空间变换网络STN
出自论文Spatial Transformer Networks
Insight:
文章提出的STN的作用类似于传统的矫正的作用。比如人脸识别中,需要先对检测的图片进行关键点检测,然后使用关键点来进行对齐操作。但是这样的一个过程是需要额外进行处理的。但是有了STN后,检测完的人脸,直接就可以做对齐操作。关键的一点就是这个矫正过程是可以进行梯度传导的。想象一下,人脸检测完了,直接使用ROI pooling取出人脸的feature map,输入STN就可以进行矫正,输出矫正后的人脸。后面还可以再接点卷积操作,直接就可以进行分类,人脸识别的训练。整个流程从理论上来说,都有梯度传导,理论上可以将检测+对齐+识别使用一个网络实现。当然实际操作中可能会有各种trick。
空间变换基础:
2D仿射变换(affine):
平移:

旋转:

缩放:

3D透视变换(projection):
平移:
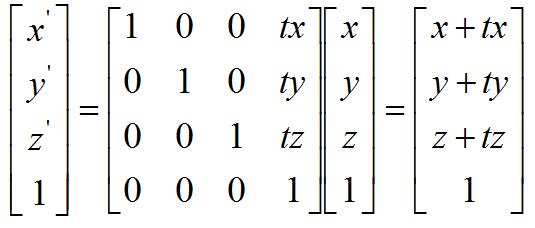
旋转:

缩放:

STN网络结构:

STN网络由Localisation Network ,Grid generator,Sampler,3个部分组成。
Localisation Network:
该网络就是一个简单的回归网络。将输入的图片进行几个卷积操作,然后全连接回归出6个角度值(假设是仿射变换),2*3的矩阵。
Grid generator:
网格生成器负责将V中的坐标位置,通过矩阵运算,计算出目标图V中的每个位置对应原图U中的坐标位置。即生成T(G)。
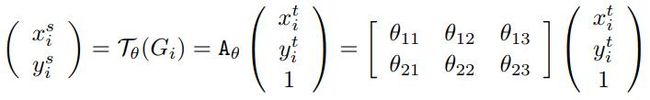
这里的Grid采样过程,对于二维仿射变换(旋转,平移,缩放)来说,就是简单的矩阵运算。
上式中,s代表原始图的坐标,t代表目标图的坐标。A为Localisation Network网络回归出的6个角度值。
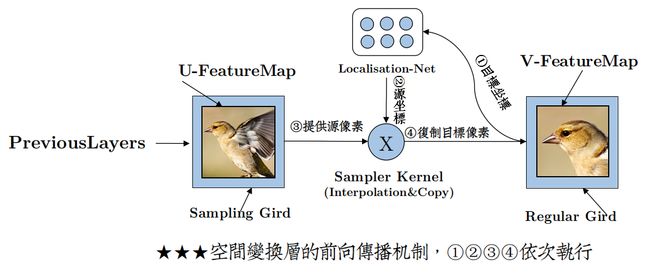
整个Grid生成过程就是,首先你需要想象上图中V-FeatureMap中全是白色或者全是黑色,是没有像素信息的。也就是说V-FeatureMap还不存在,有的只是V-FeatureMap的坐标位置信息。然后将目标图V-FeatureMap中的比如(0,0)(0,1)......位置的坐标,与2*3变换矩阵运算。就会生成出在原始图中对应的坐标信息,比如(5,0)(5,1)......。这样所有的目标图的坐标都经过这样的运算就会将每个坐标都产生一个与之对应的原图的坐标,即T(G)。然后通过T(G)和原始图U-FeatureMap的像素,将原始图中的像素复制到V-FeatureMap中,从而生成目标图的像素。
Sampler:
采样器根据T(G)中的坐标信息,在原始图U中进行采样,将U中的像素复制到目标图V中。
实验结果:
作者分别在MNIST,Street View House Numbers ,CUB-200-2011 birds dataset 这3个数据集上做了实验。
MNIST实验:
R:rotation (旋转)
RTS:rotation, scale and translation (旋转,缩放,平移)
P:projective transformation (投影)
E:elastic warping (弹性变形)
从作图可以看出,FCN 错误率为13.2% , CNN 错误率为3.5% , 与之对比的 ST-FCN 错误率为2.0% ,ST-CNN 错误率为 1.7%。可以看出STN的效果还是非常明显的。
Street View House Numbers实验:

可以看出不管是64像素还是128像素,ST-CNN比传统的CNN错误率要低一些。
CUB-200-2011 birds dataset实验:

右图红色框检测头部,绿色框检测身体。
这个数据集是属于细粒度分类的一个数据集。好多做细粒度分类的文章都会在该数据集上做实验。从这个实验可以看出,STN可以有attention的效果,可以训练的更加关注ROI区域。
实验结果有0.8个百分点的提升。
References:
https://github.com/kevinzakka/spatial-transformer-network