Hive零基础从入门到实战 入门篇(十九) HiveQL:JOIN语句
目录
前言
1. 内连接 INNER JOIN
1.1 语法
1.2 举例
2. 外连接之 LEFT OUTER JOIN
2.1 语法
2.2 举例
2.2.1 多个结果做关联展示
2.2.2 从左表中去掉和右表有交集的部分
3. 外连接之 RIGHT OUTER JOIN
3.1 语法
4. 外连接之 FULL OUTER JOIN
4.1 语法
5. 总结
前言
本文介绍Hive中的JOIN语句,JOIN语句可以通过任意个字段关联对多个表进行列连接,有些类似于Excel中的vlookup函数,但功能更加强大,下面我们来详细介绍。
1. 内连接 INNER JOIN
1.1 语法
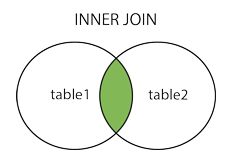
当两个表有一个或多个列内容有交集时,INNER JOIN会返回两个表关联上的列的所在行的所有列,有些绕,没看懂的初学者继续往后看,看完例子就懂了……
总之先记住,内连接返回关联的表的交集,如图:
语法如下:
SELECT a.列名
,b.列名
FROM 表名1 a
INNER JOIN 表名2 b
ON a.列名1 = b.列名1 [and a.列名2=b.列名2]...
[INNER JOIN 表名3 c
ON a.列名1 = c.列名1 [and a.列名2=c.列名2]...]
...
[WHERE ...
GROUP BY ...
ORDER BY ...];举个简单的例子:比如表1中有列A、B,表2中有列C、D,表1的A列和表2的C列有交集,内连接ON 表1.A=表2.C后,会返回A、B、C、D,其中所有返回的行都是A=C的。
注意:
- 用ON连接两个表内容有交集的列;
- 当有多个列时用and增加关联条件;
- 由于实际的表名都较长,所以一般会给关联的两个表起较为简单的别名,比如a、b、c等,这样后面在关联时可以用别名代替表名。否则需要写成ON 表名1.列名1 = 表名2.列名1这种格式;
- 只支持等值连接,即ON后面只能有等式,否则会报错;
- 可以进行任意个表的关联,在后面加JOIN即可;
- INNER关键字可以省略,JOIN等同于INNER JOIN;
- SELECT、WHERE、GROUP BY、ORDER BY等语句后的列名如果是一个表中独有的列名,可以不指定表名或表别名,即不加a.、b.,如果是两个表中都有的列名,则必须指定表名或表别名,否则会报错。不过我建议大家所有的列名都进行表名指定,这样一来防止报错,二来可以提高代码的可读性;
- 进行多表关联查询时最好给代码加注释,进一步提高代码可读性。
表名1和表名2的位置可以是子查询,语法如下:
SELECT a.列名
,b.列名
FROM (子查询1) a
INNER JOIN (子查询2) b
ON a.列名1 = b.列名1 [and a.列名2=b.列名2]...
[INNER JOIN (子查询3) c
ON a.列名1 = c.列名1 [and a.列名2=c.列名2]...]
...
[WHERE ...
GROUP BY ...
ORDER BY ...];复杂的关联语句强烈建议先用WITH AS 语句将a和b中的数据定义好,只选出自己要用的列,并且通过WHERE条件限定自己所需的行,然后再关联。因为JOIN是极其需要计算资源的操作,所以尽可能先让自己关联的表变小,这样可以有效提高运行效率和代码可读性,语法如下:
with a AS (查询1)
,b AS (查询2)
,c AS (查询3)
...
SELECT a.列名
,b.列名
FROM a
INNER JOIN b
ON a.列名1 = b.列名1 [and a.列名2=b.列名2]...
[INNER JOIN c
ON a.列名1 = c.列名1 [and a.列名2=c.列名2]...]
...
[WHERE ...
GROUP BY ...
ORDER BY ...];后面的举例会全使用WITH AS的形式,希望大家也能养成这种习惯。
1.2 举例
这里使用JOIN重构上一篇博客中的WHERE子查询操作
- 日期:20190101
- 当日新增且活跃用户数
展现形式:
平台 版本 用户数
脚本如下:
WITH a
AS (
--20190101的平台、版本、活跃用户id
SELECT platform
,app_version
,user_id
FROM app.t_od_use_cnt
WHERE date_8 = 20190101
AND is_active = 1
)
,b
AS (
--20190101的新增用户id
SELECT user_id
FROM app.t_od_new_user
WHERE date_8 = 20190101
)
--20190101的平台、版本、新增活跃用户数
SELECT a.platform
,a.app_version
,count(a.user_id) AS num
FROM a
INNER JOIN b
ON a.user_id = b.user_id
GROUP BY platform
,app_version;运行结果与使用WHERE子查询一致:
hive (app)> WITH a
> AS (
> --20190101的平台、版本、活跃用户id
> SELECT platform
> ,app_version
> ,user_id
> FROM app.t_od_use_cnt
> WHERE date_8 = 20190101
> AND is_active = 1
> )
> ,b
> AS (
> --20190101的新增用户id
> SELECT user_id
> FROM app.t_od_new_user
> WHERE date_8 = 20190101
> )
> --20190101的平台、版本、新增活跃用户数
> SELECT a.platform
> ,a.app_version
> ,count(a.user_id) AS num
> FROM a
> INNER JOIN b
> ON a.user_id = b.user_id
> GROUP BY platform
> ,app_version;
a.platform a.app_version num
1 1.1 24
1 1.2 21
1 1.3 25
1 1.4 21
1 1.5 25
2 1.1 19
2 1.2 18
2 1.3 15
2 1.4 20
2 1.5 18可以看到注释并不会影响脚本运行。
看到这里读者应该更深刻的理解了JOIN的作用,它的应用场景就是要取出两个表中的交集部分。
2. 外连接之 LEFT OUTER JOIN
2.1 语法
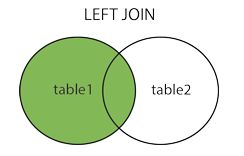
当两个表有一个或多个列内容有交集时,LEFT OUTER JOIN返回左表的全部行和右表满足ON条件的行,如果左表的行在右表中没有匹配,那么这一行右表中对应数据用NULL代替。也有些绕,没看懂的初学者继续往后看,看完例子就懂了……
总之先记住:LEFT JOIN产生表1的完全集,而2表中匹配的则有值,没有匹配的则以null值取代。关系如下图:
语法则和内连接完全一致,只是将INNER JOIN换成LEFT OUTER JOIN即可,其中OUTER同样可以省略,简写为LEFT JOIN。
with a AS (查询1)
,b AS (查询2)
,c AS (查询3)
...
SELECT a.列名
,b.列名
FROM a
LEFT JOIN b
ON a.列名1 = b.列名1 [and a.列名2=b.列名2]...
[LEFT JOIN c
ON a.列名1 = c.列名1 [and a.列名2=c.列名2]...]
...
[WHERE ...
GROUP BY ...
ORDER BY ...];2.2 举例
左关联有两种应用场景:
- 左表的数据范围大,要全部保留,右表的数据范围小,关联上就要,没关联上也没关系,多用于多个结果做关联展示;
- 要从左表中去掉和右表有交集的部分。
下面分别对这两种场景进行举例。
2.2.1 多个结果做关联展示
需求:
数据展现形式:日期、平台、版本、新用户数、重度活跃用户数(使用次数=50)
日期:20190101-20190102
脚本如下:
WITH a
AS (
--20190101-20190102的平台、版本、重度活跃用户数
SELECT date_8
,platform
,app_version
,count(DISTINCT user_id) AS active_num
FROM app.t_od_use_cnt
WHERE date_8 BETWEEN 20190101 AND 20190102
AND is_active = 1
AND use_cnt = 50
GROUP BY date_8
,platform
,app_version
)
,b
AS (
--20190101-20190102的新增用户数
SELECT date_8
,platform
,app_version
,count(DISTINCT user_id) AS new_user_num
FROM app.t_od_new_user
WHERE date_8 BETWEEN 20190101 AND 20190102
GROUP BY date_8
,platform
,app_version
)
--20190101-20190102的平台、版本、新增用户数、重度活跃用户数
SELECT b.date_8
,b.platform
,b.app_version
,b.new_user_num
,a.active_num
FROM b
LEFT JOIN a
ON a.date_8 = b.date_8
AND a.platform = b.platform
AND a.app_version = b.app_version
GROUP BY b.date_8
,b.platform
,b.app_version
,b.new_user_num
,a.active_num;这里新用户数每天每个平台每个版本一定都有数据,但重度活跃用户可能并不是每天每个平台每个版本都有,所以新用户数据范围大,作为左表,重度活跃用户数据范围小,作为右表,这样左关联后可以保证所有的数据都不会丢失。如果这里使用JOIN,那么新用户表就会损失一部分数据。
运行结果如下:
b.date_8 b.platform b.app_version b.new_user_num a.active_num
20190101 1 1.1 26 5
20190101 1 1.2 21 3
20190101 1 1.3 27 3
20190101 1 1.4 21 2
20190101 1 1.5 27 4
20190101 2 1.1 21 2
20190101 2 1.2 18 2
20190101 2 1.3 18 1
20190101 2 1.4 20 NULL
20190101 2 1.5 20 3
20190102 1 1.1 42 3
20190102 1 1.2 47 2
20190102 1 1.3 62 NULL
20190102 1 1.4 42 1
20190102 1 1.5 63 4
20190102 2 1.1 49 6
20190102 2 1.2 40 NULL
20190102 2 1.3 53 3
20190102 2 1.4 51 2
20190102 2 1.5 51 2可以看到活跃用户有三个数值为NULL。
2.2.2 从左表中去掉和右表有交集的部分
需求:
数据展现形式:日期、平台、老用户数(当日活跃用户去掉当日新增用户)
日期:20190101-20190102
脚本如下:
WITH a
AS (
--20190101-20190102的平台、活跃用户
SELECT date_8
,platform
,user_id
FROM app.t_od_use_cnt
WHERE date_8 BETWEEN 20190101 AND 20190102
AND is_active = 1
GROUP BY date_8
,platform
,user_id
)
,b
AS (
--20190101-20190103的平台、新增用户
SELECT date_8
,platform
,user_id
FROM app.t_od_new_user
WHERE date_8 BETWEEN 20190101 AND 20190102
GROUP BY date_8
,platform
,user_id
)
--20190101-20190102的平台、版本、老用户数(当日活跃用户去掉当日新增用户)
SELECT a.date_8
,a.platform
,count(distinct a.user_id) old_user_num
FROM a
LEFT JOIN b
ON a.date_8 = b.date_8
AND a.platform = b.platform
AND a.user_id = b.user_id
WHERE b.user_id is NULL
GROUP BY a.date_8
,a.platform;这个脚本逻辑的关键就是最后查询中的 WHERE b.user_id is NULL,因为是左关联,所以先取了左表的全部,这时用WHERE条件限定右表为空,也就是左右表没有关联上的部分。这样就实现了从左表中抛掉左右表重合部分的需求。
运行结果如下:
a.date_8 a.platform old_user_num
20190101 1 371
20190101 2 352
20190102 1 369
20190102 2 363
3. 外连接之 RIGHT OUTER JOIN
3.1 语法
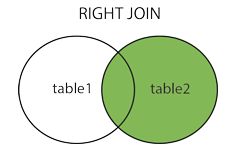
RIGHT OUTER JOIN返回右表的全部行和左表满足ON条件的行,如果右表的行在左表中没有匹配,那么这一行左表中对应数据用NULL代替。同样的OUTER在这里可以省略。其实说白了就是把LEFT JOIN的左表右表交换下顺序,然后换成RIGHT JOIN 。所以我个人习惯全都使用LEFT JOIN,RIGHT JOIN在工作中从来没有使用过。由于它的用法和LEFT JOIN完全一致,所以这里就不再举例了。
RIGHT JOIN产生表2的完全集,而1表中匹配的则有值,没有匹配的则以null值取代。关系如下图:
4. 外连接之 FULL OUTER JOIN
4.1 语法
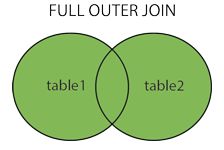
FULL OUTER JOIN 会从左表 和右表 那里返回所有的行。如果其中一个表的数据行在另一个表中没有匹配的行,那么对面的数据用NULL代替。同理,这里的OUTER 也可以省略。
FULL JOIN产生1和2的并集。但是需要注意的是,对于没有匹配的记录,则会以null做为值。
关系如下图:
不过老实说,我至今没有发现 FULL JOIN的应用场景,所以在工作中也从来没有用过……所以这里也就不举例了。
5. 总结
下面列出了四种JOIN 类型之间的差异:
- JOIN: 如果表中有至少一个匹配,则返回行;
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行;
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行;
- FULL JOIN: 只要其中一个表中存在匹配,就左表和右表所有的行返回行。
另外HIve中还有一种LEFT SEMI JOIN,作用是代替WHERE子查询,但由于JOIN可以实现同样的效果,所以在工作也从来都用不到,这里就不再详细介绍了,感兴趣的同学可以自行百度。
能看到这里的同学,就右上角点个赞顺便关注我吧,3Q~