PSPNet测试代码解读
PSPNet测试代码在原文《Pyramid Scene Parsing Network》作者的GitHub网站上https://github.com/hszhao/PSPNet,下载下来解压后找到evaluation文件夹,里面的六个.m文件(Matlab代码)就是测试时用的代码,如下图所示:
1.代码解读
上图中的run.sh是执行文件,其代码解读如下:
matlab -nodisplay -r "eval_all;exit" 2>&1 | tee matlab.log其中,-nodisplay和-r均为matlab命令,前者表示启动jvm,但不启动desktop,不启动任何显示相关的,效果如下图:
后者表示执行后面的代码,且代码间需要用';'分开,也即形如上述的"eval_all;exit"。
代码中的'2>&1' 的意思就是将标准错误重定向到标准输出(1表示标准输出,2表示标准错误)。
tee matlab.log表示将数据重定向到文件matlab.log,即程序运行过程中的所有输出都会写入这个日志里(包括报错的信息)。
从里面的代码中也可以看出,测试开始进入的是eval_all.m文件,由此我们先从这个文件开始分析测试代码。
eval_all.m文件中的源代码如下:
%{
Variables need to be modified: data_root, eval_list;
and the default GPUs used for evaluation are with ID [0:3],
modify variable 'gpu_id_array' if needed.
%}
close all; clc; clear;
addpath('../matlab'); %add matcaffe path
addpath('visualizationCode');
data_name = 'ADE20K'; %set to 'VOC2012' or 'cityscapes' for relevant datasets
switch data_name
case 'ADE20K'
isVal = true; %evaluation on valset
step = 500; %equals to number of images divide num of GPUs in testing e.g. 500=2000/4
data_root = '/data2/hszhao/dataset/ADEChallengeData2016'; %root path of dataset
eval_list = 'list/ADE20K_val.txt'; %evaluation list, refer to lists in folder 'samplelist'
save_root = 'mc_result/ADE20K/val/pspnet50_473/'; %root path to store the result image
model_weights = 'model/pspnet50_ADE20K.caffemodel';
model_deploy = 'prototxt/pspnet50_ADE20K_473.prototxt';
fea_cha = 150; %number of classes
base_size = 512; %based size for scaling
crop_size = 473; %crop size fed into network
data_class = 'objectName150.mat'; %class name
data_colormap = 'color150.mat'; %color map
case 'VOC2012'
isVal = false; %evaluation on testset
step = 364; %364=1456/4
data_root = '/data2/hszhao/dataset/VOC2012';
eval_list = 'list/VOC2012_test.txt';
save_root = 'mc_result/VOC2012/test/pspnet101_473/';
model_weights = 'model/pspnet101_VOC2012.caffemodel';
model_deploy = 'prototxt/pspnet101_VOC2012_473.prototxt';
fea_cha = 21;
base_size = 512;
crop_size = 473;
data_class = 'objectName21.mat';
data_colormap = 'colormapvoc.mat';
case 'cityscapes'
isVal = true;
step = 125; %125=500/4
data_root = '/data2/hszhao/dataset/cityscapes';
eval_list = 'list/cityscapes_val.txt';
save_root = 'mc_result/cityscapes/val/pspnet101_713/';
model_weights = 'model/pspnet101_cityscapes.caffemodel';
model_deploy = 'prototxt/pspnet101_cityscapes_713.prototxt';
fea_cha = 19;
base_size = 2048;
crop_size = 713;
data_class = 'objectName19.mat';
data_colormap = 'colormapcs.mat';
end
skipsize = 0; %skip serveal images in the list
is_save_feat = false; %set to true if final feature map is needed (not suggested for storage consuming)
save_gray_folder = [save_root 'gray/']; %path for predicted gray image
save_color_folder = [save_root 'color/']; %path for predicted color image
save_feat_folder = [save_root 'feat/']; %path for predicted feature map
scale_array = [1]; %set to [0.5 0.75 1 1.25 1.5 1.75] for multi-scale testing
mean_r = 123.68; %means to be subtracted and the given values are used in our training stage
mean_g = 116.779;
mean_b = 103.939;
acc = double.empty;
iou = double.empty;
gpu_id_array = [0:3]; %multi-GPUs for parfor testing, if number of GPUs is changed, remember to change the variable 'step'
runID = 1;
gpu_num = size(gpu_id_array,2);
index_array = [(runID-1)*gpu_num+1:runID*gpu_num];
parfor i = 1:gpu_num %change 'parfor' to 'for' if singe GPU testing is used
eval_sub(data_name,data_root,eval_list,model_weights,model_deploy,fea_cha,base_size,crop_size,data_class,data_colormap, ...
is_save_feat,save_gray_folder,save_color_folder,save_feat_folder,gpu_id_array(i),index_array(i),step,skipsize,scale_array,mean_r,mean_g,mean_b);
end
if(isVal)
eval_acc(data_name,data_root,eval_list,save_gray_folder,data_class,fea_cha);
end解读如下:
%{
运行次代码前,有些参数需要修正:data_root(数据存放根目录),eval_list(测试/验证集索引路径),
gpu_id_array(所用到的GPU索引,需要根据自己的GPU数目进行修改,并修改相应的step参数),
其余一些路径适当修改。
Variables need to be modified: data_root, eval_list;
and the default GPUs used for evaluation are with ID [0:3],
modify variable 'gpu_id_array' if needed.
%}
close all; clc; clear;
addpath('/home/b622/PSPNet-master/matlab'); %matcaffe所在路径(此处读者需要修改为自己的路径,最好为绝对路径)
addpath('visualizationCode'); %可视化代码所在路径(其实是要调用每一类的颜色信息,并不是代码)
data_name = 'VOC2012'; %按照自己要测试的数据集进行测试(我用的VOC2012测试集,该测试集需要注册才能下载)
switch data_name
case 'ADE20K'
isVal = true; %evaluation on valset
step = 500; %equals to number of images divide num of GPUs in testing e.g. 500=2000/4
data_root = '/data2/hszhao/dataset/ADEChallengeData2016'; %root path of dataset
eval_list = 'list/ADE20K_val.txt'; %evaluation list, refer to lists in folder 'samplelist'
save_root = 'mc_result/ADE20K/val/pspnet50_473/'; %root path to store the result image
model_weights = 'model/pspnet50_ADE20K.caffemodel';
model_deploy = 'prototxt/pspnet50_ADE20K_473.prototxt';
fea_cha = 150; %number of classes
base_size = 512; %based size for scaling
crop_size = 473; %crop size fed into network
data_class = 'objectName150.mat'; %class name
data_colormap = 'color150.mat'; %color map
case 'VOC2012'
isVal = false; %false的原因是VOC2012的测试集是没有标注过的,即无法得到标记y,故只能展现分割效果,却无法验证精度
step = 728; %728=1456/2 由于我这边只有两块GPU,故将测试集一分为二,每块GPU测试一半
%注意路径要严格按照以下样例填写:
%data_root是存放数据集的根目录路径,最后不能添加符号'/',因为测试集索引文件,例如PSPNet-master/evaluation/samplelist下的
%VOC2012_test.txt索引文件,其每一张测试图的索引格式形如'/JPEGImages/2008_000006.jpg'
%故data_root的路径下必须有文件夹JPEGImages,且最后不能有'/'
%eval_listu即测试集索引文件,需放在data_root目录下
data_root = '/media/b622/My Passport/VOC2012'; %修改为自己存放数据的根目录
eval_list = '/VOC2012_test.txt';
save_root = '/media/b622/My Passport/VOC2012test/'; %自行设置,但要注意最后需有'/'
model_weights = '/media/b622/My Passport/SPSNet/pspnet101_VOC2012.caffemodel'; %模型存放路径(在PSPNet-master/evaluation/model下能找到)
model_deploy = 'prototxt/pspnet101_VOC2012_473.prototxt'; %模型的deploy.prototxt存放路径(在PSPNet-master/evaluation/prototxt下能找到)
fea_cha = 21; %VOC2012共21类
base_size = 512; %图像的基本大小(可以在此参数上实现多尺寸测试)
crop_size = 473; %裁剪大小(由于训练的网络的输入图像大小为473×473,故需要对图像进行裁剪,详细见后面其余文件的代码分析)
data_class = 'objectName21.mat'; %objectName21.mat里存放每一类的名称
data_colormap = 'colormapvoc.mat'; %colormapvoc.mat为调色板,存放每一类颜色的RGB信息(Matlab下归一化到0-1)
case 'cityscapes'
isVal = true;
step = 125; %125=500/4
data_root = '/data2/hszhao/dataset/cityscapes';
eval_list = 'list/cityscapes_val.txt';
save_root = 'mc_result/cityscapes/val/pspnet101_713/';
model_weights = '/media/b622/My Passport/SPSNet/pspnet101_cityscapes.caffemodel';
model_deploy = 'prototxt/pspnet101_cityscapes_713.prototxt';
fea_cha = 19;
base_size = 2048;
crop_size = 713;
data_class = 'objectName19.mat';
data_colormap = 'colormapcs.mat';
end
skipsize = 0; %skip serveal images in the list(此处设置为不跳过任何测试图片)
is_save_feat = false; %set to true if final feature map is needed (not suggested for storage consuming)是否保存特征数据
save_gray_folder = [save_root 'gray/']; %path for predicted gray image 预测图(灰度形式)保存路径
save_color_folder = [save_root 'color/']; %path for predicted color image 预测图(彩色图)保存路径
save_feat_folder = [save_root 'feat/']; %path for predicted feature map 预测特征图保持路径(实际上是数据,不是图)
scale_array = [1]; %set to [0.5 0.75 1 1.25 1.5 1.75] for multi-scale testing 即在多个尺寸在测试,这里设置为原尺寸
%训练阶段所使用的训练集RGB均值(减去均值可以提高训练速度)
mean_r = 123.68; %means to be subtracted and the given values are used in our training stage
mean_g = 116.779;
mean_b = 103.939;
acc = double.empty;
iou = double.empty;
gpu_id_array = [0:1]; %只有两块GPU,所以设置为0-1,修改此处后,记得修改参数'step'
runID = 1;
gpu_num = size(gpu_id_array,2);
index_array = [(runID-1)*gpu_num+1:runID*gpu_num]; %转化为Matlab的索引(Matlab的索引从1开始)
%parfor能够开启多个线程来并行循环,如果为单个GPU,则需将parfor改为串行的for
parfor i = 1:gpu_num
eval_sub(data_name,data_root,eval_list,model_weights,model_deploy,fea_cha,base_size,crop_size,data_class,data_colormap, ...
is_save_feat,save_gray_folder,save_color_folder,save_feat_folder,gpu_id_array(i),index_array(i),step,skipsize,scale_array,mean_r,mean_g,mean_b);
end
if(isVal)
eval_acc(data_name,data_root,eval_list,save_gray_folder,data_class,fea_cha); %调用eval_acc对验证集进行准确度和平均交并比的计算
endeval_all.m文件中最后几句中用到eval_sub()函数,此函数在eval_sub.m中,该函数的解读如下:
function eval_sub(data_name,data_root,eval_list,model_weights,model_deploy,fea_cha,base_size,crop_size,data_class,data_colormap, ...
is_save_feat,save_gray_folder,save_color_folder,save_feat_folder,gpu_id,index,step,skipsize,scale_array,mean_r,mean_g,mean_b)
list = importdata(fullfile(data_root,eval_list)); %fullfile相当于两个字符串连接
load(data_class); %加载类别(实际是每一种类别的名称,如airplane)
load(data_colormap); %加载调色板,加载后会存在对应的调色板变量名
if(~isdir(save_gray_folder)) %不存在则创建
mkdir(save_gray_folder);
end
if(~isdir(save_color_folder))
mkdir(save_color_folder);
end
if(~isdir(save_feat_folder) && is_save_feat)
mkdir(save_feat_folder);
end
phase = 'test'; %run with phase test (so that dropout isn't applied),test时不应用dropout
if ~exist(model_weights, 'file')
error('Model missing!');
end
caffe.reset_all();
caffe.set_mode_gpu();
caffe.set_device(gpu_id); %根据gpu_id启用相应的GPU
net = caffe.Net(model_deploy, model_weights, phase);
for i = skipsize+(index-1)*step+1:skipsize+index*step
fprintf(1, 'processing %d (%d)...\n', i, numel(list));
str = strsplit(list{i});
img = imread(fullfile(data_root,str{1}));
if(size(img,3) < 3) %for gray image 如果为灰度图,则扩展为三通道一样的图
im_r = img;
im_g = img;
im_b = img;
img = cat(3,im_r,im_g,im_b); %cat函数用于联接数组
end
ori_rows = size(img,1); %原始长
ori_cols = size(img,2); %原始宽
data_all = zeros(ori_rows,ori_cols,fea_cha,'single');
for j = 1:size(scale_array,2)
long_size = base_size*scale_array(j) + 1;
new_rows = long_size;
new_cols = long_size;
%归一化长和宽到设定的base_size
if ori_rows > ori_cols
new_cols = round(long_size/single(ori_rows)*ori_cols);
else
new_rows = round(long_size/single(ori_cols)*ori_rows);
end
img_scale = imresize(img,[new_rows new_cols],'bilinear'); %双线性插值调整图像大小
data_all = data_all + scale_process(net,img_scale,fea_cha,crop_size,ori_rows,ori_cols,mean_r,mean_g,mean_b);
end
data_all = data_all/size(scale_array,2);
data = data_all; %already exp process
img_fn = strsplit(str{1},'/'); %对图片路径按'/'切分(图片路径包含图片名字)
img_fn = img_fn{end}; %取最后一个字符串(实际上是图片名字,包含扩展名)
img_fn = img_fn(1:end-4); %去掉扩展名,只保留剩余下来的部分,例如/JPEGImages/2008_000006.jpg最后只保留2008_000006
%max(data,[],3)取出data中fea_cha层的最大值及其对应的标号(例如VOC2012有21个类,则最后的data有21层大小为
%[ori_rows,ori_cols]的预测值,选出每一个像素点所对应的21层中的最大预测值,其所对应的标号(也即类别)即为该像素点的归属)
[~,imPred] = max(data,[],3); %imPred保存每一个像素点所对应的类别
imPred = uint8(imPred); %转化为8位无符号整数
switch data_name
case 'ADE20K'
rgbPred = colorEncode(imPred, colors);
imwrite(imPred,[save_gray_folder img_fn '.png']);
imwrite(rgbPred,[save_color_folder img_fn '.png']);
case 'VOC2012'
imPred = imPred - 1; %VOC2010数据集的类别标号是0-20共21类,但imPred中的1对应VOC2012中的0(其余依次对应),故全减1
imwrite(imPred,[save_gray_folder img_fn '.png']);
imwrite(imPred,colormapvoc,[save_color_folder img_fn '.png']); %根据调色板colormapvoc进行上色,然后保存
case 'cityscapes'
imPred = imPred - 1;
imwrite(imPred,[save_gray_folder img_fn '.png']);
imwrite(imPred,colormapcs,[save_color_folder img_fn '.png']);
end
if(is_save_feat)
save([save_feat_folder img_fn],'data');
end
end
caffe.reset_all();
end其中的scale_process()函数在scale_process.m文件中,解读如下:
function data_output = scale_process(net,img_scale,fea_cha,crop_size,ori_rows,ori_cols,mean_r,mean_g,mean_b)
data_output = zeros(ori_rows,ori_cols,fea_cha,'single'); %创建数组,保存测试结果
new_rows = size(img_scale,1);
new_cols = size(img_scale,2);
long_size = new_rows;
short_size = new_cols;
if(new_cols > long_size)
long_size = new_cols;
short_size = new_rows;
end
if(long_size <= crop_size)
%利用pre_img()进行填充到和crop_size一样大小,再减去均值,并转化为caffe的blob存储格式
input_data = pre_img(img_scale,crop_size,mean_r,mean_g,mean_b);
score = caffe_process(input_data,net); %前向传播计算出预测值(预测值共21层)
score = score(1:new_rows,1:new_cols,:); %因为是在pre_img中是'post'后向填充,所以取[1:new_rows,1:new_cols,:]即可
else %当原始图片大小大于设定的裁剪图片大小(crop_size*crop_size)时,需要进行裁剪分块就行测试,最后合到一块儿
stride_rate = 2/3;
stride = ceil(crop_size*stride_rate); %裁剪步长
img_pad = img_scale;
if(short_size < crop_size) %如果长边大于crop_size,而短边小于crop_size,则需要对短边进行填充
if(new_rows < crop_size) %如果Height是短边,对Height进行填充(填充方法与pre_img中一致)
im_r = padarray(img_pad(:,:,1),[crop_size-new_rows,0],mean_r,'post');
im_g = padarray(img_pad(:,:,2),[crop_size-new_rows,0],mean_g,'post');
im_b = padarray(img_pad(:,:,3),[crop_size-new_rows,0],mean_b,'post');
img_pad = cat(3,im_r,im_g,im_b);
end
if(new_cols < crop_size) %如果Width是短边,对Width进行填充(填充方法与pre_img中一致)
im_r = padarray(img_pad(:,:,1),[0,crop_size-new_cols],mean_r,'post');
im_g = padarray(img_pad(:,:,2),[0,crop_size-new_cols],mean_g,'post');
im_b = padarray(img_pad(:,:,3),[0,crop_size-new_cols],mean_b,'post');
img_pad = cat(3,im_r,im_g,im_b);
end
end
pad_rows = size(img_pad,1);
pad_cols = size(img_pad,2);
h_grid = ceil(single(pad_rows-crop_size)/stride) + 1;
w_grid = ceil(single(pad_cols-crop_size)/stride) + 1;
data_scale = zeros(pad_rows,pad_cols,fea_cha,'single');
count_scale = zeros(pad_rows,pad_cols,fea_cha,'single');
%根据裁剪步长进行裁剪,从而前向传播计算预测值
for grid_yidx=1:h_grid
for grid_xidx=1:w_grid
s_x = (grid_xidx-1) * stride + 1; %裁剪起始坐标的x值(start_x)
s_y = (grid_yidx-1) * stride + 1; %裁剪起始坐标的y值(start_y)
e_x = min(s_x + crop_size - 1, pad_cols); %裁剪终止坐标的x值(end_x)
e_y = min(s_y + crop_size - 1, pad_rows); %裁剪终止坐标的y值(end_y)
s_x = e_x - crop_size + 1; %目的是使得最终裁剪出来的图像大小为crop_size*crop_size,故重新计算裁剪的起始坐标
s_y = e_y - crop_size + 1;
img_sub = img_pad(s_y:e_y,s_x:e_x,:); %进行裁剪
count_scale(s_y:e_y,s_x:e_x,:) = count_scale(s_y:e_y,s_x:e_x,:) + 1; %由于前后裁剪部分会有重叠,故要统计一下每一个像素点被测试了几次
input_data = pre_img(img_sub,crop_size,mean_r,mean_g,mean_b); %执行处理
data_scale(s_y:e_y,s_x:e_x,:) = data_scale(s_y:e_y,s_x:e_x,:) + caffe_process(input_data,net); %执行预测
end
end
score = data_scale./count_scale; %求出每个像素点预测均值
score = score(1:new_rows,1:new_cols,:); %因为是在pre_img中是'post'后向填充,所以取[1:new_rows,1:new_cols,:]即可
end
data_output = imresize(score,[ori_rows ori_cols],'bilinear'); %仍旧采用双线性插值返回到原图像大小
data_output = bsxfun(@rdivide, data_output, sum(data_output, 3)); %进行归一化,使得每个像素点的21个预测值之和为1(此句语句主要针对于长边大于crop_size的情况)
endscale_process()函数中所调用的pre_img(),caffe_process()函数的解读如下:
(1)pre_img()函数
function im_pad = pre_img(im,crop_size,mean_r,mean_g,mean_b)
row = size(im,1);
col = size(im,2);
im_pad = single(im); %转换为单精度
if(size(im_pad,3) < 3) %如果为灰度图,则转换为三通道一样的图
im_r = im_pad;
im_g = im_pad;
im_b = im_pad;
im_pad = cat(3,im_r,im_g,im_b);
end
if(row < crop_size)
%padarray是matlab中用于填充的函数,'post'是后向填充
%(即在最后一行后填充crop_size-row行,在最后一列后填充0列,填充数值为对应的均值mean_r/g/b)
im_r = padarray(im_pad(:,:,1),[crop_size-row,0],mean_r,'post');
im_g = padarray(im_pad(:,:,2),[crop_size-row,0],mean_g,'post');
im_b = padarray(im_pad(:,:,3),[crop_size-row,0],mean_b,'post');
im_pad = cat(3,im_r,im_g,im_b);
end
if(col < crop_size)
im_r = padarray(im_pad(:,:,1),[0,crop_size-col],mean_r,'post');
im_g = padarray(im_pad(:,:,2),[0,crop_size-col],mean_g,'post');
im_b = padarray(im_pad(:,:,3),[0,crop_size-col],mean_b,'post');
im_pad = cat(3,im_r,im_g,im_b);
end
im_mean = zeros(crop_size,crop_size,3,'single');
im_mean(:,:,1) = mean_r;
im_mean(:,:,2) = mean_g;
im_mean(:,:,3) = mean_b;
im_pad = single(im_pad) - im_mean; %减去均值
im_pad = im_pad(:,:,[3 2 1]); %从RGB转换为BGR存储(适应caffe的格式)
im_pad = permute(im_pad,[2 1 3]); %转置图像,即调换长和宽(也是适应caffe的存储格式)
%注:caffe中的Blob类型是(Width,Height,Channel,Number)格式存储
end
(2)caffe_process()函数
function score = ms_caffe_process(input_data,net)
score = net.forward({input_data}); %前向传播计算预测值
score = score{1};
score_flip = net.forward({input_data(end:-1:1,:,:)}); %end:-1:1表示从尾到头重新排列,实质是进行翻转,即按列翻转
score_flip = score_flip{1};
score = score + score_flip(end:-1:1,:,:);
score = permute(score, [2 1 3]); %恢复到原来的HeightxWidth格式
%逐元素计算指数值,由于所给的网络模型(例如pspnet101_VOC2012_473.prototxt)没有softmax层,
%由此手动计算softmax值,达到分类效果
%softmax计算公式pxi=exp(xi)/sum(exp(xi),i=1:21), i=1,2,...,21
score = exp(score);
score = bsxfun(@rdivide, score, sum(score, 3)); %bsxfun调用matlab和C的混编函数rdivide(即右除,也是逐元素的)
end以上过程中的图像裁剪思想如下:
PSPNet训练VOC2012时,采用的输入图像大小为固定的473*473,而VOC2012中的数据集本身大小并不固定,所以需要对小于473*473的图像进行补零填充;对大于473*473的图像进行裁剪,测试过程中的具体裁剪操作如下:
(1)当测试图像的长或宽或两者都小于473时,按下图进行补零填充(其中红色部分为原图,白色部分为补零填充部分,且是后向填充)
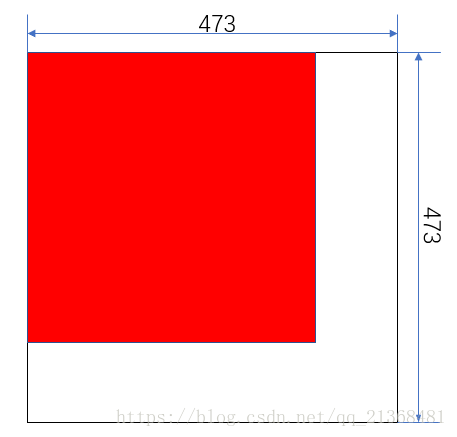
(2)当有一边大于473时,若另外一边小于473,则对这边进行后向补零填充(如下图);若另一边也大于473,则保持不变

在填充完的基础上需要对(2)中的情况进行裁剪,使得每一块都为标准的473*473大小,具体裁剪方法是将473*473的窗口进行滑动,依此取出图像上的每一部分,而滑动的步长由代码中的参数'stride'决定,且不足的回退直到大小为473*473,如下图所示(共裁剪出4块区域):
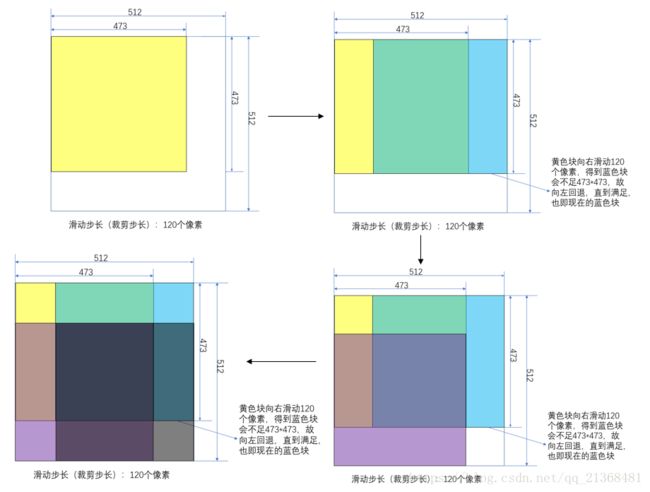
对每一块裁剪出的区域进行测试预测,重叠部分除以重叠次数(即上图中最中间的那块区域重叠了4次,故最后预测结果求和后除以4)。
2.执行测试及测试结果
打开终端,切换到run.sh文件所在的目录,输入以下语句执行测试:
./run.sh
执行过程如下(部分截图):
分割效果如下:
