Multimodal Unsupervised Image-to-Image Translation论文翻译以及解读
Multimodal Unsupervised Image-to-Image Translation论文翻译以及解读
论文信息
论文题目:Multimodal Unsupervised Image-to-Image Translation
中文题目:多模态无监督图像转换
来源:ECCV 2018
论文地址1:
https://paperswithcode.com/paper/multimodal-unsupervised-image-to-image
论文地址2:http://openaccess.thecvf.com/content_ECCV_2018/papers/Xun_Huang_Multimodal_Unsupervised_Image-to-image_ECCV_2018_paper.pdf
论文简介
给定源域中的图像,如何在没有其他图像样本的情况下,学习相应目标域中对应图像的条件分布。
这种条件分布本质上是多模态的,但是现有的方法是在过度简化的假设条件下,通过绘制源域图像和确定的、一对一的目标图像来进行建模。因此,它们无法从给定的源域映像生成不同的输出图像。
为了解决这一局限性,本文提出了一种多模态无监督图像到图像的变换(MUNIT)框架。假设图像表征可以分解为一个具有域不变性的内容码和一个能刻画域特有性质的风格码。为了将图像转换到另一个域,将原图像的内容码和从目标域中随机抽取的某个风格码进行重组。建立相应的理论结果。
我对多模态分布的理解是,比如,在猫科动物的照片空间中,有普通家猫的照片,也有有大型猫科动物的照片,这两种照片是不同的分布,但同时在一个空间(猫科动物照片)中存在,让猫科动物的照片分布形成了一个多模态的分布。
前提假设
假设图像所在的潜在空间可以被分解为内容空间和风格空间
假设不同域直接共享内容空间的内容,但风格空间中的内容只被每个特定的域独有。即两个对应的图片对(x1,x2)是这样被生成的:x1=G1∗(c,s1),x2=G2∗(c,s2),其中c,s1,s2来自一些特定的分布,G1∗,G2∗是底层生成器。
假设G1∗和G2∗是确定性生成器,并且它们有相对的编码器E1∗=(G1∗)−1和E2∗=(G2∗)−1。目标就是通过神经网络学习到对应的底层生成器和编码器功能。值得注意的是虽然编码器和解码器是确定的,但是因为s2属于一个连续分布的关系,所以p(x2|x1)也是一个连续的分布。
假设内容码是一个有着复杂分布特性的高维空间地图,而风格码是一个符合高斯分布特性的低维向量。
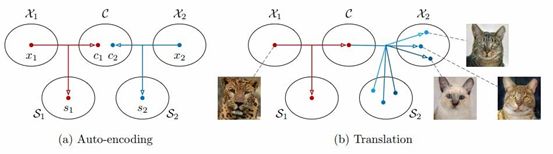
首先将每个域Xi中的图像进行编码后放入一个共享的内容空间C和特定域的风格空间Si,每个编码器还有逆向解码功能。
为了将某个X1中的图像(如猎豹)变换到 X2 中(如家猫),我们将输入图像的内容码和目标风格空间中的某个随机风格码进行重组。不同的风格码会得到不同的输出。
设x1∈x1, x2∈x2是来自两个不同图像域的图像。两个边缘分布为p(x1)和p(x2),联合分布p(x1, x2)。目标是用训练的模型p(x1→2|x1)和p(x2→1|x2)估计p(x1| x1)和p(x1|x2),其中x1→2是将x1翻译成X2得到的样本。
每个图像x∈X都是由两个域共享的内容码c∈C和特定于单个域的风格码si∈Si生成。来自联合分布的一对对应的图像(x1, x2)是由x1 = G∗1(c, s1)和x2 = G∗2(c, s2)生成的,其中c, s1, s2是来自于之前的分布,G∗1,G∗2是底层的生成器。
设计模型



Image-to-Image 转化模型由两个自动编码器组成,分别用红色和蓝色箭头表示,每个自编码器的隐编码由一个内容码 c 和一个风格码 s 构成。利用对抗目标(点线)和双向重建目标(短线)训练模型,其中对抗目标能保证转化的图像和目标域中真实图像难以区分,双向重建目标则用于同时重建图像和隐编码。
MUNIT的损失功能用来保证编码器和解码器互逆的双向重构损失和使翻译得到的图像服从真实图像分布的对抗损失,匹配翻译图像的分布到目标域中的图像分布。
通过image→latent→image这个过程得到前后两个image之间的L1 loss,以及通过latent→image→latent这个过程得到前后两个latent之间的L1 loss。
双向重构Loss
图像重构 (image →latent →image)
给定一个从数据分布中采样的图像,应该能够在编码和解码后重建它。
![]()
隐层重构 (latent →image →latent)
给定在翻译时从潜在分布中抽取的潜在代码(风格和内容),应该能够在解码和编码之后重构它。
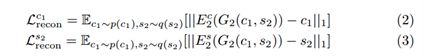
![]()
对抗 Loss
使用GANs来匹配迁移图像到目标数据分布的分布。换句话说,我们的模型生成的图像应该与目标域中的真实图像难以区分。
G是生成器,D是判别器。
![]()
其中D2是用来判别数据是属于X2还是迁移的。
Total Loss
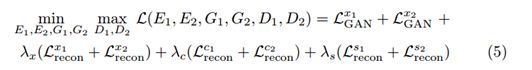
当最小化完成时,翻译分布(translated distribution)和数据分布(data distribution)是相匹配的。此时Eq. (5)变成了一个最大化方程:
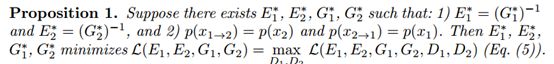
理论分析
隐编码分布匹配
现有的利用编码器和GAN来生成图像的模型要利用kld loss和gan loss来使解码器接受到的latent distribution和encoded latent distribution匹配。
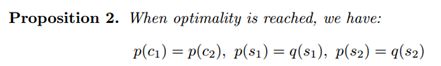

联合分布
联合分布p(x1,x1→2)和p(x2→1,x2)本质上就是联合分布p(x1,x2),是图像翻译成功的关键。
![]()
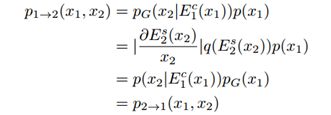
样式增强循环的一致性
限制条件对多模态图像转换过强了,可以证明如果引入了这个限制,这个模型会从一个概率分布模型变为一个输入与输出永远对应的生成模型。

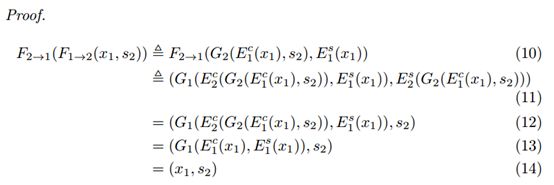
实验环境
代码库是使用软件包使用Anaconda开发的。
conda install pytorch=0.3 torchvision cuda80 -c pytorch;
conda install -y -c anaconda pip;
conda install -y -c anaconda pyyaml;
pip install tensorboard tensorboardX;
实验有两种运行环境,一是直接运行,二是使用tensorflow。
直接运行
- 运行以下命令将边缘转换为鞋子
python test.py --config configs/edges2shoes_folder.yaml --input inputs/edge.jpg --output_folder outputs --checkpoint models/edges2shoes.pt --a2b 1
- 可以使用示例鞋子图像来控制输出风格
python test.py --config configs/edges2shoes_folder.yaml --input inputs/edge.jpg --output_folder outputs --checkpoint models/edges2shoes.pt --a2b 1 --style inputs/shoe.jpg
- 下载数据集。
- 设置yaml文件。检查configs/edges2handbags_folder.yaml基于文件夹的数据集组织。将data_root字段更改为下载的数据集的路径。对于基于列表的数据集组织,请检查configs/edges2handbags_list.yaml。
- 开始训练
python train.py --config configs/edges2handbags_folder.yaml
- 中间图像输出和模型二进制文件存储在中 outputs/edges2handbags_folder
使用tensorflow
github代码tf版: https://github.com/taki0112/MUNIT-Tensorflow
代码:git clone https://github.com/taki0112/MUNIT-Tensorflow
实验环境:
tensorflow 1.4.0
python 3.5/ 3.6/ 3.7
准备:
cd MUNIT
mkdir dataset
cd dataset
mkdir my_dataset
文件结构:
MUNIT
├── dataset
└── my_dataset(name is designed by you)
├── trainA
├── xxx.jpg (name, format doesn't matter)
├── yyy.png
└── ...
├── trainB
├── zzz.jpg
├── www.png
└── ...
├── testA
├── aaa.jpg
├── bbb.png
└ ── ...
└── testB
├── ccc.jpg
├── ddd.png
└── ...
├── guide.jpg (example for guided image translation task)
开始训练:
python main.py --phase train --dataset my_dataset --batch_size 1
实验结果和分析
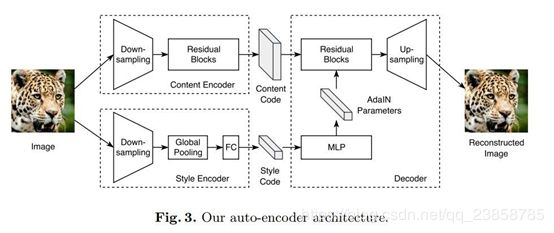
自编码器架由一个内容编码器、一个风格编码器和一个联合解码器组成。
内容编码器:由多个用于对输入降低采样的 Strided Convulsion 层和多个进一步处理输入的 Residual Block 组成,其中所有的 Convulsion 层都进行了 Instance Normalization 处理。
风格编码器:由多个 Strided Convulsion 层、一个全局的 Average Pooling 层和一个全连接(Fully Connected)层组成。
解码器:根据输入图像的内容码和风格码对其实现了重建。解码器通过一组 Residual Blocks 处理内容码,并最终利用多个上采样和 Convulsion 层来生成重建图像。在 Residual Block 中引入了自适应实例标准化(Adaptive Instance Normalization,AdaIN)层,AdaIN 层中的参数可以利用多层感知器(MLP)在风格码上动态生成:
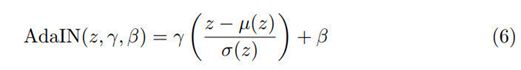
其中 z 是前一个卷积层产生的激活(Activation),µ 和 σ分别表示各个通道的均值和标准差,γ 和 β是 MLP 从风格码中生成的参数。
判别器:确保生成器同时生成了真实细节和正确的全局结构。
域不变性的感知损失(perceptual loss):通常,以输出图像和参考图像在 VGG特征空间中的距离作为感知损失,在有配对图像的监督数据中,这种方法可以有效地帮助 Image-to-Image 变换;但在无监督场景下,没有目标域中的参考图像。于是,在计算距离前,利用 Instance Normalization 处理VGG 特征,去除原始特征中包含大量域特定信息的均值和方差。
结果分析

线图鞋子变换的定性比较。第一列展示了输入和对应输出的真实图像。第二列开始每一列展示从某种方法中得到的 3 个随机的输出结果。

线图鞋子/手提包变换的定量分析。多样性得分使用的是 LPIPS 距离均值,质量评分使用的是「人类偏好得分」:人们相较于 MUNIT 更偏好该方法的百分比。两个指标中,都是数值越高表现越好。

例:(a)线图鞋子(b)线图手提包

动物形象的翻译。从3个类别/域收集图像,包括家猫、大猫和狗。每个域包含4种模式,它们是属于同一父类别的细粒度类别。
例:动物图像变换结果

动物图像变换的定量分析。这个数据集中共包含3个域,在任意两个域对之间完成双向变换,共6个变换目标。在每个目标上使用CIS和IS来度量表现效果。
为了获得高CIS/IS分数,模型需要生成高质量和多样化的样本。为所有输出图像的多样性度量,CIS为单个输入图像条件下输出的多样性度量,一个模型,确定地生成一个单一的输出给定一个输入图像将获得零CIS得分。
UNIT和CycleGAN产生的多样性非常小。
方法的IS值越高,说明它生成的图像质量也比基线方法高。
在动物图像平移数据集上进行的实验。模型成功地将一种动物转化为另一种动物。给定一个输入图像,其平移输出覆盖多个模式,即目标域中的多个细粒度动物类别。动物的形状已经发生了巨大的变化,但姿势却被完整地保留了下来。模型根据CIS和IS得到了最高的分数。基线都得到一个非常低的CIS。

示例:街景变换结果,包含不同季节、天气和光照条件下的图像
模型能够从给定的城市景观图像生成具有不同效果图的图像(例如,雨、雪、日落),并生成具有不同光照的城市景观图像。

示例:约塞米蒂国家公园的夏天冬天

示例:有引导图像变换。其中每一行内容相同,每一列风格相同

图 10. 现有风格变换方法的比较
结论
本文展示了一个多模态无监督的图像转换变框架,模型在输出图像的质量和多样性上都超过了现有的无监督方法,达到了和如今最先进的监督方法相当的结果。