基于Scala的产品开发实践 -
http://www.jianshu.com/p/9895fda11123
我们的产品架构
整体架构
我们的产品代号为Mort(这个代号来自电影《马达加斯加》那只萌萌的大眼猴),是基于大数据平台的商业智能(BI)产品。产品架构如下所示:
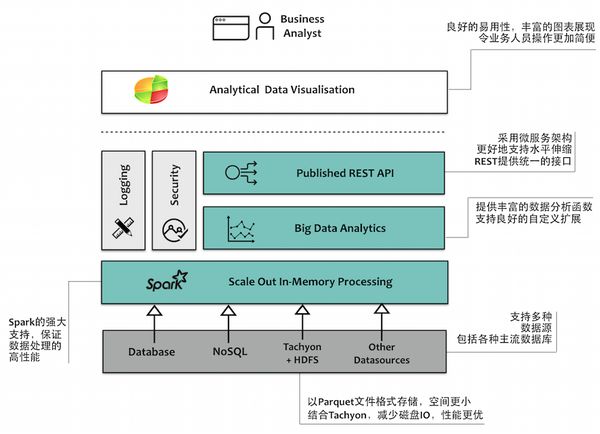
Mort的产品架构
我们选择了Spark作为我们的大数据分析平台。基于目前的应用场景,主要使用了Spark SQL,目前使用的版本为Spark 1.5.0。我们有计划去同步升级Spark最新版本。
在研发期间,我们从Spark 1.4升级到1.5,经过性能测评的Benchmark,性能确有显著提高。Spark 1.6版本在内存管理方面有明显的改善,Execution Memory与Store Memory的比例可以动态分配,但经过测试,产品的主要性能瓶颈其实是CPU,因为产品的数据分析功能属于计算密集型。这是我们暂时没有考虑升级1.6的主因。
从第一次升级Spark的性能测评,以及我们对这一年来Spark版本演进的观察,我们对Spark的未来充满信心,尤其是Tungsten项目计划,会在内存管理、代码生成以及缓存管理等多方面都会有所提高,对于我们产品而言,算是“坐享其成”了。
由于我们要分析的维度和指标是由客户指定的,这就需要数据分析的聚合操作是灵活可定制的。因此,我们的产品写了一个简单的语法Parser,用以组装Spark SQL的SQL语句,用以执行分析,最后将DataFrame转换为我们期待的数据结构返回给前端。
但是,这种设计方案其实牵涉到两层解析的性能损耗,一个是我们自己的语法Parser,另一个是Spark SQL提供的Parser(通过它将其解析为DataFrame的API调用)。我们考虑在将来会调整方案,直接将客户定制的聚合操作解析为对DataFrame的API调用(可能会使用新版本Spark的DataSet)。
微服务架构
我们的产品需要支持多种数据源,对数据源的访问是由另外一个standalone的服务CData完成的,通过它可以隔离这种数据源的多样性。这相当于一个简单的微服务架构,目前仅提供两个服务,一个服务用于数据分析,一个服务用于对客户数据源的处理:

微服务架构
未来,我们的产品不止限于现有的两个服务,例如我正在考虑将定期的邮件导出服务独立出来,保证该服务的独立性,避免受到其他功能执行的影响。因为这个功能一旦失败,可能会对客户的业务产生重要影响。然而,我们还是在理智地控制服务的粒度。我们不希望因为盲目地追求微服务架构,而带来运维上的成本。
元数据架构
我们的产品需要存储元数据(Metadata),用以支持Report、Dashboard以及数据分析,主要的数据模型结果如图所示:
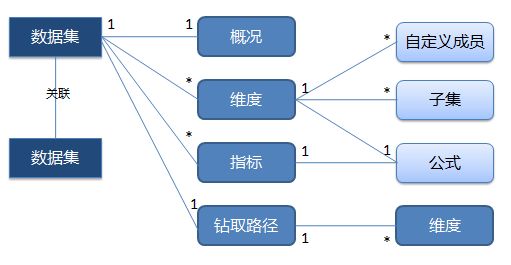
元数据结构
针对元数据的处理逻辑,我们将之分为职责清晰的三层架构。自上而下分别为REST路由层、应用服务层和元数据资源库层。
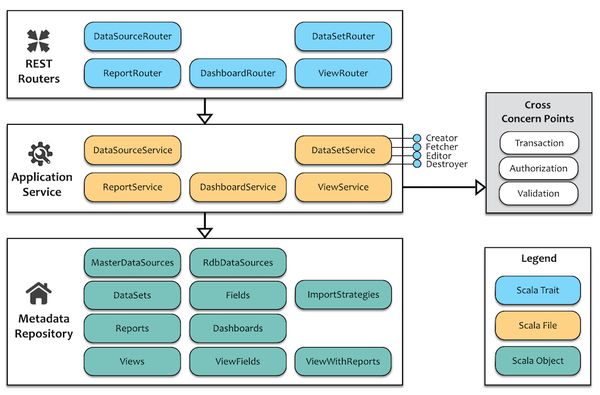
分层架构
REST路由层:将元数据视为资源,响应客户端的HTTP请求,并利用Spray Route将请求路由到对应的动词上。路由层为核心资源提供Router的trait。这些Router只负责处理客户端请求,以及服务端的响应,不应包含具体的业务逻辑。传递的消息格式为Json格式,由Spray实现消息到Json数据的序列化与反序列化。
应用服务层:每个应用服务对应元数据资源的操作用例。由于Mort对元数据的操作并没有非常复杂的业务逻辑,因此这些服务实际上成为了Router到Repository的中转站,目的是为了隔离REST路由层对元数据资源库的依赖。每个服务都被细分为Creator、Editor、Fetcher与Destroyer这样四个细粒度的trait,并放在对应服务的同一个scala文件中。同时,应用服务要负责保障元数据操作的数据完整性和一致性,因而引入了横切关注点(Cross Concern Points)中的事务管理。同时,对操作的验证以及权限和授权操作也会放到应用服务中。
元数据资源库层:每个资源库对象都是一个Scala Object,并对应着数据库中的元数据表。这些对象中的CRUD操作都是原子操作。事实上我们可以认为每个资源库对象就是元数据的访问入口。在其实现中,实际上封装了scalikejdbc的访问逻辑。
REST路由层和应用服务层需要接收和返回的消息非常相似,甚至在某些场景中,消息结构完全相同,但我们仍然定义了两套消息体系(皆被定义为Case Class)。逻辑层与消息之间的关系如下图所示:
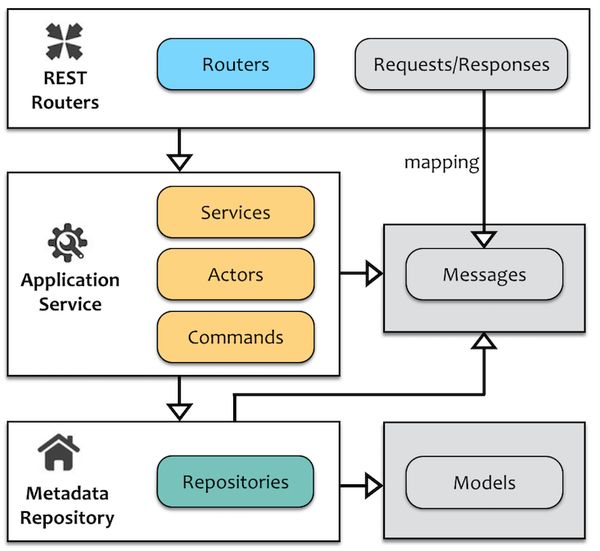
逻辑层与消息之间的关系
在REST路由层,所有的消息皆以Request或Response作为类的后缀名,并被定义为Scala的Case Class。在应用服务层以及元数据资源库层使用的消息对象则被单独定义在Messages模块中。此外,元数据资源库层还会访问由ScalikeJDBC生成的Model对象。
我们的技术选型
开发语言的选型
我们选择的语言是Scala。选择它的一个主因是因为Spark;另一个原因呢?或许是因为我确实不想再写Java代码了。
其实有时候我觉得语言的选型是没有什么道理的。除了特殊的应用场景,几乎所有的程序设计语言都能满足如今的软件开发需求。所以我悲哀地看到,语言的纷争成了宗教的纷争。
在我们团队,有熟悉Java的、有熟悉JavaScript包括NodeJS的,有熟悉Clojure的,当然也有熟悉Scala的。除了NodeJS,后端开发几乎都在JVM平台下。
我对语言选型的判断标准是:实用、高效、简洁、可维护。我对Java没有成见,但我始终认为:即使引入了Lambda以及Method Reference,Java 8在语法方面还是太冗长了。
Scala似乎从诞生开始,一直争议很大。早在2014年1月ThoughtWorks的Tech Radar中,就讲Scala列入了Adopt圈中,但却在其中特别标注了“the good parts”:
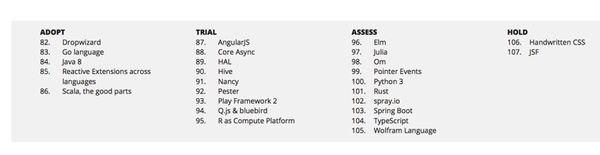
在2016年Stack Overflow发布的开发人员调查结果中,我们也收获了一些信心。在最爱语言的调查中,Scala排在了第四名:
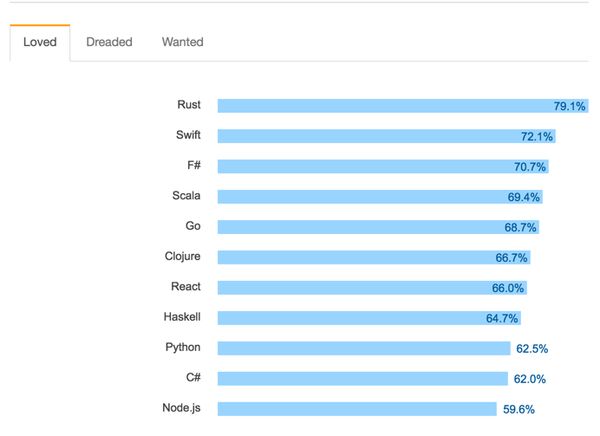
最爱语言排名
在引领技术趋势的调查中,我们选用的React与Spark分列冠亚军:
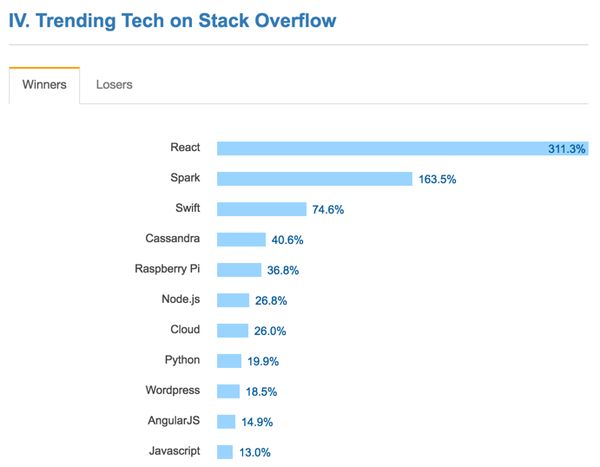
引领技术趋势排名
在Top Paying Tech调查中,在美国学习Spark和Scala所值不菲,居然并列冠军:

Top Paying Tech排名
其实有了微服务,在不影响代码维护性的情况下,使用多语言进行开发也成为了可能。或许在将来,我们产品的可能会用clojure或者Ruby来写DSL,用NodeJS负责元数据(以避免Spray + JSON4S不太好的Json对象序列化)。
说明:将元数据管理单独独立为一个NodeJS服务,已经列到了后续架构演进的计划中。针对元数据管理,我们会统一成JavaScript技术栈,从前端到后端再到数据库,统一为React+ES6、NodeJS和MongoDB。
坦白说,我没有强烈的语言倾向性。
数据集的选型
我们还有一个最初的技术选型,后来被认为是失败的选择。
CData服务需要将客户的数据源经过简单的ETL导入到系统中,我们称之为数据集(DataSet)。最初在进行技术选型时,我先后考虑过MySQL、Cassandra、HBase。后面两种都属于列式存储的NoSQL数据库。团队中没有一个人有Cassandra的经验,至于HBase,虽然支持高效的数据查询,但对聚合运算的支持明显不足,不适合我们的场景。再加上团队中有一位成员比较熟悉MySQL,我最终决定使用MySQL。
然而,我们的产品需要支持大数据,当数据量上升到一定级别时,就需要系统很好地支持水平扩展,通过增加更多机器来满足性能上的需求。评估我们的架构,后端平台可以简单划分为三个层次:Web应用服务层(Spray + Nginix)、数据分析层(MESOS + Spark)以及存储层(主要用于存储分析数据DataSet,MySQL)。显然,MySQL会成为水平伸缩的最大障碍。
还好我们醒悟得早,在项目初期就否定了这个方案,而改为采用HDFS+Parquet。
Parquet文件是一种列式数据存储结构,对于主要为分析型查询方式的BI数据操作,能够提供更好的查询性能。同时,Parquet文件存储的内容以二进制形式存放,相较于文本形式容量更小,可以节省更多的存储空间。Spark SQL提供了对访问Parquet文件很好的集成。将Parquet文件存放到HDFS中,然后再通过Spark SQL访问,可以保证在存储层与数据分析层都能很好地支持分布式处理,从而保证系统的水平伸缩。当对大规模数据集进行分析处理时,可以通过水平增加更多的节点来满足高性能的实时查询要求。
我们曾经比较了Parquet方案与MySQL方案,在同等配置下前者的性能要远远优于后者,且Spark对Parquet的支持也要好于MySQL。
为了更好地提升性能,我们还计划在HDFS层之上引入Tachyon,充分发挥内存的优势,减少磁盘IO带来的性能损耗。
前端的技术选型
前端的技术选型则为React + Redux。选择React的原因很简单,一方面我们认为这种component方式的前端开发,可以极大地提高UI控件的重用,另一方面,我们认为React这种虚拟DOM的方式在性能上存在一定优势。此外,React的学习曲线也不高,很容易上手。我们招了3个大学还未毕业的实习生,JS基础非常薄弱,在我们的培养下,一周后就可以慢慢开始完成React Component开发的小Story了。
在最初的团队,我们仅有一位前端开发。他选择了使用CoffeeScript来开发React,但是在项目早期,我们还是忍痛去掉了这些代码,改为使用ES 6。毕竟随着ES 6乃至ES 7的普及,JS的标准已经变得越来越合理,CoffeeScript的生存空间似乎被压缩了。
在前端技术选型方面,我们经历了好几次演变。从CoffeeScript到ES 6,从Reflux到Redux,每次变化都在一定程度上增加了工作量。我在文章《技术选型的理想与现实》中讲述的就是这个故事。
在《技术选型的理想与现实》这篇文章中,我讲到我们选择了Reflux。然而到现在,最终还是迁移到了Redux。我们一开始并没有用好Redux,最近的一次重构才让代码更符合Redux的最佳实践。
结论
技术负责人一个非常重要的能力要求就是——善于做出好的技术决策。选择技术时,并不能一味追求新技术,也不能以自我为中心,选择“我”认为好的技术。而应该根据产品的需求场景、可能的技术风险、团队成员能力,并通过分析未来的技术发展趋势综合地判断。
技术决策不可能一成不变,需要与时俱进。如果发现决策错误,应该及时纠正,不要迟疑,更不要担心会影响自己的技术声誉。
我们的技术实践
与大多数团队相比,因为我们使用了小众的Scala,可以算得上是“捞偏门”了,所以总结的技术实践未必具有普适性,但对于同为Scala的友朋,或许值得借鉴一二。Scala社区发出的声音还是太小,有点孤独——“鹦其鸣也,求其友声”。
这些实践不是书本上的创作,而是在产品研发中逐渐演化而来,甚至一些实践会非常细节。不过,那个优秀的产品不是靠这些细节堆砌出来的呢?
Scala语言的技术实践
两年前我还在ThoughtWorks的时候,与同事杨云(大魔头)在一个Scala的大数据项目,利用工作之余,我结合了一些文档整理了一份Scala编码规范,放在了github上:Scala编码规范与最佳实践。
我们的产品后端全部由Scala进行开发。对于编写Scala代码,我的要求很低,只有两点:
写出来的代码尽可能有scala范儿,不要看着像Java代码
不要用Scala中理解太费劲儿的语法,否则不利于维护
对于Scala编程,我们还总结了几条小原则:
将业务尽量分布到小的trait中,然后通过object来组合
多用函数或偏函数对逻辑进行抽象
用隐式转换体现关注点分离,既保证了职责的单一性,又保证了API的流畅性
用getOrElse来封装需要两个分支的模式匹配
对于隐式参数或支持类型转换的隐式调用,应尽量让import语句离调用近一些;对于增加方法的隐式转换(相当于C#的扩展方法),则应将import放在文件头,保持调用代码的干净
在一个模块中,尽量将隐式转换定义放到implicits命名空间下,除非是特别情况需要放到package object中
在不影响可读性的情况下,且无需封装任何行为,可以考虑使用tuple,而非case class
在合适的地方使用lazy关键字
AKKA的技术实践
我们产品用的AKKA并不够深入,仅仅使用了AKKA的基本功能。主要用于处理前端发来的数据分析消息,相当于一个dispatcher,也承担了部分消息处理的职责,例如对消息包含的元数据进行解析,生成SQL语句,用以发送给Spark的SqlContext。分析的结果则以Future的方式返回给Spray。
几条AKKA实践的小原则:
actor接收的消息可以分为command和event两类。命名时,前者用动宾短语,表现为命令请求;后者则使用过去时态,体现fact的本质。
产品需要支持多种数据源,不同数据源的处理逻辑放到不同的模块中,我们利用actor来解耦
以下是为AKKA的ActorRefFactory定义的工厂方法:
trait ActorSupport { implicit val requestTimeout: Timeout = ActorConfig.requestTimeout def actorOf(className: String)(implicit refFactory: ActorRefFactory, trackID: TrackID = random): ActorRef = refFactory.actorOf(new Props(Props.defaultDeploy, Class.forName(className).asInstanceOf[Class[Actor]], List.empty), id(className)) def actorOf[T <: Actor : ClassTag](implicit refFactory: ActorRefFactory, trackID: TrackID = random): ActorRef = refFactory.actorOf(Props[T], id(classTag[T].toString)) def actorOf[T <: Actor : ClassTag](initial: ActorRefFactory)(implicit trackID: TrackID = random): ActorRef = initial.actorOf(Props[T], id(classTag[T].toString))}
通过向自定义的工厂方法actorOf()传入Actor的名称来创建Actor:
def importDataSetData(dataSetId: ID) { val importDataSetDataActor = actorOf(actorByPersistence("import"))(actorRefFactory) importDataSetDataActor ! ImportDataSet(dataSetId)}def createDataSetPersistence: Future[Any] = { val createDataSetPersistenceActor = actorOf(actorByPersistence("create"))(actorRefFactory) createDataSetPersistenceActor ? dataSet}
注意actor的sender不能离开当前的ActorContext
采用类似Template Method模式的方式去扩展Actor
trait ActorExceptionHandler extends MortActor { self: Actor =>override def receive: Receive = { case any: Any => try { super.receive(any) } catch { case notFound: ActorNotFound => val errorMsg: String = s"invalid parameters: ${notFound.toString}" log.error(errorMsg) exceptionSender ! ExecutionFailed(BadRequestException(s"invalid parameters ${notFound.getMessage}"), errorMsg) case e: Throwable => exceptionSender ! ExecutionFailed(withTrackID(e, context.self.path.toString), e.getMessage) } } def exceptionSender = sender}
或者以类似Decorator模式扩展Actor
trait DelegationActor extends MortActor { this: Actor =>private val executionResultHandler: Receive = { case _: ExecutionResult => } override def receive: Receive = { case any: Any => try { (mortReceive orElse executionResultHandler) (any) } catch { case e: Throwable => log.error(e, "") self ! ExecutionFailed(e) throw e } finally { any match { case _: ExecutionResult => self ! PoisonPillcase _ => } } }}
考虑建立符合项目要求的SupervisorStrategy
尽量利用actor之间的协作来传递消息,这样就可以尽量使用tell而不是ask
Spark SQL的技术实践
目前的产品特性还未用到更高级的Spark功能。针对一些特殊的客户,我们计划采用Spark Streaming来进行流处理,除此之外,核心的数据分析功能都是使用Spark SQL。
以下是我们的一些总结:
要学会使用Spark Web UI来帮助我们分析运行指标;另外,Spark本身提供了与Monitoring有关的REST接口,可以集成到自己的系统中;
考虑在集群环境下使用Kryo serialization;
让参与运算的数据与运算尽可能地近,在SparkConf中注意设置spark.locality值。注意,需要在不同的部署环境下修改不同的locality值;
考虑Spark SQL与性能有关的配置项,例如spark.sql.inMemoryColumnarStorage.batchSize
和spark.sql.shuffle.partitions
;
Spark SQL自身对SQL执行定义了执行计划,而且从执行结果来看,对SQL执行的中间结果进行了缓存,提高了执行的性能。例如我针对相同量级的数据在相同环境下,连续执行了如下三条SQL语句:
第一次执行的SQL语句:
SELECT UniqueCarrier,Origin,count(distinct(Year)) AS Year FROM airline GROUP BY UniqueCarrier,Origin
第二次执行的SQL语句:
SELECT UniqueCarrier,Dest,count(distinct(Year)) AS Year FROM airline GROUP BY UniqueCarrier,Dest
第三次执行的SQL语句:
SELECT Dest , Origin , count(distinct(Year)) AS Year FROM airline GROUP BY Dest , Origin
观察执行的结果如下所示:

执行结果
观察执行count操作的job,显然第一次执行SQL时的耗时最长,达到2s,而另外两个job执行的时间则不到一秒。
针对复杂的数据分析,要学会充分利用Spark提供的函数扩展机制:UDF((User Defined Function)与UDAF(User Defined Aggregation Function);详细内容,请阅读文章《Spark强大的函数扩展功能》。
React+Redux的技术实践
我们一开始并没有用好React+Redux。随着对它们的逐渐熟悉,结合社区的一些实践,我们慢慢体会到了其中的一些好处,也摸索出一些好的实践。
遵循组件设计的原则,我们将React组件分为Component与Container两种,前者为纯组件。
组件设计的原则
一个纯组件利用props接受所有它需要的数据,类似一个函数的入参,除此之外它不会被任何其它因素影响;
一个纯组件通常没有内部状态。它用来渲染的数据完全来自于输入props,使用相同的props来渲染相同的纯组件多次,
将得到相同的UI。不存在隐藏的内部状态导致渲染不同。
在React中尽可能使用extends而不是mixin;
对State进行范式化,不要定义嵌套的State结构,不同数据的相互引用都通过ID来查找。范式化的state可以更有效地利用Store里存储空间;
如果不能更改后端返回的模型,可以考虑使用normalizr;但在我们的项目中,为了满足这一要求,我们专门修改了后端的API。因为采用了之前介绍的元数据架构,这个修改主要影响到了REST路由层和应用服务层的部分代码;
遵循Redux的三大基本原则;
Redux的三大基本原则
单一数据源
State 是只读的
使用纯函数来执行修改
在我们的项目中,将所有向后台发送异步请求的操作都封装到service中,action会调用这些服务。我们使用了redux-actions的createAction创建dispatch需要的消息:
export const loadDataSource = (id) => { return dispatch => { return DataSourceServices.getDataSource(id) .then(dataSource => { dispatch(createAction(DataSourceActionTypes.DATA_SOURCE_RECEIVED)(dataSource)) }) }}
在Reducer中,通过redux-actions的handleAction来处理action,避免使用丑陋的switch语句:
export const dataSources = handleActions({ [DataSourceActionTypes.DATA_SOURCES_RECEIVED]: (state, {payload}) => { const newState = reduce(payload, (result, dataSource) => { set(result, dataSource.id, dataSource) return result }, state) return assign({}, newState) }, [DataSourceActionTypes.DATA_SOURCE_RECEIVED]: (state, {payload}) => { set(state, payload.id, payload) return assign({}, state) }, [DataSourceActionTypes.DATA_SOURCE_DELETED]: (state, {payload}) => { return omit(state, payload) }}, {})
在Container组件中,如果Store里面的模型对象需要根据id进行filter或merge之类的操作,则交给selector对其进行封装。于是Container组件中就可以这样来调用:
@connect(state => { return { dataSourcesOfDirectory: DataSourcesSelectors.getDataSourcesOfDirectory(state), dataSetsOfDataSource: DataSetsSelectors.getDataSetsOfDataSource(state), selectedDataSource: DataSourcesSelectors.getSelectedDataSource(state), currentDirectory: DataSourcesSelectors.getCurrentDirectory(state), memories: state.next.commons.memories }}, { loadDataSourcesOfDirectory: DataSourcesActions.loadDataSourcesOfDirectory, selectDataSource: selectedDataSourceAction.selectDataSource, cleanSelectedDataSource: selectedDataSourceAction.cleanSelectedDataSource, loadDataSetsOfDataSource: DataSetsActions.loadDataSetsOfDataSource, updateDataSource: DataSourcesActions.updateDataSource, deleteDataSource: DataSourcesActions.deleteDataSource, navigate: commonActions.navigate, memory: memoryActions.memory, cleanMemory: memoryActions.cleanMemory, goToNewDataSource: NavigationActions.goToNewDataSource})
使用eslint来检查代码是否遵循ES编写规范;为了避免团队成员编写的代码不遵守这个规范,甚至可以在git push之前将lint检查加入到hook中:
echo "npm run lint" > .git/hooks/pre-pushchmod +x .git/hooks/pre-push
Spray与REST的技术实践
我们的一些总结:
站在资源(名词)的角度去思考REST服务,并遵循REST的规范;
考虑GET、PUT、POST、DELETE的安全性与幂等性;
必须为REST服务编写API文档,并及时更新;
使用REST CLIENT对REST服务进行测试,而不能盲目地信任Spray提供的ScalatestRouteTest对客户端请求的模拟,因为这种模拟其实省略了对Json对象的序列化与反序列化;
为核心的REST服务提供健康服务检查;

服务的健康检查
在Spray中,尽量将自定义的HttpService定义为trait,这样更利于对它的测试;在自定义的HttpService中,采用cake pattern(使用Self Type)的方式将HttpService注入;
我个人不太喜欢Spray以DSL方式编写REST服务,因为它可能让函数的嵌套层次太深;如果在一个HttpService(在我们的项目中,皆命名为Router)中,提供的服务较多,建议将各个REST动作都抽取为一个返回Route对象的私有函数,然后利用RouteConcatenation的~运算符拼接起来,以便于阅读:
def reportRoute(implicit userId: ID) = pathPrefix("reports") { getReport ~ getViewsOfReport ~ createReport ~ updateReport ~ deleteReport ~ getVirtualField ~ getVirtualFields ~ fuzzyMatch ~ createVirtualField}
Spray默认对Json序列化的支持是使用的是Json4s,为此Spray提供了Json4sSupport trait;如果需要支持更多自定义类型的Json序列化,需要重写隐式值json4sFormats;建议将这些隐式定义放到Object中,交由Router引用,而不是定义为trait去继承。因为并非Router都使用Json格式,由于trait定义的继承传递性,可能会导致未使用Json格式的Router出现错误;
Json4s可以支持Scala的大多数类型,包括Option等,但不能很好地支持Scala枚举以及复杂的嵌套递归结构,包括多态。这时需要自定义Serializer。具体细节请阅读我的文章《Spray中对复杂Json的序列化与反序列化》。
文/张逸(作者)原文链接:http://www.jianshu.com/p/9895fda11123著作权归作者所有,转载请联系作者获得授权,并标注“作者”。