FCN训练自己的数据集
本人研究生,最近在做关于FCN的课题,因为要实现论文中的算法,所以自己要实现FCN,也参考了很多网络上的博客,自己做个小的总结,以及遇到的一些问题解决方案。
一、CAFFE的安装
这里我不赘述,因为有很多教程,大家可以参考:
http://blog.csdn.net/Tang_DH/article/details/52556636
http://blog.csdn.net/xierhacker/article/details/53035989#python
中有很详细的说明。而FCN的例程运行可以参考:
http://blog.csdn.net/u013059662/article/details/52770198
我在以上步骤中遇到的问题基本上在上面博客中都有解答,有的网盘数据集下不了的可以到上面博客的评论区,里面有相应的解答。
二、FCN运行自己的数据集
我用的数据集是自己在论文中使用的DVMM数据集,是拼接检测的数据集。一些图像如下图:
然后制作训练集和验证集,图像本身是不用做处理直接保存到一个train文件夹和test文件夹,然后制作标签,我用的是windos的命令来制作的:cd到数据集的文件夹下执行:
dir/s/on/b>d:/train.txt
可以在D盘根目录下生成一个txt文件,然后使用替换命令去除文件格式和文件路径。另一个验证集也同样制作。
然后就是制作图像的label图,因为很多人不习惯用mat文件表示分割,我也是,所以就在网上找是否可以直接用图片的方式来做分割图,(虽然后来发现还是应该用mat文件比较方便。。。。),于是在
http://blog.csdn.net/supe_king/article/details/58121993
中找到了很好的方法,修改了voc_layers.py中的训练集的分割图的读取方式,即使用VOCSegDataLayer中的load_label代替SBDDSegDataLayer中的load_label方法,并修改voc_dir为sbdd_dir。我用的数据集中是提供一个mask的文件的,就是分割图,如下图

但是这样的彩色图片不能直接作为分割图,matlab可以用起来了。。。
因为我想做二分类的问题,但是想一步步来,我首先将其转换为灰度图像,代码如下:
file_path = 'C:\Users\qxm\Desktop\新建文件夹 (2)\';% 图像文件夹路径
img_path_list = dir(strcat(file_path,'*.jpg'));%获取该文件夹中所有jpg格式的图像
img_num = length(img_path_list);%获取图像总数量
if img_num > 0 %有满足条件的图像
for j = 1:img_num %逐一读取图像 6
image_name = img_path_list(j).name;% 图像名
i = strfind(image_name,'.j');
%去除文件后缀,提取单纯的文件名
imname = image_name(1:i-1);
image = imread(strcat(file_path,image_name));
fprintf('%d %d %s\n',i,j,strcat(file_path,image_name));% 显示正在处理的图像名
%图像处理过程 省略
image = rgb2gray(image);
imwrite(image,strcat('C:\Users\qxm\Desktop\mask\',imname,'.jpg'));
end
end
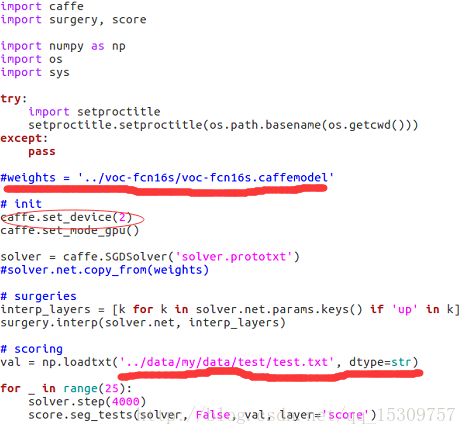
接下来就修改网络的结构文件,我使用的是FCN目录下的voc-fcn8s的这个文件夹里的文件,首先将其FCN目录下的surgery.py,voc_layers.py,score.py复制到voc-fcn8s文件夹下,然后打开solver.py,第一个红线所表示的内容是下载的训练模型,我这里注释掉了,也可以不注释,注释掉就表示只是用自己的数据来训练,收敛效果可能会差些。第二个红线所表示的就是要修改的我们刚刚生成的test.txt的保存路径,这个因你设置而定,而红线圈出来的则表示的是你使用的GPU,如果只有一个GPU就可以注释掉这句,我这里用的是2号GPU即第3个GPU。
接着修改的voc-layers.py在上面提过了,可以在那篇博客里看更详细的修改方法。
接着修改train.prototxt和val.prototxt两个文件,下图红线中部分中../data/my是我的保存数据的路径。另外需要修改的就是原网络是分割21类的,而我要做的是2分类的,所以将num_output:21都换为2。这里要注意,如果你要使用训练好的模型,即我在solver.py注释掉的那个,你需要更改下层的名字,因为我没有用,所以就没有改。

然后修改solver.prototxt文件,如下图,要修改的有下面的保存的快照路径。

然后cd到voc-fcn8s路径下,执行python solver.py就开始训练了。
下面是我遇到的问题:
1、out of memory
这个问题出现真的好烦,除了修改batch_size和更换大的GPU,就是调整图片的大小了,我一开始就因为笔记本的GPU过小运行不了,但后来我用GTX 1080TI还是出现了这个问题。。。我才统一了训练集和验证集的图片为256*256的才行。
2、Check failed: status == CUBLAS_STATUS_SUCCESS (11 vs. 0) CUBLAS_STATUS_MAPPING_ERROR
这个问题出现我当时也是一头雾水。。。后来查了在CNN中是因为训练集的大小与label不一致,即用18类不同的图像做训练集而你的label只有2。我遇到时才想起来我们使用的是图像label,那么就是你图像中有多少个不同的像素值,就是分成了多少类。。我设置只是灰度图像基本上是0—255。。。。而我设置的num_output是2.。。肯定出现这个问题,所以这里要将我的灰度图像转换为二值图像,而用matlab转换后我保存为jpg文件后,还是出现了这个问题。。。真尴尬,后来我把图片又imread后发现,我修改的二值图像中并不是只有0和255,还有很多其他像素值,这是为什么。。。我查了才发现是jpg有损压缩的问题。。所以保存我们的图像为bmp文件就好了。
3、IOError:cannot identify image file
这个问题我查了很多资料说是将import image 换成from PIL import image,然而我们是在官方的改的啊,根本没这个错误,然后我发现是我的linux没有安装相应的依赖包,所以from PIL 就相当于没用,
pip uninstall Pillow
sudo pip install pillow