l o g ( 1 − D ( G ( z ) ) ) d z G ∗ = a r g m i n G ( m a x D V ( G , D ) ) V(G,D)=\int q(x)\;log\;D(x)\;dx+\int q(z)\;log\;(1-D(G(z)))dz\\ \;\\ G^*=\underset{G}{argmin}\;(\;\underset{D}{max}\;V(G,D)\;) V(G,D)=∫q(x)logD(x)dx+∫q(z)log(1−D(G(z)))dzG∗=Gargmin(DmaxV(G,D))
这就是 GAN 生成对抗网络相关文献中常见的求解表达式.
在 Ian J. Goodfellow 的论文 Generative Adversarial Networks 中, 作者先给出了 V ( G , D ) V(G,D) V(G,D) 的表达式, 然后再通过 JS 散度的理论来证明其收敛性. 有兴趣的读者可以参考阅读.
本文认为, 如果先介绍 JS 散度, 再进行反推, 可以更容易的理解 GAN 概念, 理解 GAN 为什么要用这么复杂的损失函数.
7. 生成对抗网络的工程实践
在工程实践中, 我们遇到的一般是离散的数据. 我们可以使用随机采样的方法来逼近期望值.
首先我们从前置的随机分布 p z ( z ) p_z(z) pz(z) 中取出 m m m 个随机数 z = ( z 1 , z 2 , z 3 , ⋯ , z m ) z=(z_1,z_2,z_3,\cdots,z_m) z=(z1,z2,z3,⋯,zm), 其次我们在从真实数据分布 p ( x ) p(x) p(x) 中取出 m m m 个真实样本 p = ( x 1 , x 2 , x 3 , ⋯ , x m ) p=(x_1,x_2,x_3,\cdots,x_m) p=(x1,x2,x3,⋯,xm).
由于我们的数据是随机选取的, 概率越大就越有机会被选中. 抽取的样本就隐含了自身的期望. 因此我们可以使用平均数代替上式中的期望, 公式改写如下.
V ( G , D ) = ∫ q ( x ) l o g D ( x ) d x + ∫ q ( z ) l o g ( 1 − D ( G ( z ) ) ) d z = 1 m ∑ i = 1 m l o g D ( x i ) + 1 m ∑ i = 1 m l o g ( 1 − D ( G ( z i ) ) ) V(G,D)=\int q(x)\;log\;D(x)\;dx+\int q(z)\;log\;(1-D(G(z)))\;dz\\ \;\\ =\frac{1}{m}\sum_{i=1}^{m}log\;D(x_i) + \frac{1}{m}\sum_{i=1}^{m}log\;(1-D(G(z_i))) V(G,D)=∫q(x)logD(x)dx+∫q(z)log(1−D(G(z)))dz=m1i=1∑mlogD(xi)+m1i=1∑mlog(1−D(G(zi)))
我们可以直接用上式训练鉴别器 D ( x ) D(x) D(x).
在训练生成器时, 因为前半部分和 z z z 无关, 我们可以只使用后半部分.
全文完.