李宏毅深度学习视频摘要
视频地址
李宏毅深度学习(nlp)2017
视频摘要
P1
讲了RNN,LSTM ,GRU网络构造
P2
讲了卷积的原理,pooling的原理,已经不太常规的poolling方法。另外提到一种特殊的Rnn结构stackRNN
P3
讲了深度学习反向传播的知识,其中提到链式法则,fc网络的bp方法和RNN的bp方法
P4
讲语言模型
n-gram : P(a|b)直接统计语料库的概率
nn-based-LM: P(a|b)由网络计算出来,其原理是matrix-factorization
RNN-based-LM: P(a|b,c)由网络计算出,RNN可以用前一次计算的隐状态,相比传统方法计算P(a|b,c)参数计算量更少。
P5
Spatial Transfromer Layer
主要思路是在图像进入CNN之前,先经过旋转和缩放操作,然后在进行识别。主要解决了cnn网络无法识别经过旋转和缩放的图像。(感觉好像random corp 也能部分解决)
该转换层仅仅需要6个参数,对图像的左边进行转换:
[ x b e f o r e y b e f o r e ] ∗ [ w 1 w 2 w 3 w 4 ] + [ b 1 b 2 ] = [ x a f t e r y a f t e r ] \begin{bmatrix}x_{before}\\ y_{before}\\\end{bmatrix}*\begin{bmatrix}w_1&w_2\\ w_3&w_4\\\end{bmatrix}+\begin{bmatrix}b_1\\ b_2\\\end{bmatrix}=\begin{bmatrix}x_{after}\\ y_{after}\\\end{bmatrix} [xbeforeybefore]∗[w1w3w2w4]+[b1b2]=[xafteryafter]
训练时通过下图方法将权重和loss联系起来,然后训练权重

P6
HighWay Network &Gird LSTM
HighWay Network的方式和ResNet的方式有点相似
Resnet的下一层输出可表示为:
L a y e r t + 1 = L a y t e r t + R E L U ( W 1 ∗ L a y t e r t ) Layer_{t+1}=Layter_t+RELU(W_1*Layter_t) Layert+1=Laytert+RELU(W1∗Laytert)
HighwayNet的下一层的输出可表示为:
H = ( W 1 ∗ L a y t e r t ) H=(W_1*Layter_t) H=(W1∗Laytert)
Z = s i g n m o d ( W 2 ∗ L a y t e r t ) Z=signmod (W_2*Layter_t) Z=signmod(W2∗Laytert)
L a y e r t + 1 = Z ⨀ L a y t e r t + ( 1 − Z ) ⨀ H Layer_{t+1}=Z\bigodot Layter_t+(1-Z)\bigodot H Layert+1=Z⨀Laytert+(1−Z)⨀H
Gird LSTM:
在多层LSTM网络中横向(时间方向)都会有hidden做为隐转态传递,作为短时记忆。纵向(深度方向)传递前一层LSTM的输出。
Gird LSTM 在纵向(深度方向)加了一个隐状态。使得多层LSTM见深度方向上也具备短时记忆。
P7
Recuesive Network 递归神经网络
主要思想是重复使用一个网络。

介绍了两种实现形式:
1.Recuesive Neural Tensor Network
2.Matrix-Vector Recuesive Network
区别是网络内部数据流动方式不一样。
P8
1.RNN生成模型
1.RNN直接生成一些文字内容。写诗机
2.RNN生成图片。(gird lstm的高级用法,考虑临近像素的相关性)
3.看图说话。CNN信息提取Vector,作为RNN的输入(隐状态),RNN输出文字
4.seq2seq。不同的是encoder的输出,多次的传给decoder(防止遗忘),而不是只在开头穿一次
5.多轮对话的RNN。多级RNN,多的那一级RNN用于处理每句话RNN输出vector,然后输出一个vector给Decoder
2.attention
attention 本质上做的事情就是为decoder筛选有用的输入信息.
1.在seq2seq中是在decoder的输入(hidden和input)考虑所有encoder的输出(hidden或output),具体方法就是乘某些可训练的权值
2.在看图说话中可以将图片划分成多个图,每个图通过CNN产生一个Vector,然后使用注意力来选择这些vector(加权求和之类的办法)
3.memory network
感觉和attention的有点像,被用来做阅读理解
4.neurl turning machine
在网络之外,维护一组vector(记忆),作为网络的部分输入,网络会输出一些控制,来修改这些记忆。
5.训练的track
attention训练应保持每次关注不同的元素,加一些正则化方法
seq2seq的训练,decoder输入可以 以一定概率选择前一次decoder的输出或者正确的标签。(scheduled samaling)
Beam Search:decoder的输出保留K个最可能的输出,下一时间输出K个,在k*N(词的个数)个输出中保留K个输出,最终选择一条最好的seq

整体最好与局部最好:局部最好的方法就是每个decoder的输出求交叉熵之和,整体最好就是所有decoder输出的整体与target seq的差异最小,后者使用了reinforcement learning
P9 (特别注意)
1.Point Network
seq2seq模型的attention变种,decoder 产生的序列是 encoder输入序列的子集。decoder的attention的权重直接argmax挑选出输入。
2.Point Network的拓展应用
Point Network 的输出,结合seq2seq的输出做文本摘要。
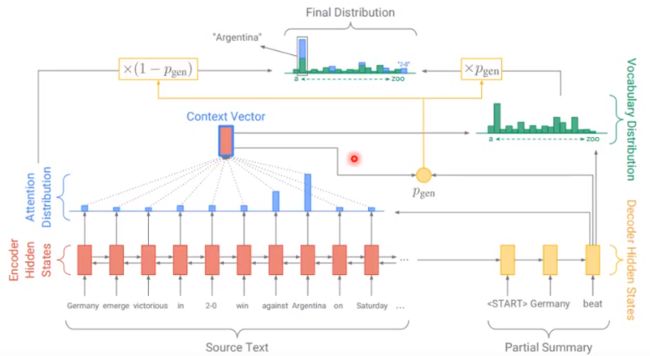
P10
Batch Normalization 在网络的隐含层中按批次做Normalization。具体方法: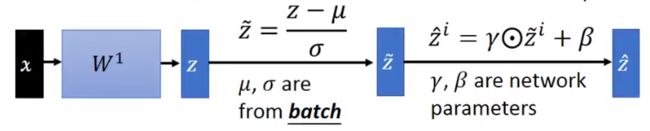
通常在激活层之前加BN。
由于 σ \sigma σ和 μ \mu μ需要一个batch。在predict时没有batch,只有单个样本。一种方法是记录训练时每轮的 σ \sigma σ和 μ \mu μ按照一定的权重加权平均。
Batch Normalization 的优点:
1.加快训练,可以使用较大的learnrate。(解决了 Internal Covariate Shift)
2.一定程度上缓解了梯度消失和爆照,特别是针对激活函数为signmod和tanh。(BN后输入的值落在0附近,梯度适中)
3.减少了训练结果和权重初始化的相关性。(w同乘k,BN后相当于没有乘)
4.一定程度上相当于进行的正则化,减少overfitting。(噪声被BN了)
P11
relu激活函数家族(大多数只是是<0的部分设置成一个负数)
其中一个特别的激活函数selu,在输入进行standardscale后(均值0,方差1),权重高斯分布初始化时。训练往往取得较好效果。

P12
capsule (胶囊网络)
单个神经元输入输出的不再是一个scalar(标量)而是一个vector(向量)。细胞内部部分权值更新部分依赖BP,部分靠迭代(像RNN)。
传统cnn可以检测到有没有某个pattern,而capsule自带了pattern之间的联系。
例如,是否有人脸:CNN,有鼻子眼睛就可以,capsule有鼻子眼睛还要位置合理才行

如何构建capsule网络参考:
https://blog.csdn.net/u013010889/article/details/78722140/
P13
超参选择:
- 网格搜索
- 随机搜索(效率高于网格搜索,如果只是要求选到比较好的超参,而不是最优超参)
- 用一个模型去学习超参和ACC之间的关系。(逻辑回归,RNN学习CNN的层数和卷积核大小和步长【RL】。RNN学习激活函数组合,还有learn_rate)
P14
- local minima 和 saddle point (优化时的问题)
- 网络巨大可以硬背输入数据。(但是网络并没有硬背,现阶段不知道为啥。)实验方法挺奇妙的。
- 用一个网络去学习另一个网络的输出(softmax),而非直接学习标签,效果比直接学好。(可以用于网络压缩,用小网络学大网络)
P15
- auto encoder
- Auto encoding variational bayes (VAE)
- GAN 的数学原理推导
- 实际使用时的方法化简后的数学方法
- conditionl GAN(text to image , image to image)
P16
- 回顾GAN的basc idea
- GAN损失函数的由来
- WGAN和改善的WGAN (修改了G和D的损失函数)
- conditionl GAN(text to image , image to image)(和前一节重复了)
P17
- 回顾seq2seq
- cha-bot中使用RL(policy gradient)训练。本质上讲传统方法训练是在求在训练集上的maxium-likehood,每个样本的权重都是1. 而在RL(policy gradient)训练时没有训练集,随机给一个可能的输入x,然后网络产生输出y,然后人给出R(x,y)分数。使R(x,y)为每个(x,y)的权重求maxium-likehood。
- R(x,y)不能全为正,需要使用R(x,y)-b。(b的确定方法没有讲)
- Alpha Go 式 RL训练方法, 不需要人给出R(x,y)。连个网络聊天,组成xy,然后自定义R(x,y)方法。(存疑)
- RL的其他方法:actor-critic
- seqGAN 可以看做 Generator 是seq2seq Discriminator和原本的GAN一样的GAN,也可以看做seq2seq +RL(Discriminator作为reward函数,只不过这个reward函数需要训练)。有一些训练时的track就是在reward的时候可以考虑将R(x,y)(对输入和输入整句)拆封成R(x,y1)+R(x,y2)…(对每个G产生的单词做)这样训练。
P18
三次元到二次元图转换(GAN+AutoEncoder+Classifer)
P19
Imiation Learning (模仿学习)
- Behavior Cloning (就是直接学习x,y)缺陷是expert 产生的(x,y)不能覆盖所有的出现的情况,可以做DataSet Aggregation。即actor在实际操作时产生expert 未产生的x时,expert 标出y,然后形成(x,y)放回训练
- Inverse Reinforcement Learning 。本质上是 structured learning(这个我也不知道,还需要去学习structured learning)。
IRL 在实际学习的时候 先随机一个reward 函数给 actor,actor 产生一组(x1,y1),expert产生(x,y),是的R(x,y)>R(x1,y1),更新R。重复。 - GAN for Imiation Learning :Discriminator expert 产生的数据(data) 和actor (Generator)产生的数据.
- Third Person Imiation Learning .主要是之前的都是 expert 和actor 的视角是一样的。Third Person就是机器观察人的动作去学习,用到了Domain Adversarial Train 的方法。(还不了解去百度)。
P22
Energy-base GAN:主要是修改了Discriminator的方案,原本gan只要求做二分类即可,现在要求real data通过D的值尽可能大,而其他所有的data 尽可能小(structured learning)的方法
1.EBGAN 。discriminator 变成auto encoder 。loss修改的比较奇妙。 另外可以要求G产生的图通过encoder产生的vector尽可能不同。 EBGAN 也可以看做auto encoder 的一种有效的训练方法。
2.BEGAN。 类似EBGAN loss 更奇妙,效果很好。